其他常用优化操作
- 非连续转连续消除
由于底层实现的差异,GPU上可以只支持对于非连续的tensor进行操作而不会产生额外性能问题,对于NPU则需要插入非连续转连续算子。因此GPU上某些代码的写法会连续对一个非连续tensor操作,对NPU来说就会插入多余的转换算子造成性能下降。因此可以提前一把将非连续的tensor转连续,避免后续额外转换算子插入。
- 换轴reduce,换轴index
由于NPU上有些算子泛化性能较差,因此对于一些非尾轴reduce的算子以及一些非首轴的随机访存算子,优化有显著问题。此时可以先transpose做尾轴reduce或首轴随机访存,再transpose回来,可能性能更好。
- 亲和操作替换例如,将select转换为pointwise计算,将viewcopy转换为select等等。示例如下:
bboxes = torch.where(bboxes < min_xy, min_xy, bboxes) 可以换成 bboxes = torch.lerp(bboxes, min_xy, (bboxes < min_xy).float()) 可以用where assigned_gt_inds[pos_inds] = argmax_overlaps[pos_inds] + 1 assigned_gt_inds = torch.where(pos_inds, argmax_overlaps + 1, assigned_gt_inds) last_tags = tags[seq_ends, torch.arange(batch_size)]
- 使用NPU-Fast_GELU。GELU实现公式有很多,大致可以分为以下三个版本:
- Google-GELU,是PyTorch官方默认版本,NPU上没有对应的实现,这种实现性能也是最慢的(未证实)。
- OpenAI-GELU,也可以称作GPU的Fast_GELU,这个实现是Google-GELU的近似版本,PyTorch 2.0之后已支持,通过设置approximate='tanh'使能,实现比Google-GELU更快。当前NPU上默认是用这种实现的,所以说NPU的GELU等价于GPU的Fast_GELU,这种实现已经用于GPT训练,因此可以看作是业界主流。
- NPU-Fast_GELU,NPU的Fast_GELU是在OpenAI-GELU也就是GPU的Fast_GELU公式基础上,通过泰勒展开逼近得到的新公式,性能更快,同时在GPU上并没有对应的使用,有可能产生精度问题。
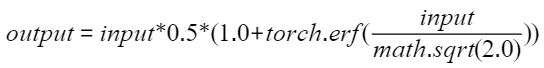
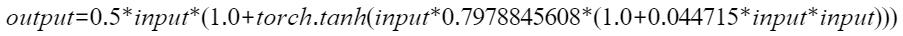
父主题: NPU亲和适配优化