Hccl模板参数
功能说明
创建Hccl对象时需要传入模板参数HcclServerType 。
函数原型
Hccl类定义如下,模板参数HcclServerType说明见表1。
1 2 |
template <HcclServerType serverType = HcclServerType::HCCL_SERVER_TYPE_AICPU> class Hccl; |
参数说明
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
注意事项
无
调用示例
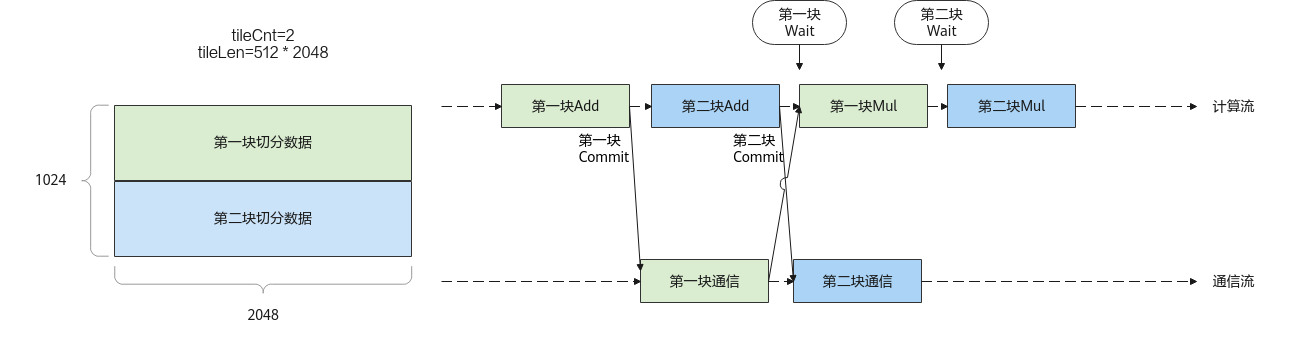
以Add计算+AllReduce通信+Mul计算的任务编排方式为例,辅以代码片段,对本通信API在计算和通信融合的场景下的使用进行说明:
图1 Add计算+AllReduce通信+Mul计算任务编排
// @brief add+allreduce+mul融合算子kernel,
// 任务编排为先进行Add计算,然后将其计算结果作为AllReduce的输入进行ReduceSum操作,
// 最后将AllReduce的结果作为Mul计算的第一个输入,与Mul的第二个输入进行element-wise mul计算,将结果写到cGM输出内存中。
// @param [in] aGM: Add计算的第一个输入对应的GM内存
// @param [in] bGM: Add计算的第二个输入对应的GM内存
// @param [in] mulGM: Mul计算的第二个输入对应的GM内存
// @param [out] cGM: add+allreduce+mul融合计算的输出GM内存
// @param [in] workspaceGM 用于存储中间计算结果的GM内存
// @param [in] tilingGM 存放TilingData的GM内存
extern "C" __global__ __aicore__ void add_all_reduce_mul(
GM_ADDR aGM, GM_ADDR bGM, GM_ADDR mulGM, GM_ADDR cGM, GM_ADDR workspaceGM, GM_ADDR tilingGM)
{
// 假设本Kernel的所有计算操作和通信任务下发都是在AI Cube核完成,AI Vector核退出执行
if (g_CoreType == AIV) { return; }
// 从tilingGM中获取预先准备好的Tiling数据
// 此处假设Add和Mul计算的切分策略一致,即共用一个tiling数据
GET_TILING_DATA(tiling_data, tilingGM);
int tileCnt = tiling_data.tileCnt; // 将1个输入数据切分为tileCnt轮进行计算
int tileLen = tiling_data.tileLen; // 每次计算的数据个数tileLen
// Add计算API的初始化
KernelAdd add_op;
add_op.Init(tileLen, 2);
// step1. 用户创建Hccl客户端对象的创建+初始化
Hccl<HCCL_SERVER_TYPE_AICPU> hccl;
auto contextGM = AscendC::GetHcclContext<HCCL_GOURP_ID_0>(); // AscendC自定义算子框架提供的获取通信上下文的能力,对应的数据结构为:HcclCombinOpParam
hccl.Init(contextGM);
auto aAddr = aGM; // 每次切分计算,Add计算第一个输入参与计算的地址
auto bAddr = bGM; // 每次切分计算,Add计算第二个输入参与计算的地址
auto computeResAddr = workspaceGM; // workspaceGM用来临时存放Add计算的结果,同时作为通信任务的输入地址
auto cAddr = cGM; // cGM先用来存放AllReduce的通信结果,同时作为Mul计算的第一个输入
auto aOffset = tileLen * sizeof(DT_FLOAT16); // 每次切分计算,Add计算第一个输入参与计算的数据size
auto bOffset = tileLen * sizeof(DT_FLOAT16); // 每次切分计算,Add计算第二个输入参与计算的数据size
auto cOffset = tileLen * sizeof(DT_FLOAT16); // 每次切分计算,Add计算结果得到的数据size
HcclHandle hanleIdList[tileCnt];
for (int i = 0; i < tileCnt; i++) {
// step2. 用户调用AllReduce接口,提前通知服务端完成通信任务的组装和下发,该接口返回该通信任务的标识handleId给用户
// PS: 可以将这个通信任务下发在计算开始前生成,这样其任务组装会在计算流水中被掩盖
auto handleId = hccl.AllReduce(computeResAddr, cAddr, tileLen, HCCL_DATA_TYPE_FP16, HCCL_REDUCE_SUM);
hanleIdList[i] = handleId;
// step3 用户开始调用Add计算Api的初始化和计算,并调用SyncAll等待该计算完成
add_op.UpdateAddress(aAddr, bAddr, computeResAddr);
add_op.Process();
// 等待计算任务在所有block上执行完成
SyncAll();
// step4. 当每份切分数据的Add计算完成后,用户即可调用Commit接口通知通信侧可以执行handleId对应的通信任务(异步接口)
hccl.Commit(handleId);
// 更新下一份切分数据的地址
aAddr += aOffset;
bAddr += bOffset;
computeResAddr += cOffset;
cAddr += cOffset;
}
// Mul计算Api对象的创建
KernelMul mul_op;
for (int i = 0; i < tileCnt; i++) {
// step5. 用户在进行mul计算前,需要调用Wait阻塞接口确保对应切分数据的通信执行完毕,即确保mul的第一个输入的数据ready
hccl.Wait(hanleIdList[i]);
SyncAll(); // 核间同步
// mul计算的参数设置,参数分别为:第一个输入的地址、第二个输入的地址、计算结果的地址,一次mul计算的数据个数
mul_op.InitAddress(cAddr, mulAddr, cAddr, tileLen, 1);
// step6. mul计算执行
mul_op.Process();
// 更新下一份切分数据的地址
mulAddr += cOffset;
cAddr += cOffset;
}
// step7. 后续无通信任务编排,用户调用Finalize接口通知服务端执行完通信任务后即可退出
hccl.Finalize();
}
父主题: Hccl