SetNextTaskStart

本接口为试验接口,在后续版本中可能会调整或改进,不保证后续兼容性。请开发者在使用过程中关注后续版本更新。
产品支持情况
产品 |
是否支持 |
备注 |
|---|---|---|
√ |
该接口生效 |
|
√ |
仅保证编译兼容,实际功能不生效。 |
|
√ |
仅保证编译兼容,实际功能不生效。 |
|
√ |
仅保证编译兼容,实际功能不生效。 |
|
√ |
仅保证编译兼容,实际功能不生效。 |
|
√ |
仅保证编译兼容,实际功能不生效。 |
|
x |
- |
功能说明
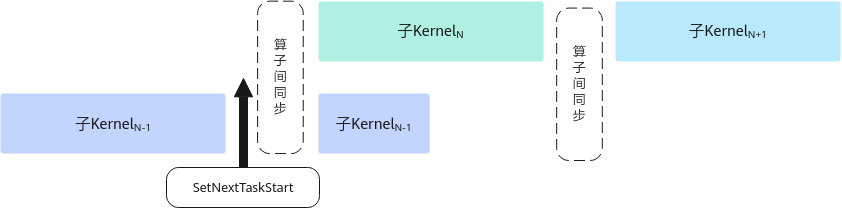
在SuperKernel的子Kernel中调用,调用后的指令可以和后续其他的子Kernel实现并行,提升整体性能。如图1所示,SuperKernel按序调用子Kernel,为保证子Kernel之间数据互不干扰,会在子Kernel间插入算子间同步进行保序,子KernelN-1调用该接口后,之后的指令会和后续子KernelN实现并行。
SuperKernel是一种算子的二进制融合技术,与源码融合不同,它聚焦于内核函数 (Kernel) 的二进制的调度方案,展开深度优化,于已编译的二进制代码基础上融合创建一个超级Kernel函数(SuperKernel),以调用子函数的方式调用多个其他内核函数,也就是子Kernel。相对于单算子下发,SuperKernel技术可以减少任务调度等待时间和调度开销,同时利用Task间隙资源进一步优化算子头开销。
开发者需要自行保证调用此接口后的指令不会与后序算子互相干扰而导致精度问题,推荐在整个算子最后一条搬运指令后调用此接口。
函数原型
- 该原型在如下产品型号支持:
Atlas 训练系列产品 1 2
template<pipe_t AIV_PIPE = PIPE_MTE3, pipe_t AIC_PIPE = PIPE_MTE3> __aicore__ inline void SetNextTaskStart()
参数说明
返回值
无
约束说明
调用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | #include "kernel_operator.h" class KernelEarlyStart { public: __aicore__ inline KernelEarlyStart() {} __aicore__ inline void Init(__gm__ uint8_t* src0Gm, __gm__ uint8_t* src1Gm, __gm__ uint8_t* dstGm) { src0Global.SetGlobalBuffer((__gm__ half*)src0Gm); src1Global.SetGlobalBuffer((__gm__ half*)src1Gm); dstGlobal.SetGlobalBuffer((__gm__ half*)dstGm); pipe.InitBuffer(inQueueSrc0, 1, 512 * sizeof(half)); pipe.InitBuffer(inQueueSrc1, 1, 512 * sizeof(half)); pipe.InitBuffer(outQueueDst, 1, 512 * sizeof(half)); } __aicore__ inline void Process() { CopyIn(); Compute(); CopyOut(); } private: __aicore__ inline void CopyIn() { AscendC::LocalTensor<half> src0Local = inQueueSrc0.AllocTensor<half>(); AscendC::LocalTensor<half> src1Local = inQueueSrc1.AllocTensor<half>(); AscendC::DataCopy(src0Local, src0Global, 512); AscendC::DataCopy(src1Local, src1Global, 512); inQueueSrc0.EnQue(src0Local); inQueueSrc1.EnQue(src1Local); } __aicore__ inline void Compute() { AscendC::LocalTensor<half> src0Local = inQueueSrc0.DeQue<half>(); AscendC::LocalTensor<half> src1Local = inQueueSrc1.DeQue<half>(); AscendC::LocalTensor<half> dstLocal = outQueueDst.AllocTensor<half>(); AscendC::Add(dstLocal, src0Local, src1Local, 512); outQueueDst.EnQue<half>(dstLocal); inQueueSrc0.FreeTensor(src0Local); inQueueSrc1.FreeTensor(src1Local); } __aicore__ inline void CopyOut() { AscendC::LocalTensor<half> dstLocal = outQueueDst.DeQue<half>(); AscendC::DataCopy(dstGlobal, dstLocal, 512); // 算子最后一条搬运指令后插入,且保证只调用一次 AscendC::SetNextTaskStart(); outQueueDst.FreeTensor(dstLocal); } private: AscendC::TPipe pipe; AscendC::TQue<AscendC::TPosition::VECIN, 1> inQueueSrc0, inQueueSrc1; AscendC::TQue<AscendC::TPosition::VECOUT, 1> outQueueDst; AscendC::GlobalTensor<half> src0Global, src1Global, dstGlobal; }; extern "C" __global__ __aicore__ void early_start_kernel(__gm__ uint8_t* src0Gm, __gm__ uint8_t* src1Gm, __gm__ uint8_t* dstGm) { KernelEarlyStart op; op.Init(src0Gm, src1Gm, dstGm); op.Process(); } |