尾块Tiling
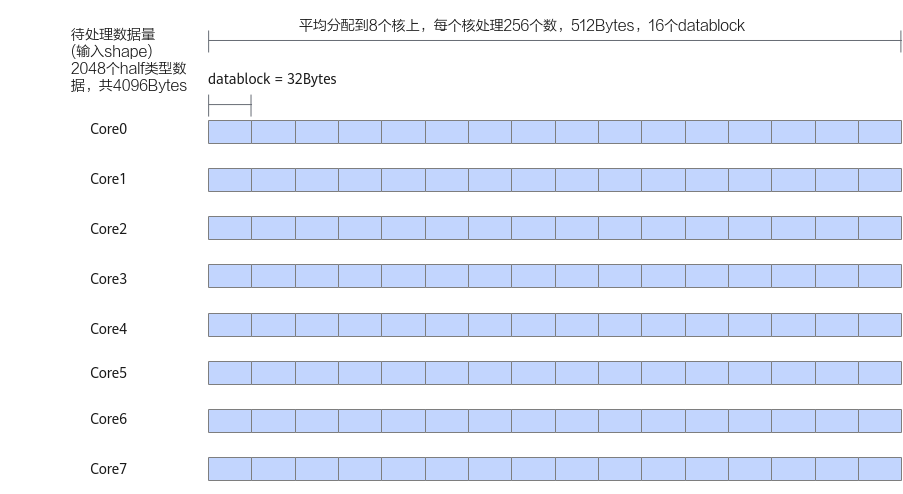
如下图中的示例,算子的输入shape为(1,2048),支持的数据类型为half类型,输入数据可以对齐到一个datablock的大小(32字节),输入数据为2048 * 2 / 32 = 128个datablock,因此可以平均分配到每个核上(假设使用8个核),每个核上处理256个数,16个datablock。此时不需要进行尾块处理。
针对一些shape,比如算子的输入shape为(1,1904),支持的数据类型为half类型,输入数据可以对齐到一个datablock的大小(32字节),可以平均分配到每个核上(假设使用8个核),每个核上处理238个数,238个数无法均分到datablock上,分满14个datablock后,剩余14个数(28字节),多核切分后需要进行尾块处理。
对于不同shape的输入进行数据切分时,可能会发生Tiling后的数据平均分配到多核上,但每个核内的数据无法均分的情况。针对此种场景,在Tiling参数中增加变量lastTileLength,用来表示最后一个分块,即尾块的大小。因此,在定义算子的Tiling结构体时包含以下四个成员:
- blockLength:每个核上计算的数据长度;
- tileNum:每个核上切分的数据块的个数;
- tileLength:每个核上除尾块外,每个数据块的长度;
- lastTileLength:每个核上尾块的长度。其中,当lastTileLength等于tileLength时,为核间均分同时核内均分场景,因此这两种场景可以做代码归一化处理。

Tiling实现
算子的Tiling结构体定义如下:
1 2 3 4 5 6 |
struct AddCustomTilingData { uint32_t blockLength; uint32_t tileNum; uint32_t tileLength; uint32_t lastTileLength; }; |
Host侧Tiling实现的主要内容为计算以上四个成员变量。步骤如下:
- 判断数据总长度totalLength是否满足32字节对齐,如不满足,则计算totalLength向上32字节对齐后的长度totalLengthAligned。
1 2 3 4 5 6
constexpr uint32_t BLOCK_SIZE = 32; // 为方便计算,这里根据数据类型定义变量alignNum作为对齐数 uint32_t alignNum = BLOCK_SIZE / dataTypeSize; // totalLength为数据总量 uint32_t totalLengthAligned = (totalLength % alignNum == 0)? totalLength : ((totalLength + alignNum - 1) / alignNum) * alignNum;
- 判断totalLengthAligned是否能被使用的核数BlockDim均分,如果可以,则计算每个核上计算数据长度blockLength。
1 2 3 4 5 6
constexpr uint32_t BLOCK_DIM = 8; constexpr uint32_t UB_BLOCK_NUM = 20; // 此处为方便验证,使用UB_BLOCK_NUM作为Unified Buffer可用的Block数量,因此可得出可用UB空间的大小为UB_BLOCK_NUM * BLOCK_SIZE uint32_t blockLength, tileNum; if (totalLengthAligned % BLOCK_DIM == 0) { blockLength = totalLengthAligned / BLOCK_DIM; }
- 计算tileNum。为了减少数据搬运开销,应尽量使用核内的Unified Buffer空间。基于每个核上的计算量以及可用Unified Buffer空间的大小,计算tileNum。
1tileNum = blockLength / alignNum / UB_BLOCK_NUM;
- 根据计算出的tileNum,计算tileLength和lastTileLength。
如果每个核的计算量能够被当前可用Unified Buffer空间均分,或者计算量小于可用Unified Buffer空间,则按照无尾块场景处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// (blockLength / alignNum) % UB_BLOCK_NUM为0,表示每个核的计算量能够被当前可用Unified Buffer空间均分 // tileNum为0,表示计算量小于可用Unified Buffer空间 if ((blockLength / alignNum) % UB_BLOCK_NUM == 0 || tileNum == 0) { if (tileNum == 0) { tileNum = 1; } if (blockLength < UB_BLOCK_NUM * alignNum) { tileLength = ((blockLength + alignNum - 1) / alignNum) * alignNum; lastTileLength = tileLength; } else { tileLength = UB_BLOCK_NUM * alignNum; lastTileLength = tileLength; } }
反之,按照尾块场景处理,在tileNum上加1作为每个核的数据块个数,尾块长度为单核计算数据长度 - (tileNum - 1) * tileLength。
1 2 3 4 5
else { tileNum = tileNum + 1; tileLength = UB_BLOCK_NUM * alignNum; lastTileLength = blockLength - (tileNum - 1) * tileLength; }
Host侧Tiling实现的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
constexpr uint32_t BLOCK_SIZE = 32; constexpr uint32_t BLOCK_DIM = 8; constexpr uint32_t UB_BLOCK_NUM = 20; // 此处为方便验证,使用UB_BLOCK_NUM作为UB可用的Block数量,因此可得出可用UB空间的大小为UB_BLOCK_NUM * BLOCK_SIZE ... uint32_t alignNum = BLOCK_SIZE / dataTypeSize; // 为方便计算,这里根据数据类型定义变量alignNum作为对齐数,dataTypeSize为运算数据的数据类型对应的字节数 // totalLength为数据总量 uint32_t totalLengthAligned = (totalLength % alignNum == 0)? totalLength : ((totalLength + alignNum - 1) / alignNum) * alignNum; uint32_t blockLength, tileNum; if (totalLengthAligned % BLOCK_DIM == 0) { blockLength = totalLengthAligned / BLOCK_DIM; tileNum = blockLength / alignNum / UB_BLOCK_NUM; if ((blockLength / alignNum) % UB_BLOCK_NUM == 0 || tileNum == 0) { if (tileNum == 0) { tileNum = 1; } if (blockLength < UB_BLOCK_NUM * alignNum) { tileLength = ((blockLength / alignNum) + 1) * alignNum; lastTileLength = tileLength; } else { tileLength = UB_BLOCK_NUM * alignNum; lastTileLength = tileLength; } } else { tileNum = tileNum + 1; tileLength = UB_BLOCK_NUM * alignNum; lastTileLength = blockLength - (tileNum - 1) * tileLength; } ... } |
算子类实现
由于尾块长度为lastTileLength,与其它数据块的长度不同,因此CopyIn函数、CopyOut函数需要对尾块单独处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
__aicore__ inline void CopyIn(int32_t progress) { AscendC::LocalTensor<dataType> xLocal = inQueueX.AllocTensor<dataType>(); AscendC::LocalTensor<dataType> yLocal = inQueueY.AllocTensor<dataType>(); if (progress == (this->tileNum - 1)) { AscendC::DataCopy(xLocal, xGm[progress * this->tileLength], this->lastTileLength); AscendC::DataCopy(yLocal, yGm[progress * this->tileLength], this->lastTileLength); } else { AscendC::DataCopy(xLocal, xGm[progress * this->tileLength], this->tileLength); AscendC::DataCopy(yLocal, yGm[progress * this->tileLength], this->tileLength); } inQueueX.EnQue(xLocal); inQueueY.EnQue(yLocal); } |
1 2 3 4 5 6 7 8 9 10 11 |
__aicore__ inline void CopyOut(int32_t progress) { AscendC::LocalTensor<dataType> zLocal = outQueueZ.DeQue<dataType>(); if (progress == (this->tileNum - 1)) { AscendC::DataCopy(zGm[progress * this->tileLength], this->lastTileLength); } else { AscendC::DataCopy(zGm[progress * this->tileLength], zLocal, this->tileLength); } outQueueZ.FreeTensor(zLocal); } |