SelectWithBytesMask
函数功能
给定两个源操作数src0和src1,根据maskTensor相应位置的值(非bit位)选取元素,得到目的操作数dst。选择的规则为:当Mask的值为0时,从src0中选取,否则从src1选取。
该接口支持多维Shape,需满足maskTensor和源操作数Tensor的前轴(非尾轴)元素个数相同,且maskTensor尾轴元素个数大于等于源操作数尾轴元素个数,maskTensor多余部分丢弃不参与计算。
- maskTensor尾轴需32字节对齐且元素个数为16的倍数。
- 源操作数Tensor尾轴需32字节对齐。
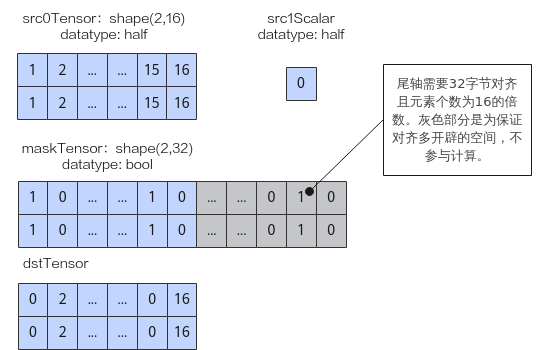
如下图样例,源操作数src0为Tensor,shape为(2,16),数据类型为half,尾轴长度满足32字节对齐;源操作数src1为scalar,数据类型为half;maskTensor的数据类型为bool,为满足对齐要求shape为(2,32),仅有图中蓝色部分的mask掩码生效,灰色部分不参与计算。输出目的操作数dstTensor如下图所示。
实现原理
以float类型,ND格式,shape为[m, k1]的source输入Tensor,shape为[m, k2]的mask Tensor为例,描述SelectWithBytesMask高阶API内部算法框图,如下图所示。
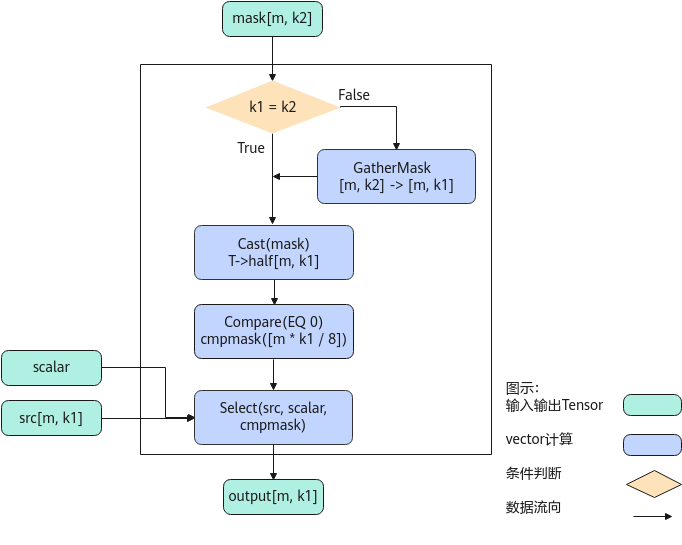
计算过程分为如下几步,均在Vector上进行:
- GatherMask步骤:如果k1, k2不相等,则根据src的shape[m, k1],对输入mask[m, k2]通过GatherMask进行reduce计算,使得mask的k轴多余部分被舍去,shape转换为[m, k1];
- Cast步骤:将上一步的mask结果cast成half类型;
- Compare步骤:使用Compare接口将上一步的mask结果与0进行比较,得到cmpmask结果;
- Select步骤:根据cmpmask的结果,选择srcTensor相应位置的值或者scalar值,输出Output。
函数原型
- src0为srcTensor(tensor类型),src1为srcScalar(scalar类型)
1 2
template <typename T, typename U, bool isReuseMask = true> __aicore__ inline void SelectWithBytesMask(const LocalTensor<T> &dst, const LocalTensor<T> &src0, T src1, const LocalTensor<U> &mask, const LocalTensor<uint8_t> &sharedTmpBuffer, const SelectWithBytesMaskShapeInfo &info)
- src0为srcScalar(scalar类型),src1为srcTensor(tensor类型)
1 2
template <typename T, typename U, bool isReuseMask = true> __aicore__ inline void SelectWithBytesMask(const LocalTensor<T> &dst, T src0, const LocalTensor<T> &src1, const LocalTensor<U> &mask, const LocalTensor<uint8_t> &sharedTmpBuffer, const SelectWithBytesMaskShapeInfo &info)
该接口需要额外的临时空间来存储计算过程中的中间变量。临时空间需要开发者申请并通过sharedTmpBuffer入参传入。临时空间大小BufferSize的获取方式如下:通过GetSelectWithBytesMaskMaxMinTmpSize中提供的接口获取需要预留空间范围的大小。
参数说明
|
参数名 |
描述 |
|---|---|
|
T |
操作数的数据类型。 |
|
U |
掩码Tensor mask的数据类型。 |
|
isReuseMask |
是否允许修改maskTensor。默认为True。 取值为True时,仅在maskTensor尾轴元素个数和srcTensor尾轴元素个数不同的情况下,maskTensor可能会被修改;其余场景,maskTensor不会修改。 为False时,任意场景下,maskTensor均不会修改,但可能会需要更多的临时空间。 |
|
参数名称 |
输入/输出 |
含义 |
|---|---|---|
|
dst |
输出 |
目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas推理系列产品AI Core,支持的数据类型为:half/float Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float |
|
src0(srcTensor) src1(srcTensor) |
输入 |
源操作数。源操作数Tensor尾轴需32字节对齐。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas推理系列产品AI Core,支持的数据类型为:half/float Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float |
|
src1(srcScalar) src0(srcScalar) |
输入 |
源操作数。类型为scalar。 Atlas推理系列产品AI Core,支持的数据类型为:half/float Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float |
|
mask |
输入 |
掩码Tensor。用于描述如何选择srcTensor和srcScalar之间的值。maskTensor尾轴需32字节对齐且元素个数为16的倍数。 取值为0x00/0x01。
Atlas推理系列产品AI Core,支持的数据类型为:bool/uint8_t/int8_t/uint16_t/int16_t/uint32_t/int32_t Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:bool/uint8_t/int8_t/uint16_t/int16_t/uint32_t/int32_t |
|
sharedTmpBuffer |
输入 |
该API用于计算的临时空间,所需空间大小根据GetSelectWithBytesMaskMaxMinTmpSize获取。 Atlas推理系列产品AI Core,支持的数据类型为:uint8_t Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:uint8_t |
|
info |
输入 |
描述SrcTensor和maskTensor的shape信息。SelectWithBytesMaskShapeInfo类型,定义如下: struct SelectWithBytesMaskShapeInfo {
__aicore__ SelectWithBytesMaskShapeInfo(){};
uint32_t firstAxis = 0; // srcLocal/maskTensor的前轴元素个数
uint32_t srcLastAxis = 0; // srcLocal的尾轴元素个数
uint32_t maskLastAxis = 0;// maskTensor的尾轴元素个数
};
|
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas推理系列产品AI Core
注意事项
- 为了节省地址空间,开发者可以定义一个Tensor,供源操作数与目的操作数同时使用(即地址重叠),相关约束如下:源操作数与目的操作数之间要求100%完全重叠,不支持部分重叠。
- 操作数地址偏移对齐要求请参见通用约束。
- maskTensor尾轴元素个数和源操作数尾轴元素个数不同的情况下, maskTensor的数据有可能被接口改写。
调用示例
AscendC::SelectWithBytesMaskShapeInfo shapeInfo; shapeInfo.firstAxis = 2; shapeInfo.srcLastAxis = 32; shapeInfo.maskLastAxis = 32; AscendC::SelectWithBytesMask(dstLocal, srcLocal, src1, maskLocal, tmpTensor, shapeInfo);
输入数据(src0Local): [-84.6 -24.38 30.97 -30.25 22.28 -92.56 90.44 -58.72 -86.56 5.74 6.754 -86.3 -96.7 -37.38 -81.9 46.9 -99.4 94.2 -41.78 -60.3 -14.43 78.6 8.93 -65.2 79.94 -46.88 4.516 20.03 -25.56 24.73 0.3223 21.98 -87.4 -93.9 46.22 -69.9 90.8 -24.17 -96.2 -91. 90.44 9.766 68.25 -57.78 -75.44 -8.86 -91.56 21.6 76. 82.1 -78. -23.75 92. -66.44 75. 94.9 2.62 -90.9 15.945 38.16 50.84 96.94 -59.38 44.22 ] 输入数据(src1): [35.6] 输入数据(maskLocal): [False True False False True True False True True False False True False True False True True False False False True True True True True False True False True True True True False False True False True False True False True False True False True True True False True False True False True False True True True False False False True False True True ] 输出数据(dstLocal): [-84.6 35.6 30.97 -30.25 35.6 35.6 90.44 35.6 35.6 5.74 6.754 35.6 -96.7 35.6 -81.9 35.6 35.6 94.2 -41.78 -60.3 35.6 35.6 35.6 35.6 35.6 -46.88 35.6 20.03 35.6 35.6 35.6 35.6 -87.4 -93.9 35.6 -69.9 35.6 -24.17 35.6 -91. 35.6 9.766 35.6 -57.78 35.6 35.6 35.6 21.6 35.6 82.1 35.6 -23.75 35.6 -66.44 35.6 35.6 35.6 -90.9 15.945 38.16 35.6 96.94 35.6 35.6 ]
样例模板
#include "kernel_operator.h"
template <typename srcType, typename maskType>
class KernelSelect {
public:
__aicore__ inline KernelSelect()
{}
__aicore__ inline void Init(GM_ADDR src1Gm, GM_ADDR maskGm, GM_ADDR dstGm, float scalarValue, uint32_t firstAxis,
uint32_t srcAxis, uint32_t maskAxis, uint32_t tmpSize)
{
uint32_t srcSize = firstAxis * srcAxis;
uint32_t maskSize = firstAxis * maskAxis;
src1Global.SetGlobalBuffer(reinterpret_cast<__gm__ srcType *>(src1Gm), srcSize);
mask_global.SetGlobalBuffer(reinterpret_cast<__gm__ maskType *>(maskGm), maskSize);
dstGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ srcType *>(dstGm), srcSize);
pipe.InitBuffer(inQueueX1, 1, srcSize * sizeof(srcType));
pipe.InitBuffer(maskQueue, 1, maskSize * sizeof(maskType));
pipe.InitBuffer(tmpQueue, 1, tmpSize);
bufferSize = srcSize;
scalar = static_cast<srcType>(scalarValue);
maskBufferSize = maskSize;
info.firstAxis = firstAxis;
info.srcLastAxis = srcAxis;
info.maskLastAxis = maskAxis;
}
__aicore__ inline void Process()
{
CopyIn();
Compute();
CopyOut();
}
private:
__aicore__ inline void CopyIn()
{
srcLocal1 = inQueueX1.AllocTensor<srcType>();
AscendC::DataCopy(srcLocal1, src1Global, bufferSize);
inQueueX1.EnQue(srcLocal1);
AscendC::LocalTensor<maskType> maskLocal = maskQueue.AllocTensor<maskType>();
AscendC::DataCopy(maskLocal, mask_global, maskBufferSize);
maskQueue.EnQue(maskLocal);
}
__aicore__ inline void Compute()
{
srcLocal1 = inQueueX1.DeQue<srcType>();
AscendC::LocalTensor<maskType> maskLocal = maskQueue.DeQue<maskType>();
AscendC::LocalTensor<uint8_t> tmpLocal = tmpQueue.AllocTensor<uint8_t>();
AscendC::SelectWithBytesMask(srcLocal1, srcLocal1, scalar, maskLocal, tmpLocal, info);
// Reverse Select.
// AscendC::SelectWithBytesMask(srcLocal1, scalar, srcLocal1, maskLocal, tmpLocal, info);
// Do not reuse source.
// AscendC::SelectWithBytesMask<srcType, maskType, false>(srcLocal1, srcLocal1, scalar, maskLocal, tmpLocal, info);
maskQueue.FreeTensor(maskLocal);
tmpQueue.FreeTensor(tmpLocal);
}
__aicore__ inline void CopyOut()
{
AscendC::DataCopy(dstGlobal, srcLocal1, bufferSize);
inQueueX1.FreeTensor(srcLocal1);
}
private:
AscendC::GlobalTensor<srcType> src1Global;
AscendC::GlobalTensor<srcType> dstGlobal;
AscendC::GlobalTensor<maskType> mask_global;
AscendC::TPipe pipe;
AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueX1;
AscendC::TQue<AscendC::QuePosition::VECIN, 1> maskQueue;
AscendC::TQue<AscendC::QuePosition::VECIN, 1> tmpQueue;
AscendC::TQue<AscendC::QuePosition::VECOUT, 1> outQueue;
AscendC::SelectWithBytesMaskShapeInfo info;
AscendC::LocalTensor<srcType> srcLocal1;
uint32_t bufferSize = 0;
uint32_t maskBufferSize = 0;
srcType scalar = 0.0f;
};
template <typename srcType, typename maskType>
__aicore__ void kernel_select_with_bytes_mask_operator(GM_ADDR src1Gm, GM_ADDR maskGm, GM_ADDR dstGm, float scalar,
uint32_t firstAxis, uint32_t srcSize, uint32_t maskSize, uint32_t tmpSize)
{
KernelSelect<srcType, maskType> op;
op.Init(src1Gm, maskGm, dstGm, scalar, firstAxis, srcSize, maskSize, tmpSize);
op.Process();
}
extern "C" __global__ __aicore__ void kernel_select_with_bytes_mask_operator(
GM_ADDR src1Gm, GM_ADDR maskGm, GM_ADDR dstGm, GM_ADDR tiling)
{
GET_TILING_DATA(tilingData, tiling);
kernel_select_with_bytes_mask_operator<half, bool>(src1Gm,
maskGm,
dstGm,
tilingData.scalarValue,
tilingData.firstAxis,
tilingData.srcSize,
tilingData.maskSize,
tilingData.tmpSize);
}