较小矩阵长驻L1 Buffer,仅分次搬运较大矩阵
【优先级】高
【描述】在进行cube计算时,当L1无法全载左右矩阵时,可以让较小的矩阵长驻于L1上,只分次搬运较大的矩阵,减少搬运次数。
【反例】
假设L1的大小为512K,左矩阵和右矩阵的大小分别为992K、16K,数据类型为half,单次无法将左右矩阵全部载入L1中。开发者规划的切分策略为:不切K轴,将左矩阵平均分成两块A1、A2,shape大小均为[992, 256];将右矩阵平均分成两块,shape大小均为[256, 16]。计算时的加载顺序如下:先加载A1矩阵至L1,将B1、B2依次加载并计算;然后再加载A2至L1,将B1、B2依次加载并计算。
图1 反例切分策略图示
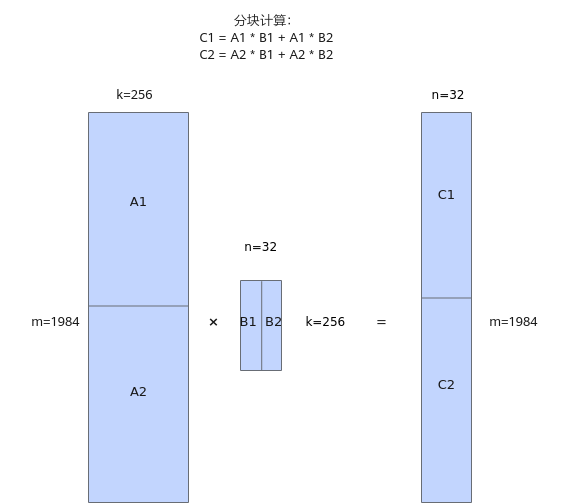
...
public:
__aicore__ inline KernelSample()
{
aSize = baseM * baseK;
bSize = baseK * baseN;
cSize = m * n;
}
__aicore__ inline void Init(__gm__ uint8_t *a, __gm__ uint8_t *b, __gm__ uint8_t *c)
{
aGM.SetGlobalBuffer((__gm__ half *)a);
bGM.SetGlobalBuffer((__gm__ half *)b);
cGM.SetGlobalBuffer((__gm__ float *)c);
pipe.InitBuffer(inQueueA1, 1, aSize * sizeof(half));
pipe.InitBuffer(inQueueA2, 1, aSize * sizeof(half));
pipe.InitBuffer(inQueueB1, 1, bSize * sizeof(half));
pipe.InitBuffer(inQueueB2, 2, bSize * sizeof(half));
pipe.InitBuffer(outQueueCO1, 1, cSize * sizeof(float));
}
__aicore__ inline void Process()
{
for (uint32_t i = 0; i < 2; i++) {
CopyInA1(i);
SplitA();
for (uint32_t j = 0; j < 2; j++) {
CopyInB1(j);
SplitB();
Compute(i, j);
}
}
CopyOut();
}
private:
__aicore__ inline void CopyInA1(uint32_t i)
{
LocalTensor<half> a1Local = inQueueA1.AllocTensor<half>();
// 左矩阵a1/a2分块载入A1
Nd2NzParams dataCopyA1Params;
dataCopyA1Params.ndNum = 1;
dataCopyA1Params.nValue = baseM;
dataCopyA1Params.dValue = baseK;
dataCopyA1Params.srcNdMatrixStride = 0;
dataCopyA1Params.srcDValue = baseK;
dataCopyA1Params.dstNzC0Stride = baseM;
dataCopyA1Params.dstNzNStride = 1;
dataCopyA1Params.dstNzMatrixStride = 0;
DataCopy(a1Local, aGM[i * baseM * baseK], dataCopyA1Params);
inQueueA1.EnQue(a1Local);
}
__aicore__ inline void SplitA()
{
LocalTensor<half> a1Local = inQueueA1.DeQue<half>();
LocalTensor<half> a2Local = inQueueA2.AllocTensor<half>();
// 左矩阵a1/a2分块从A1->A2
LoadData2dParams loadL0AParams;
loadL0AParams.repeatTimes = baseM * baseK * sizeof(half) / 512;
loadL0AParams.srcStride = 1;
loadL0AParams.dstGap = 0;
LoadData(a2Local, a1Local, loadL0AParams);
inQueueA2.EnQue(a2Local);
inQueueA1.FreeTensor(a1Local);
}
__aicore__ inline void CopyInB1(uint32_t j)
{
LocalTensor<half> b1Local = inQueueB1.AllocTensor<half>();
// 右矩阵分块b1/b2载入B1
Nd2NzParams dataCopyB1Params;
dataCopyB1Params.ndNum = 1;
dataCopyB1Params.nValue = baseK;
dataCopyB1Params.dValue = baseN;
dataCopyB1Params.srcNdMatrixStride = 0;
dataCopyB1Params.srcDValue = n;
dataCopyB1Params.dstNzC0Stride = baseK;
dataCopyB1Params.dstNzNStride = 1;
dataCopyB1Params.dstNzMatrixStride = 0;
DataCopy(b1Local, bGM[j * baseN], dataCopyB1Params);
inQueueB1.EnQue(b1Local);
}
__aicore__ inline void SplitB()
{
LocalTensor<half> b1Local = inQueueB1.DeQue<half>();
LocalTensor<half> b2Local = inQueueB2.AllocTensor<half>();
// 右矩阵分块b1/b2从B1->B2
LoadData2dTransposeParams loadL0BParams;
loadL0BParams.startIndex = 0;
loadL0BParams.repeatTimes = baseK / nBlockSize;
loadL0BParams.srcStride = 1;
loadL0BParams.dstGap = 1;
LoadDataWithTranspose(b2Local, b1Local, loadL0BParams);
inQueueB2.EnQue(b2Local);
inQueueB1.FreeTensor(b1Local);
}
__aicore__ inline void Compute(uint32_t i, uint32_t j)
{
LocalTensor<half> a2Local = inQueueA2.DeQue<half>();
LocalTensor<half> b2Local = inQueueB2.DeQue<half>();
LocalTensor<float> c1Local = outQueueCO1.AllocTensor<float>();
// 矩阵乘
mmadParams.m = baseM;
mmadParams.n = baseN;
mmadParams.k = baseK;
Mmad(c1Local[i * baseM * baseN + j * m * baseN], a2Local, b2Local, mmadParams);
outQueueCO1.EnQue<float>(c1Local);
inQueueA2.FreeTensor(a2Local);
inQueueB2.FreeTensor(b2Local);
}
__aicore__ inline void CopyOut()
{
...
}
private:
TPipe pipe;
TQue<QuePosition::A1, 1> inQueueA1;
TQue<QuePosition::A2, 1> inQueueA2;
TQue<QuePosition::B1, 1> inQueueB1;
TQue<QuePosition::B2, 1> inQueueB2;
TQue<QuePosition::CO1, 1> outQueueCO1;
GlobalTensor<half> aGM;
GlobalTensor<half> bGM;
GlobalTensor<dst_T> cGM;
uint16_t m = 1984, k = 256, n = 32;
uint16_t baseM = 992, baseK = 256, baseN = 16;
uint16_t aSize, bSize, cSize;
uint16_t nBlockSize = 16;
...
【正例】
该示例中,将较小的右矩阵一次性搬入L1并长存于L1上,循环内不断搬运A矩阵,当循环次数为2时,共需要3次搬运。
...
public:
__aicore__ inline KernelSample()
{
aSize = baseM * baseK;
bSize = baseK * n;
cSize = m * n;
}
__aicore__ inline void Init(__gm__ uint8_t *a, __gm__ uint8_t *b, __gm__ uint8_t *c)
{
aGM.SetGlobalBuffer((__gm__ half *)a);
bGM.SetGlobalBuffer((__gm__ half *)b);
cGM.SetGlobalBuffer((__gm__ float *)c);
pipe.InitBuffer(inQueueA1, 1, aSize * sizeof(half));
pipe.InitBuffer(inQueueA2, 1, aSize * sizeof(half));
pipe.InitBuffer(inQueueB1, 1, bSize * sizeof(half));
pipe.InitBuffer(inQueueB2, 2, bSize * sizeof(half));
pipe.InitBuffer(outQueueCO1, 1, cSize * sizeof(float));
}
__aicore__ inline void Process()
{
CopyInB1();
SplitB();
for (uint32_t i = 0; i < 2; i++) {
CopyInA1(i);
SplitA();
for (uint32_t j = 0; j < 2; j++) {
Compute(i, j);
}
}
CopyOut();
}
private:
__aicore__ inline void CopyInB1()
{
LocalTensor<half> b1Local = inQueueB1.AllocTensor<half>();
// 右矩阵全载入B1
Nd2NzParams dataCopyB1Params;
dataCopyB1Params.ndNum = 1;
dataCopyB1Params.nValue = baseK;
dataCopyB1Params.dValue = n;
dataCopyB1Params.srcNdMatrixStride = 0;
dataCopyB1Params.srcDValue = n;
dataCopyB1Params.dstNzC0Stride = baseK;
dataCopyB1Params.dstNzNStride = 1;
dataCopyB1Params.dstNzMatrixStride = 0;
DataCopy(b1Local, bGM, dataCopyB1Params);
inQueueB1.EnQue(b1Local);
}
__aicore__ inline void SplitB()
{
LocalTensor<half> b1Local = inQueueB1.DeQue<half>();
LocalTensor<half> b2Local = inQueueB2.AllocTensor<half>();
// 右矩阵全部从B1->B2
LoadData2dTransposeParams loadL0BParams;
loadL0BParams.startIndex = 0;
loadL0BParams.repeatTimes = baseK / nBlockSize;
loadL0BParams.srcStride = 1;
loadL0BParams.dstGap = 1;
for (int blockNum = 0; blockNum < (n / nBlockSize); blockNum++) {
LoadDataWithTranspose(b2Local[blockNum * 16 * nBlockSize], b1Local[blockNum * baseK * nBlockSize], loadL0BParams);
}
inQueueB2.EnQue(b2Local);
inQueueB1.FreeTensor(b1Local);
}
__aicore__ inline void CopyInA1(uint32_t i)
{
LocalTensor<half> a1Local = inQueueA1.AllocTensor<half>();
// 左矩阵a1/a2分块载入A1
Nd2NzParams dataCopyA1Params;
dataCopyA1Params.ndNum = 1;
dataCopyA1Params.nValue = baseM;
dataCopyA1Params.dValue = baseK;
dataCopyA1Params.srcNdMatrixStride = 0;
dataCopyA1Params.srcDValue = baseK;
dataCopyA1Params.dstNzC0Stride = baseM;
dataCopyA1Params.dstNzNStride = 1;
dataCopyA1Params.dstNzMatrixStride = 0;
DataCopy(a1Local, aGM[i * baseM * baseK], dataCopyA1Params);
inQueueA1.EnQue(a1Local);
}
__aicore__ inline void SplitA()
{
LocalTensor<half> a1Local = inQueueA1.DeQue<half>();
LocalTensor<half> a2Local = inQueueA2.AllocTensor<half>();
// 左矩阵a1/a2分块从A1->A2
LoadData2dParams loadL0AParams;
loadL0AParams.repeatTimes = baseM * baseK * sizeof(half) / 512;
loadL0AParams.srcStride = 1;
loadL0AParams.dstGap = 0;
LoadData(a2Local, a1Local, loadL0AParams);
inQueueA2.EnQue(a2Local);
inQueueA1.FreeTensor(a1Local);
}
__aicore__ inline void Compute(uint32_t i, uint32_t j)
{
LocalTensor<half> a2Local = inQueueA2.DeQue<half>();
LocalTensor<half> b2Local = inQueueB2.DeQue<half>();
LocalTensor<float> c1Local = outQueueCO1.AllocTensor<float>();
// 矩阵乘
mmadParams.m = baseM;
mmadParams.n = baseN;
mmadParams.k = baseK;
Mmad(c1Local[i * baseM * baseN + j * m * baseN], a2Local, b2Local, mmadParams);
outQueueCO1.EnQue<float>(c1Local);
inQueueA2.FreeTensor(a2Local);
inQueueB2.FreeTensor(b2Local);
}
__aicore__ inline void CopyOut()
{
...
}
private:
TPipe pipe;
TQue<QuePosition::A1, 1> inQueueA1;
TQue<QuePosition::A2, 1> inQueueA2;
TQue<QuePosition::B1, 1> inQueueB1;
TQue<QuePosition::B2, 1> inQueueB2;
TQue<QuePosition::CO1, 1> outQueueCO1;
GlobalTensor<half> aGM;
GlobalTensor<half> bGM;
GlobalTensor<dst_T> cGM;
uint16_t m = 1984, k = 256, n = 32;
uint16_t baseM = 992, baseK = 256, baseN = 16;
uint16_t aSize, bSize, cSize;
uint16_t nBlockSize = 16;
...
父主题: 内存优化