PyTorch Profiling接口采集
前提条件
准备好基于PyTorch 1.8.1或1.11.0开发的训练模型以及配套的数据集,并按照《PyTorch模型迁移和训练指南》中的“迁移适配”完成PyTorch原始模型向昇腾AI处理器的迁移。
采集性能数据
使用Profiling接口对原始代码的loss计算和优化过程进行改造。
# 使用ascend-pytorch适配的Profiling接口,推荐只运行一个step
with torch.autograd.profiler.profile(use_npu=True) as prof:
out = model(input_tensor)
loss=loss_func(out)
loss.backward()
optimizer.zero_grad()
optimizer.step()
# 打印Profiling结果信息
print(prof)
# 导出chrome_trace文件到指定路径
output_path = '/home/HwHiAiUser/profile_data.json'
prof.export_chrome_trace(output_path)
为保证数据的准确性,进行prof操作建议运行超过10个step,第10个step后的性能数据较为准确。
完成采集后生成profile_data.json文件,详细介绍请参见查看profiling数据。
查看profiling数据
在Chrome浏览器中输入“chrome://tracing”地址,将profile_data.json文件拖到空白处打开,通过键盘上的快捷键(w:放大,s:缩小,a:左移,d:右移)进行查看,如图1所示。
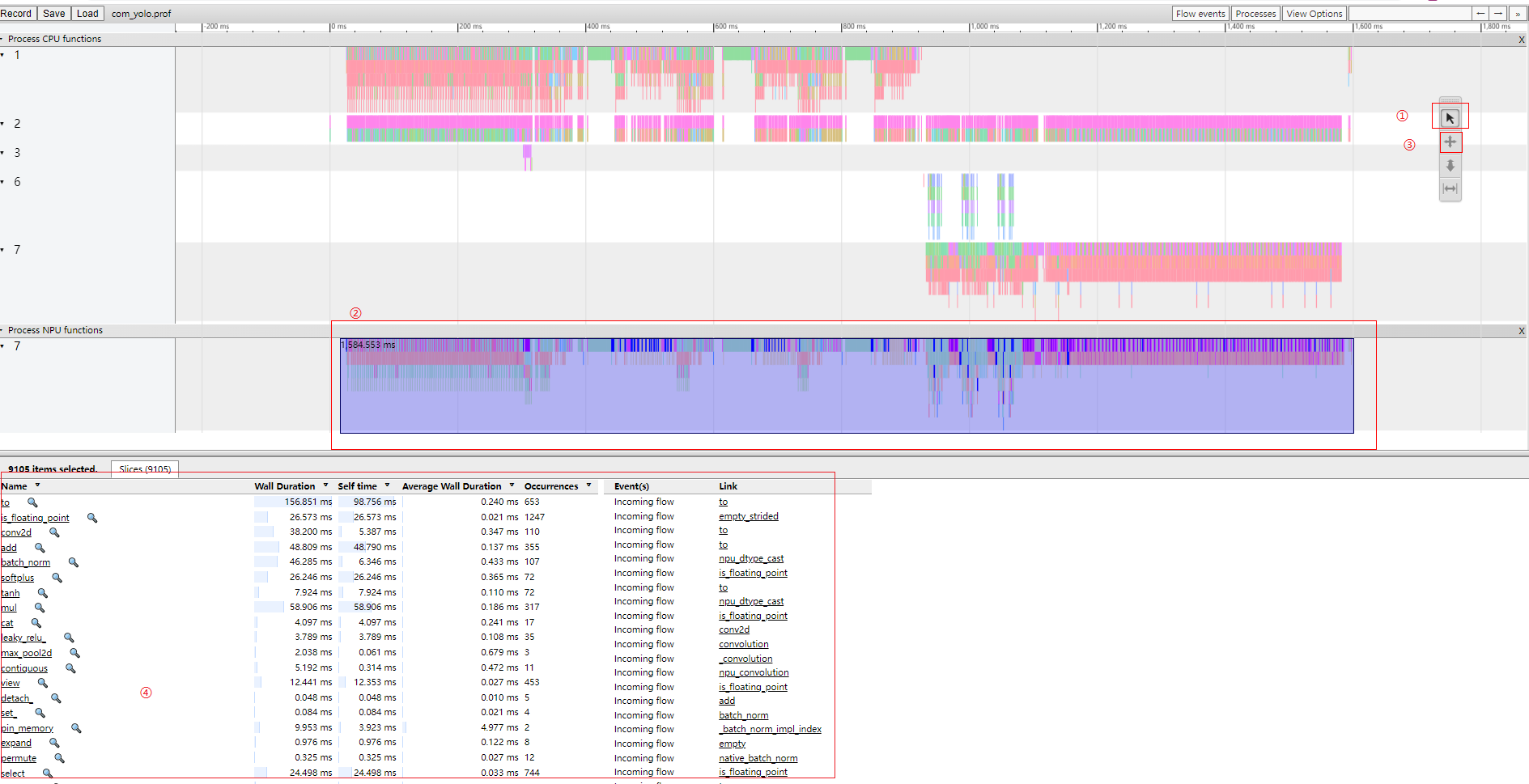
具体性能数据分析步骤如下:
- 单击图片中①所示
 按钮。
按钮。 - 框选图片中②(用户所需数据)所示timeline数据。
- 单击图片中③所示
 按钮,详细数据信息如④所示。
按钮,详细数据信息如④所示。 - 根据④中selftime数据从大到小排序,可找出TopN耗时算子信息,分析模型中存在的性能问题。
其他功能
PyTorch Profiling其他功能。
- 获取算子输入tensor的shape信息。
# 添加record_shapes参数,获取算子输入tensor的shape信息 with torch.autograd.profiler.profile(use_npu=True, record_shapes=True) as prof: # 添加模型计算过程 print(prof)打印结果中增加了每个算子的Input Shape信息。
- 获取使用NPU的内存信息。
# 添加Profiling参数,获取算子内存占用信息 with torch.autograd.profiler.profile(use_npu=True, profile_memory=True) as prof: # 添加模型计算过程 print(prof)打印结果中增加了每个算子的CPU Mem、Self CPU Mem、NPU Mem、Self NPU Mem信息。

该功能仅支持PyTorch 1.8.1版本以上。
- 获取简洁的算子性能信息。
该功能只打印每个算子栈最底层的算子信息,使分析结果更简洁。
# 添加use_npu_simple参数,获取简洁的算子信息 with torch.autograd.profiler.profile(use_npu=True, use_npu_simple=True) as prof: # 添加模型计算过程 output_path = '/home/HwHiAiUser/profile_data.json' # 导出chrome_trace文件到指定路径 prof.export_chrome_trace(output_path)
在Chrome浏览器中打开chrome_trace结果文件,可查看简洁的算子性能信息。
父主题: 使用PyTorch框架接口采集