vec_rec_high_preci
功能说明
按element取倒数: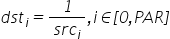 。该接口的精度高于vec_rec。
。该接口的精度高于vec_rec。
函数原型
vec_rec_high_preci(mask, dst, src, work_tensor, repeat_times, dst_rep_stride, src_rep_stride)
参数说明
请参见参数说明。下面仅对dst/src/work_tensor参数进行说明:
dst与src的数据类型需要保持一致,支持的数据类型为:Tensor(float16/float32);work_tensor支持的数据类型为Tensor(float32)。
- 如果传入tensor带有偏移,则作为参数传入时应写成tensor[offset1:offset2],表示从offset1开始到offset2结束,也可以写成tensor[offset1:],表示从offset1开始;如果仅仅输入tensor[offset],代表仅传入一个元素,该接口内部实现过程中会对tensor进行切片,无法切分一个元素,运行时可能会产生错误,因此不支持该形式;
- 如果传入操作数tensor不带偏移,可以直接写成tensor传入。
【work_tensor参数说明】:
work_tensor为用户定义的临时buffer空间,存储中间结果,空间限定在scope_ubuf,用于内部计算使用。
【work_tensor空间计算说明】:
- 根据repeat_times、mask、src_rep_stride计算出src计算所需要的最小空间:src_extent_size = (repeat_times - 1)*src_rep_stride*block_len + mask_len
当源操作数数据类型为float16时,block_len=16;
当源操作数数据类型为float32时,block_len=8;
当mask是连续模式时,mask_len 即mask值;
当mask为逐bits模式时,mask_len为最高有效位的位数值。
- 对src最小空间进行32Byte向上取整对齐: wk_size_unit = ((src_extent_size+block_len-1)//block_len)*block_len
- 计算work_tensor大小:
当源操作数数据类型为float16时,则work_tensor需要申请的大小为4*wk_size_unit
当源操作数数据类型为float32时,则work_tensor需要申请的大小为2*wk_size_unit
【work_tensor空间计算举例】:
- 如果src的dtype为float16,mask为128,repeat_times为2,src_rep_stride为8,则block_len=16,mask_len=128,src_extent_size=(2-1)*8*16+128=256;对src_extent_size进行32Byte对齐,wk_size_unit=((256+16-1)//16)*16=256;则work_tensor申请的空间大小为4*256=1024。
- 如果src的dtype为float32,mask为64,repeat_times为2,src_rep_stride为8,则block_len=8,mask_len=64,src_extent_size=(2-1)*8*8+64=128;对src_extent_size进行32Byte对齐,wk_size_unit=((128+8-1)//8)*8=128;则work_tensor申请的空间大小为2*128=256。
注意事项
- dst、src、work_tensor应声明在scope_ubuf。
- dst、src、work_tensor三个tensor的空间不能重叠。
- 当输入数据为0时,返回结果未知。
- 对于Atlas 200/300/500 推理产品,使用该接口处理float16和float32类型的数据时,计算精度均高于vec_rec,解决了vec_rec精度不足问题。
- 对于Atlas 训练系列产品,使用该接口处理float16和float32类型的数据时,计算精度均高于vec_rec,解决了vec_rec精度不足问题。
- 对于Atlas推理系列产品AI Core,使用该接口处理float16类型的数据时,计算精度均高于vec_rec,解决了vec_rec精度不足问题;使用该接口处理float32类型的数据时,使用效果和vec_rec一样。
- 对于Atlas推理系列产品Vector Core,使用该接口处理float16类型的数据时,计算精度均高于vec_rec,解决了vec_rec精度不足问题;使用该接口处理float32类型的数据时,使用效果和vec_rec一样。
- Atlas A2训练系列产品/Atlas 800I A2推理产品,使用该接口处理float16和float32类型的数据时,计算精度均高于vec_rec,解决了vec_rec精度不足问题。
- Atlas 200/500 A2推理产品,使用该接口处理float16和float32类型的数据时,计算精度均高于vec_rec,解决了vec_rec精度不足问题。
- 其它注意事项请参考注意事项。
返回值
无
支持的型号
Atlas 200/300/500 推理产品
Atlas 训练系列产品
Atlas推理系列产品AI Core
Atlas推理系列产品Vector Core
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas 200/500 A2推理产品
调用示例1
此样例是针对数据量较小、一次搬运就可以完成的场景,目的是让大家了解接口的功能,更复杂的数据量较大的样例可参见调用示例。
from tbe import tik
# 定义容器
tik_instance = tik.Tik()
# 定义计算tensor
src_gm = tik_instance.Tensor("float32", (128,), name="src_gm", scope=tik.scope_gm)
dst_gm = tik_instance.Tensor("float32", (128,), name="dst_gm", scope=tik.scope_gm)
src_ub = tik_instance.Tensor("float32", (128,), name="src_ub", scope=tik.scope_ubuf)
dst_ub = tik_instance.Tensor("float32", (128,), name="dst_ub", scope=tik.scope_ubuf)
# 数据从gm搬运到ub
tik_instance.data_move(src_ub, src_gm, 0, 1, 128*4 // 32, 0, 0)
# 计算work_tensor大小
mask = [0, 2**64 - 1]
mask_len = 64
repeat_times = 2
dst_rep_stride = 8
src_rep_stride = 8
block_len = 8 # src dtype is float32
src_extent_size = (repeat_times - 1)*src_rep_stride*block_len + mask_len
wk_size_unit = ((src_extent_size + block_len - 1)//block_len) *block_len
wk_size = 2*wk_size_unit
# 定义work_tensor
work_tensor_ub = tik_instance.Tensor("float32", (wk_size,), name="work_tensor_ub", scope=tik.scope_ubuf)
# 如果work_tensor有索引,需要写成work_tensor[index:]
tik_instance.vec_rec_high_preci(mask_len, dst_ub, src_ub, work_tensor_ub[0:], repeat_times, dst_rep_stride, src_rep_stride)
# 数据从ub搬运到gm
tik_instance.data_move(dst_gm, dst_ub, 0, 1, 128*4 // 32, 0, 0)
tik_instance.BuildCCE(kernel_name="test_vec_rec_high_preci", inputs=[src_gm], outputs=[dst_gm])
结果示例:
输入: [-6.9427586 -3.5300326 1.176882 ... -6.196793 9.0379095] 输出: [-0.14403497 -0.2832835 0.8497028 ... -0.16137381 0.11064506]
调用示例2
此样例是针对数据量较小、一次搬运就可以完成的场景,目的是让大家了解接口的功能,更复杂的数据量较大的样例可参见调用示例。
from tbe import tik
# 定义容器
tik_instance = tik.Tik()
# 定义计算tensor
src_gm = tik_instance.Tensor("float16", (128,), name="src_gm", scope=tik.scope_gm)
dst_gm = tik_instance.Tensor("float16", (128,), name="dst_gm", scope=tik.scope_gm)
src_ub = tik_instance.Tensor("float16", (128,), name="src_ub", scope=tik.scope_ubuf)
dst_ub = tik_instance.Tensor("float16", (128,), name="dst_ub", scope=tik.scope_ubuf)
# 数据从gm搬运到ub
tik_instance.data_move(src_ub, src_gm, 0, 1, 128*2 // 32, 0, 0)
# 计算work_tensor大小
mask = 128
mask_len = mask
repeat_times = 1
dst_rep_stride = 8
src_rep_stride = 8
block_len = 16 # src dtype is float16
src_extent_size = (repeat_times - 1)*src_rep_stride*block_len + mask_len
wk_size_unit = ((src_extent_size + block_len - 1) // block_len)*block_len
wk_size = 4*wk_size_unit
# 定义work_tensor
work_tensor_ub = tik_instance.Tensor("float32", (wk_size,), name="work_tensor_ub", scope=tik.scope_ubuf)
# 如果work_tensor有索引,需要写成work_tensor[index:]
tik_instance.vec_rec_high_preci(mask_len, dst_ub, src_ub, work_tensor_ub[0:], repeat_times, dst_rep_stride, src_rep_stride)
# 数据从ub搬运到gm
tik_instance.data_move(dst_gm, dst_ub, 0, 1, 128*2 // 32, 0, 0)
tik_instance.BuildCCE(kernel_name="test_vec_rec_high_preci", inputs=[src_gm], outputs=[dst_gm])
结果示例:
输入: [-7.08 -4.434 1.294 ... 8.82 -2.854] 输出: [-0.1412 -0.2256 0.773 ... 0.1134 -0.3503]