vec_reduce_max
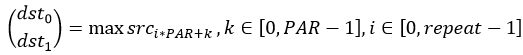
函数原型
vec_reduce_max(mask, dst, src, work_tensor, repeat_times, src_rep_stride, cal_index=False)
参数说明
参数名称 |
输入/输出 |
含义 |
|---|---|---|
mask |
输入 |
请参考表1中mask参数描述。 |
dst |
输入 |
目的操作数,tensor起始element,起始地址要求4Byte对齐。 Tensor的scope为Unified Buffer。 |
src |
输入 |
源操作数,tensor起始element,起始地址对齐要求请见通用约束。 Tensor的scope为Unified Buffer。 |
work_tensor |
输入 |
指令执行期间存储中间结果,用于内部计算所需操作空间,需特别注意空间大小,参见各指令注意事项。 |
repeat_times |
输入 |
重复迭代次数。Scalar(int32)、立即数(int)、Expr(int32)。注意,推荐使用立即数,性能比较高。 |
src_rep_stride |
输入 |
相邻迭代间,源操作数相同block地址步长。支持的数据类型为:Scalar(int16/int32/int64/uint16/uint32/uint64)、立即数(int)、Expr(int16/int32/int64/uint16/uint32/uint64)。 |
cal_index |
输入 |
指定是否获取最值的索引,仅支持bool类型,默认值为False,取值:
|
dst、src和work_tensor的数据类型需保持一致。
Atlas 200/300/500 推理产品,dst、src和work_tensor支持的数据类型为:Tensor(float16)
Atlas 训练系列产品,dst、src和work_tensor支持的数据类型为:Tensor(float16)
Atlas推理系列产品AI Core,dst、src和work_tensor支持的数据类型为:Tensor(float16/float32)
Atlas推理系列产品Vector Core,dst、src和work_tensor支持的数据类型为:Tensor(float16/float32/int16)
Atlas A2训练系列产品/Atlas 800I A2推理产品,dst、src和work_tensor支持的数据类型为:Tensor(float16/float32)
Atlas 200/500 A2推理产品,dst、src和work_tensor支持的数据类型为:Tensor(float16/float32)
返回值
无
支持的型号
Atlas 200/300/500 推理产品
Atlas 训练系列产品
Atlas推理系列产品AI Core
Atlas推理系列产品Vector Core
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas 200/500 A2推理产品
注意事项
- repeat_times支持的数据类型为:Scalar(int32)、立即数(int)、Expr(int32)。
- 当cal_index=False时,repeat_times
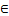 [1,4095]
[1,4095] - 当cal_index=True时:
- 当操作数数据类型为int16时,操作数最大表示数值为32767,因此最多支持255次迭代,repeat_times
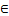 [1,255]。
[1,255]。 - 当操作数数据类型为float16,操作数最大表示数值为65504,因此最多支持511次迭代,repeat_times
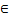 [1,511]。
[1,511]。 - 当操作数数据类型为float32时,repeat_times
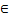 [1,4095]。
[1,4095]。
- 当操作数数据类型为int16时,操作数最大表示数值为32767,因此最多支持255次迭代,repeat_times
- 当cal_index=False时,repeat_times
- src_rep_stride
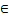 [0,65535],支持的数据类型为:Scalar(int16/int32/int64/uint16/uint32/uint64)、立即数(int)、Expr(int16/int32/int64/uint16/uint32/uint64)。
[0,65535],支持的数据类型为:Scalar(int16/int32/int64/uint16/uint32/uint64)、立即数(int)、Expr(int16/int32/int64/uint16/uint32/uint64)。 - dst结果存储顺序为最值,最值索引。返回结果中索引index数据实际上是按照相应整数类型进行存储的,如dst定义为float16时,index为uint16类型,如果按照float16格式进行读取,index 的值不对,因此注意index使用时需要使用reinterpret_cast_to()方法转换到相应整数类型。
- dst和work_tensor之间不能存在地址重叠。
- 如果存在多个最大值,索引取第一个最大值的索引。
- work_tensor空间限制如下:
- 当cal_index=False时,至少需要repeat_times*2个elements。例如当repeat_times=120时,work_tensor的size至少为240个elements。
- 当cal_index=True时,需要使用公式计算空间大小,公式如下,举例请参考调用示例。
# DTYPE_SIZE指数据类型所占的空间,以Byte为单位,如float16类型占2Bytes。elements_per_block指每个block所需的element个数 elements_per_block = block_size // DTYPE_SIZE[dtype] elements_per_repeat = block_size * 8 // DTYPE_SIZE[dtype] # elements_per_repeat指每个repeat所需的element个数 it1_output_count = 2*repeat_times # 第一轮操作产生的元素个数 def ceil_div(a_value, b_value): return (a_value + b_value - 1) // b_value it2_align_start = ceil_div(it1_output_count, elements_per_block)*elements_per_block # 第二轮操作起始位置偏移,ceil_div功能为相除之后向上取整 it2_output_count = ceil_div(it1_output_count, elements_per_repeat)*2 # 第二轮操作产生的元素个数 it3_align_start = ceil_div(it2_output_count, elements_per_block)*elements_per_block # 第三轮操作起始位置偏移 it3_output_count = ceil_div(it2_output_count, elements_per_repeat)*2 # 第三轮操作产生的元素个数 it4_align_start = ceil_div(it3_output_count, elements_per_block)*elements_per_block # 第四轮操作起始位置偏移 it4_output_count = ceil_div(it3_output_count, elements_per_repeat)*2 # 第四轮操作产生的元素个数 final_work_tensor_need_size = it2_align_start + it3_align_start + it4_align_start + it4_output_count # 最终所需的work_tensor大小
调用示例
- 【举例一】
src, work_tensor, dst均为float16的tensor,src的shape为(65, 128),vec_reduce_max/vec_reduce_min的repeat_times为65。
接口调用示例为:
tik_instance.vec_reduce_max(128, dst, src, work_tensor, 65, 8, cal_index=True)
此时work_tensor的空间计算过程为:
elements_per_block = 16 (elements) elements_per_repeat = 128 (elements) it1_output_count = 2*65 = 130 (elements) def ceil_div(a_value, b_value): return (a_value + b_value - 1) // b_value it2_align_start = ceil_div(130, 16)*16 = 144 (elements) it2_output_count = ceil_div(130, 128)*2 = 4 (elements) it3_align_start = ceil_div(4, 16)*16 = 16 (elements) it3_output_count = ceil_div(4, 128)*2 = 2 (elements)三轮即可拿到最终的最值以及下标,需要的空间work_tensor为:it2_align_start + it3_align_start + it3_output_count = 144 + 16 + 2 = 162 (elements)
- 【举例二】
src, work_tensor, dst均为float16的tensor,src的shape为(65, 128),vec_reduce_max/vec_reduce_min的repeat_times为scalar,值65。对于repeat_times为scalar或包含scalar的情况,需要做四轮计算。
接口调用示例为:
scalar = tik_instance.Scalar(init_value=65, dtype=”int32”) tik_instance.vec_reduce_max(128, dst, src, work_tensor, scalar, 8, cal_index=True)
此时work_tensor的空间计算过程:
elements_per_block = 16 (elements) elements_per_repeat = 128 (elements) it1_output_count = 2*65 = 130 (elements) def ceil_div(a_value, b_value): return (a_value + b_value - 1) // b_value it2_align_start = ceil_div(130, 16)*16 = 144 (elements) it2_output_count = ceil_div(130, 128)*2 = 4 (elements) it3_align_start = ceil_div(4, 16)*16 = 16 (elements) it3_output_count = ceil_div(4, 128)*2 = 2 (elements) it4_align_start = ceil_div(2, 16)*16 = 16 (elements) it4_output_count = ceil_div(2, 128)*2 = 2(elements)对于repeat_times为scalar或包含scalar的情况,虽然第三轮就能拿到结果,但是由于在Python编译时无法获取scalar的值,因此还是跑了四轮,需要的空间work_tensor为:it2_align_start + it3_align_start + it4_align_start + it4_output_count = 144 + 16 + 16 + 2 = 178 (elements)
- 【举例三】
src, work_tensor, dst均为float32的tensor,src的shape为(65, 64),vec_reduce_max/vec_reduce_min的repeat_times为65。
接口调用示例为:
tik_instance.vec_reduce_max(64, dst, src, work_tensor, 65, 8, cal_index=True)
此时work_tensor的空间计算过程为:
elements_per_block = 8 (elements) elements_per_repeat = 64 (elements) it1_output_count = 2*65 = 130 (elements) def ceil_div(a_value, b_value): return (a_value + b_value - 1) // b_value it2_align_start = ceil_div(130, 8)*8 = 136 (elements) it2_output_count = ceil_div(130, 64)*2 = 6 (elements) it3_align_start = ceil_div(6, 8)*8 = 8 (elements) it3_output_count = ceil_div(6, 64)*2 = 2 (elements)此时三轮即可拿到最终的最值以及下标,需要的空间work_tensor为:it2_align_start + it3_align_start + it3_output_count = 136 + 8 + 2 = 146 (elements)
- 【举例四】
src, work_tensor, dst均为float32的tensor,src的shape为(65, 64),vec_reduce_max/vec_reduce_min的repeat_times为scalar,值65。对于repeat_times为scalar或包含scalar的情况,需要做四轮计算。
接口调用示例为:
scalar = tik_instance.Scalar(init_value=65, dtype=”int32”) tik_instance.vec_reduce_max(64, dst, src, work_tensor, scalar, 8, cal_index=True)
此时work_tensor的空间计算过程为:
elements_per_block = 8 (elements) elements_per_repeat = 64 (elements) it1_output_count = 2*65 = 130 (elements) def ceil_div(a_value, b_value): return (a_value + b_value - 1) // b_value it2_align_start = ceil_div(130, 8)*8 = 136 (elements) it2_output_count = ceil_div(130, 64)*2 = 6 (elements) it3_align_start = ceil_div(6, 8)*8 = 8 (elements) it3_output_count = ceil_div(6, 64)*2 = 2 (elements) it4_align_start = ceil_div(2, 8)*8 = 8 (elements) it4_output_count = ceil_div(2, 64)*2 = 2(elements)对于repeat_times为scalar或包含scalar的情况,虽然第三轮就能拿到结果,但是由于在Python编译时无法获取scalar的值,因此还是跑了四轮,需要的空间work_tensor为:it2_align_start + it3_align_start + it4_align_start + it4_output_count = 136 + 8 + 8 + 2 = 154 (elements)
- 完整示例一
from tbe import tik tik_instance = tik.Tik() src_gm = tik_instance.Tensor("float16", (256,), name="src_gm", scope=tik.scope_gm) dst_gm = tik_instance.Tensor("float16", (16,), name="dst_gm", scope=tik.scope_gm) src_ub = tik_instance.Tensor("float16", (256,), name="src_ub", scope=tik.scope_ubuf) dst_ub = tik_instance.Tensor("float16", (16,), name="dst_ub", scope=tik.scope_ubuf) work_tensor_ub = tik_instance.Tensor("float16", (18,), tik.scope_ubuf, "work_tensor_ub") # 将用户输入数据从gm搬运到ub tik_instance.data_move(src_ub, src_gm, 0, 1, 16, 0, 0) # 给dst_ubuf赋初始值0,这样输出结果更加直观 tik_instance.vec_dup(16, dst_ub, 0, 1, 1) tik_instance.vec_reduce_max(128, dst_ub, src_ub, work_tensor_ub, 2, 8, cal_index=True) # 将计算结果从ub搬运到gm tik_instance.data_move(dst_gm, dst_ub, 0, 1, 1, 0, 0) tik_instance.BuildCCE(kernel_name="vec_reduce_max", inputs=[src_gm], outputs=[dst_gm])结果示例:
输入数据(src_gm): [-3.326 -6.883 3.607 -0.969 -0.179 2.254 -3.957 3.242 6.133 -3.559 3.656 -9.88 2.19 4.707 -7.027 -3.598 -3.264 4.44 6.04 -6.35 0.525 -6.492 0.341 -4.477 1.375 6.484 -7.957 -1.243 -9.586 -2.871 -6.688 2.088 5. -1.808 -5.62 9.47 1.311 2.69 8.58 9.3 5.754 -6.25 4.516 -6.6 -0.331 -8.586 4.844 9.81 7.695 -0.332 -7.137 -2.79 2.66 5.316 8.72 1.954 5.043 -7.816 1.207 2.508 -5.06 -1.697 8.5 -6.637 -0.647 -1.211 -3.229 -3.074 7.89 5.043 -3.059 -0.7544 9.484 -2.809 -7.145 -1.051 9.45 7.688 6.695 -2.318 -0.3562 -0.674 1.736 2.994 -2.018 -2.605 -7.113 6.09 -1.766 6.574 -4.47 7.367 -7.93 6.88 7.83 6.527 5.816 -3.135 6.195 -6.734 -8.85 1.705 -5.023 5.992 6.062 -3.342 8.03 -0.748 0.9883 3.191 2.75 8.39 9.17 -5.887 1.378 -8.77 -9.05 -3.11 -7.203 9.79 9.64 3.945 9.32 7.812 7.066 0.664 5.234 -4.61 -3.559 -7.73 1.441 5.434 8.23 4.785 -1.231 8.03 0.293 -0.1658 -5.48 -3.293 8.89 -7.926 -9.66 1.597 0.5396 9.25 -6.74 7.086 -0.954 8.96 2.318 -2.395 -9.19 -6.176 -4.297 -7.812 -1.787 -5.39 6.5 9.055 -0.9556 2.4 2.092 7.35 0.7017 1.548 -2.637 -5.145 -2.938 5.617 -3.451 7.5 -5.426 -7.62 7.535 -9.14 -8.7 -3.436 2.283 -6.18 2.836 5.707 -1.356 8.664 1.625 -3.717 1.478 -6.67 -4.023 2.652 4.805 -8.25 2.63 -1.394 -3.227 1.595 7.49 7.574 -3.053 -1.841 -7.06 0.4524 -5.71 5.37 8.72 8.51 4.836 -5.05 -7.043 5.188 -5.332 5.62 -0.6465 5.773 8.53 7.793 -4.215 7.47 -2.451 8.18 5.543 -7.367 7.105 -0.10364 4.465 0.3362 0.9287 2.447 -9.87 7.844 2.084 4.527 7.582 -3.217 -5.695 -6.375 0.627 2.24 6.625 -9.55 -5.613 7.055 9.48 -6.613 5.49 5.066 4.117 9.516 -4.594 -0.781 2.102 9.94 6.49 -7.82 0.11975 3.146 ] 输出数据(dst_gm): [9.938e+00 1.496e-05 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00]
- 完整示例二
def ceil_div(a_value, b_value): return (a_value + b_value - 1) // b_value tik_instance = tik.Tik() dtype_size = { "int8": 1, "uint8": 1, "int16": 2, "uint16": 2, "float16": 2, "int32": 4, "uint32": 4, "float32": 4, "int64": 8, } # Tensor 的形状 src_shape = (3, 128) dst_shape = (64,) # 数据量大小 src_elements = 3 * 128 dst_elements = 64 # 数据类型 dtype = "float16" src_gm = tik_instance.Tensor(dtype, src_shape, name="src_gm", scope=tik.scope_gm) dst_gm = tik_instance.Tensor(dtype, dst_shape, name="dst_gm", scope=tik.scope_gm) src_ub = tik_instance.Tensor(dtype, src_shape, name="src_ub", scope=tik.scope_ubuf) dst_ub = tik_instance.Tensor(dtype, dst_shape, name="dst_ub", scope=tik.scope_ubuf) # 拷贝用户输入数据到src ubuf # 搬移的片段数 nburst = 1 # 每次搬运的片段长度,单位32B burst = src_elements * dtype_size[dtype] // 32 // nburst dst_burst = dst_elements * dtype_size[dtype] // 32 // nburst # 前burst尾与后burst头的距离,单位32B dst_stride, src_stride = 0, 0 tik_instance.data_move(src_ub, src_gm, 0, nburst, burst, dst_stride, src_stride) # 给dst ubuf赋初始值0,这样输出结果更加直观, 此处暂不对vec_dup 进行说明,详细内容请参考对应的章节 tik_instance.vec_dup(64, dst_ub, 0, 1, 1) # mask 应用于每个迭代的源操作数, 不同的数据类型其取值范围不同,可参见对应的章节,此示例以每次迭代处理34个数 mask = 34 # cal_index 指定是否获取最值的索引,此处以True为例 cal_index = True # 可根据实际情况配置相应的迭代, 此处以6次迭代为例 repeat_times = tik_instance.Scalar(dtype="int32", init_value=6) elements_per_block = 32 // dtype_size[dtype] # 16 elements_per_repeat = 256 // dtype_size[dtype] # 128 it1_output_count = 2 * 6 # 12 # 第二轮操作起始位置偏移,ceil_div功能为相除之后向上取整,16 it2_align_start = ceil_div(it1_output_count, elements_per_block) * elements_per_block # 第二轮操作产生的元素个数 2 it2_output_count = ceil_div(it1_output_count, elements_per_repeat) * 2 # 第三轮操作起始位置偏移,ceil_div功能为相除之后向上取整,16 it3_align_start = ceil_div(it2_output_count, elements_per_block) * elements_per_block # 第二轮操作产生的元素个数 2 it3_output_count = ceil_div(it2_output_count, elements_per_repeat) * 2 # 第四轮操作起始位置偏移,ceil_div功能为相除之后向上取整,16 it4_align_start = ceil_div(it3_output_count, elements_per_block) * elements_per_block # 第四轮操作产生的元素个数 2 it4_output_count = ceil_div(it3_output_count, elements_per_repeat) * 2 # 需要的空间至少 50 final_work_tensor_need_size = it2_align_start + it3_align_start + it4_align_start + it4_output_count cal_shape = (final_work_tensor_need_size,) work_tensor_ub = tik_instance.Tensor(dtype, cal_shape, tik.scope_ubuf, "work_tensor_ub") tik_instance.vec_dup(final_work_tensor_need_size, work_tensor_ub, 0, 1, 1) # 相邻迭代间,操作数头与头之间的步长,单位为block,当前表示第一次迭代的头与第二次迭代头间隔3个block src_rep_stride = 3 tik_instance.vec_reduce_max(mask, dst_ub, src_ub, work_tensor_ub, repeat_times, src_rep_stride, cal_index=cal_index) # 当前示例中work_tensor_ub 存储的值是[3.30e+01 1.97e-06 8.10e+01 1.97e-06 1.29e+02 1.97e-06 1.77e+02 1.97e-06 # 2.25e+02 1.97e-06 2.73e+02 1.97e-06 0. 0. ...],分别为6次迭代的结果 # 将计算结果拷贝到目标gm tik_instance.data_move(dst_gm, dst_ub, 0, nburst, dst_burst, dst_stride, src_stride) tik_instance.BuildCCE(kernel_name="vec_reduce_max", inputs=[src_gm], outputs=[dst_gm]) 示例结果 输入数据(src_gm): [[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97. 98. 99. 100. 101. 102. 103. 104. 105. 106. 107. 108. 109. 110. 111. 112. 113. 114. 115. 116. 117. 118. 119. 120. 121. 122. 123. 124. 125. 126. 127.] [128. 129. 130. 131. 132. 133. 134. 135. 136. 137. 138. 139. 140. 141. 142. 143. 144. 145. 146. 147. 148. 149. 150. 151. 152. 153. 154. 155. 156. 157. 158. 159. 160. 161. 162. 163. 164. 165. 166. 167. 168. 169. 170. 171. 172. 173. 174. 175. 176. 177. 178. 179. 180. 181. 182. 183. 184. 185. 186. 187. 188. 189. 190. 191. 192. 193. 194. 195. 196. 197. 198. 199. 200. 201. 202. 203. 204. 205. 206. 207. 208. 209. 210. 211. 212. 213. 214. 215. 216. 217. 218. 219. 220. 221. 222. 223. 224. 225. 226. 227. 228. 229. 230. 231. 232. 233. 234. 235. 236. 237. 238. 239. 240. 241. 242. 243. 244. 245. 246. 247. 248. 249. 250. 251. 252. 253. 254. 255.] [256. 257. 258. 259. 260. 261. 262. 263. 264. 265. 266. 267. 268. 269. 270. 271. 272. 273. 274. 275. 276. 277. 278. 279. 280. 281. 282. 283. 284. 285. 286. 287. 288. 289. 290. 291. 292. 293. 294. 295. 296. 297. 298. 299. 300. 301. 302. 303. 304. 305. 306. 307. 308. 309. 310. 311. 312. 313. 314. 315. 316. 317. 318. 319. 320. 321. 322. 323. 324. 325. 326. 327. 328. 329. 330. 331. 332. 333. 334. 335. 336. 337. 338. 339. 340. 341. 342. 343. 344. 345. 346. 347. 348. 349. 350. 351. 352. 353. 354. 355. 356. 357. 358. 359. 360. 361. 362. 363. 364. 365. 366. 367. 368. 369. 370. 371. 372. 373. 374. 375. 376. 377. 378. 379. 380. 381. 382. 383.]] 输出数据(dst_gm): [2.73e+02 1.63e-05 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00 0.00e+00]