优化bank分配以提升读写性能
【优先级】高
【描述】Unified Buffer中bank结构如下图所示。UB总大小(假设为192K)会被分成48个bank:bank内组成为128行(bank_depth = 128),每一行长度为C0=32B,即bank_depth * C0的二维结构;bank间组成为16个bank group(bank_group = 16),每个group有3个bank(bank_num = 3),即bank_group * bank_num的二维结构。
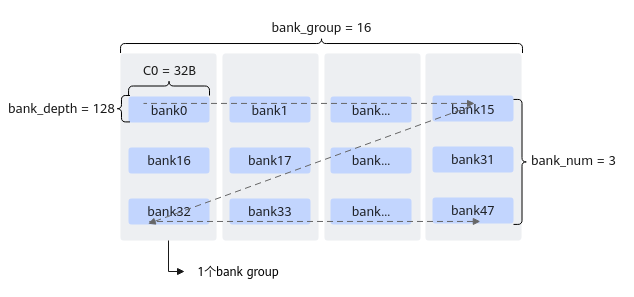
Vector单元每拍(一拍为一个指令周期)能够从每个bank group中读取一份数据,因此每拍最多能够读取16组 * C0(32B)= 512B数据。Vector单元每拍能够向每个bank group中写入一份数据,因此每拍最多能够写入16组 * C0(32B)= 512B数据。当多个操作尝试同时访问同一个bank或者bank group时,可能会发生bank冲突,这种冲突会导致访问排队,降低性能。
bank冲突会出现在以下三种场景:
- 读写冲突:在同时读写的时候,读口与写口在操作同一个bank时会发生bank冲突。
- 写写冲突:同时写一块bank group时,会发生bank冲突。
- 读读冲突:同时读一块bank group时,会发生bank冲突。
假设,0x10000地址在bank16上,0x10020在bank17上,0x20020在bank33上,如下图所示:

- 读写冲突,Vector指令的输入输出地址之间,当src/dst同时读写到同一个bank时会造成读写冲突,示例如下:
表1 读写冲突示例 序号
src0地址
src1地址
bank
bank_group
结论
示例1
0x10020
0x10000
bank_id0 != bank_id1
bank_group_id0 != bank_group_id1
无冲突
示例2
0x10020
0x10E20
bank_id0 == bank_id1
bank_group_id0 == bank_group_id1
存在冲突
- 写写冲突,Vector指令一拍可同时写8个datablock,当datablock0~datablock7同时写到一个bank_group时会造成写写冲突,举例如下:
表2 写写冲突示例 序号
dst地址
blk_stride
block0_addr
block1_addr
block2_addr
...
结论
示例1
0x1FE00
16
0x1FE00
0x20000
0x20200
...
8个datablock全冲突,8拍完成一个repeat
示例2
0x1FE00
8
0x1FE00
0x1FF00
0x20000
...
datablock0和datablock2冲突,4拍完成一个repeat
- 读读冲突
- 双src场景,对于Add这类双输入指令,src0和src1分别占据一个读口,当src0/src1同时读到同一个bank_group时会造成读读冲突,举例如下:
表3 双src场景读读冲突示例 序号
src0地址
src1地址
bank
bank_group
结论
示例1
0x10020
0x20020
bank_id0 != bank_id1
bank_group_id0 == bank_group_id1
存在冲突
示例2
0x10020
0x10000
bank_id0 != bank_id1
bank_group_id0 != bank_group_id1
无冲突
- 单src场景,Vector指令一拍可同时读8个datablock,当datablock0~datablock7同时读到一个bank_group时会造成读读冲突,举例如下:
表4 单src场景读读冲突示例 序号
src地址
blk_stride
block0_addr
block1_addr
block2_addr
...
结论
示例1
0x1FE00
16
0x1FE00
0x20000
0x20200
...
8个datablock全冲突,8拍完成一个repeat
示例2
0x1FE00
8
0x1FE00
0x1FF00
0x20000
...
datablock0和datablock2冲突,4拍完成一个repeat
- 双src场景,对于Add这类双输入指令,src0和src1分别占据一个读口,当src0/src1同时读到同一个bank_group时会造成读读冲突,举例如下:

【反例】
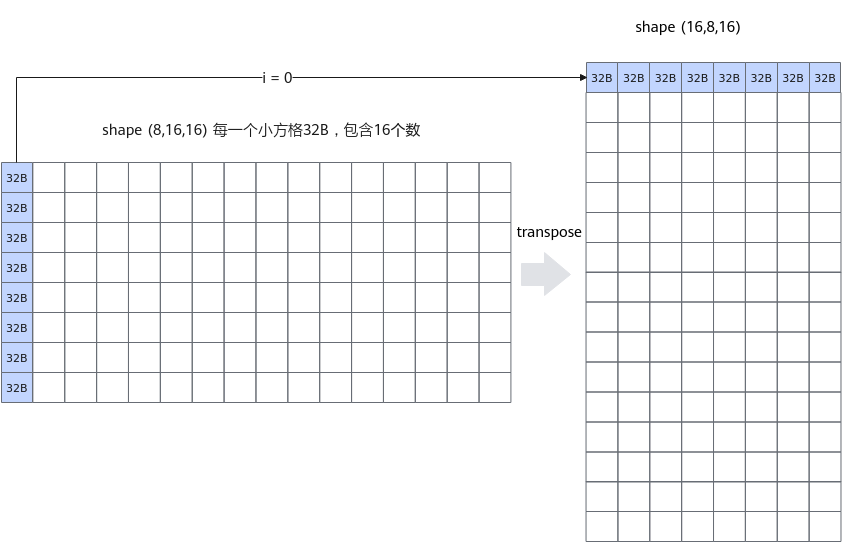
对一个输入或输出tensor使用tensor高维切分接口实现跳读跳写,当dataBlockStride为16的整数倍时将发生读读冲突。假设我们要对一个shape为(8, 16, 16)的输入做(1, 0, 2)的transpose,输出shape为(16, 8, 16)。
如下“跳读,连续写”的代码,将导致同一repeat内输入的8个datablock都在同一个bank_group而发生读读冲突。
1 2 3 4 5 6 7 |
uint64_t mask = 128; UnaryRepeatParams params; params.dstBlkStride = 1; params.srcBlkStride = 16; for(uint32_t i=0; i<16; i++) { AscendC::Adds(dstLocal[i * 128], srcLocal[i * 16], 0, mask, 1, params); } |
【正例】
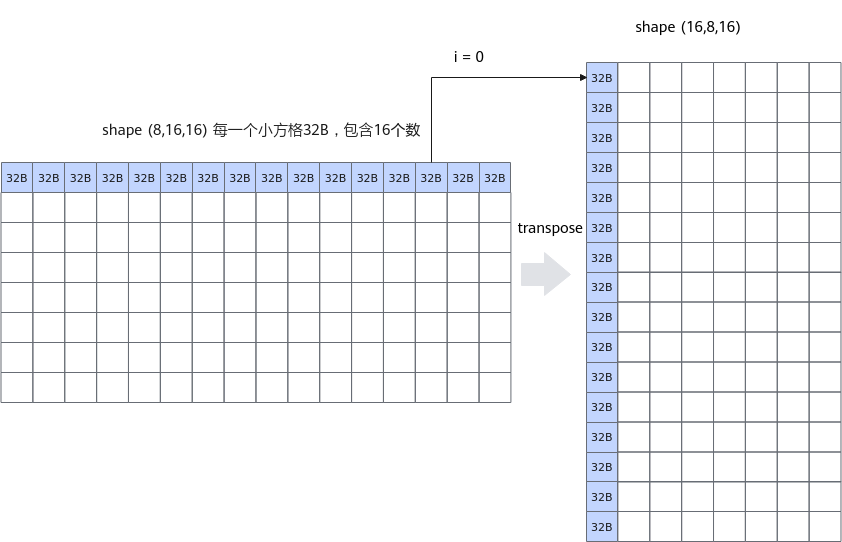
通过修改取数规则为“连续读,跳写”避免冲突问题,示例代码如下:
1 2 3 4 5 6 7 |
uint64_t mask = 128; UnaryRepeatParams params; params.dstBlkStride = 8; params.srcBlkStride = 1; for(uint32_t i=0; i<8; i++) { AscendC::Adds(dstLocal[i * 16], srcLocal[i * 256], 0, mask, 2, params); } |
【正例】
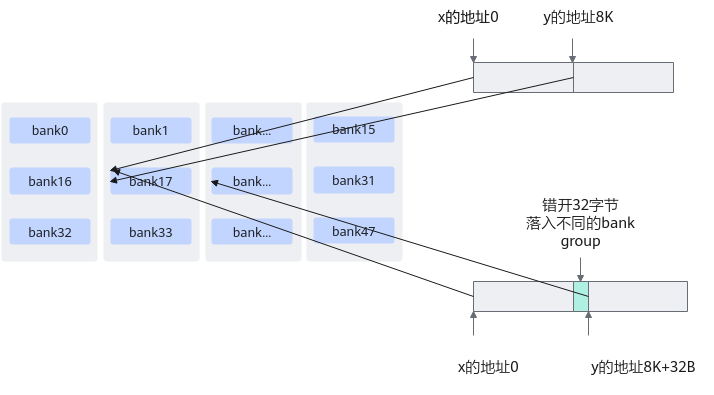
如果在申请的一块workBuffer中有两个输入向量,则两个向量的起始地址不能在同一个bank group中,避免方法为:多申请32B字节LocalTensor,使得workBuffer的2个输入错开32字节。
例如,计算z = x + y时,x从workBuffer0地址开始,长度为8K字节,y从8k字节地址开始,长度为8K字节,则x和y的物理地址会落到同一块bank中。在分配地址中,增加一定长度,可避免bank冲突,示例代码和地址分配示意图如下:
1 2 3 4 |
LocalTensor<float> srcLocal; LocalTensor<float> dstLocal; UnaryRepeatParams params; AscendC::Add(dstLocal, srcLocal[0], srcLocal[(8 * 1024 + 32) / sizeof(float)], mask, (8 * 1024) / 256 , params); |