非对齐场景
数据搬运和Vector计算的对齐要求

进行数据搬运和Vector计算时,对于搬运的数据长度和操作数的起始地址有如下的对齐要求:
- 使用DataCopy接口进行数据搬运,搬运的数据长度和操作数的起始地址必须保证32字节对齐。
- 进行Vector计算时,操作数的起始地址必须保证32字节对齐。
下文描述中的Global代指Global Memory,Local代指Local Memory。
下面是一些非对齐搬运和计算的例子。
- 非对齐搬入
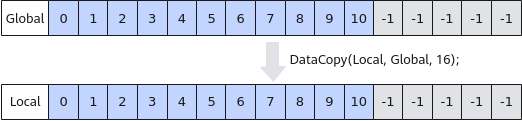
当需要从Global拷贝11个half数值到Local时,为保证搬运的数据长度32字节对齐,使用DataCopy将拷贝16个half(32B)数据到Local上,Local[11]~Local[15]被写成无效数据-1。图1 非对齐搬入内存
- 非对齐搬出
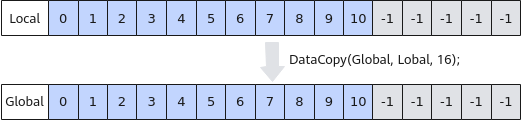
当需要从Local拷贝11个half数值到Global时,为保证搬运的数据长度32字节对齐,使用DataCopy将拷贝16个half(32B)数据到Global上,Global[11]~Global[15]被写成无效数据-1。图2 非对齐搬出内存
- 矢量计算起始地址非32字节对齐的错误示例
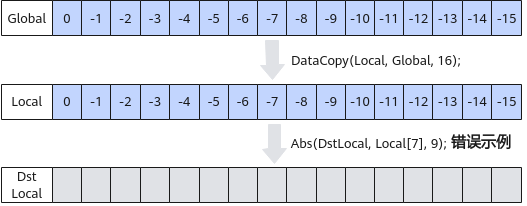
矢量计算时需要保证起始地址32字节对齐,如下的示例中,从Local[7],即LocalTensor的第8个数开始计算,起始地址不满足32字节对齐,是错误示例。图3 矢量计算起始地址非32字节对齐的错误示例
非对齐处理方案
DataCopyPad接口提供非对齐搬运的功能,如果基于该接口支持的产品开发算子(参见支持的型号),则可以直接使用该接口解决非对齐场景下的搬运问题。但部分型号不支持DataCopyPad接口,则需要参考如下的方案处理。
- Global上逐行搬运长度不对齐数据到Local中,导致Local中每行都存在冗余数据
- 冗余数据参与计算
如下图所示,将前11个half数据进行Abs计算,冗余数据可以参与计算,不影响最终结果,该种方式主要用于elemwise计算,这里步骤为:
- 使用DataCopy搬运16个half数据到Local中;
- 直接使用Abs做整块计算,可以不用计算尾块大小。
图4 冗余数据参与计算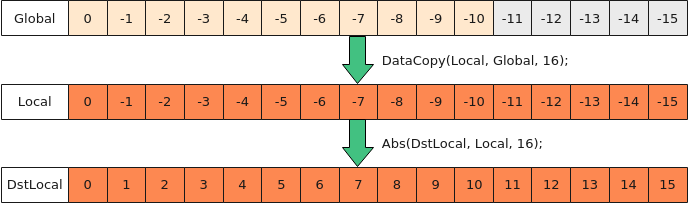
- 使用mask掩掉脏数据,一般用于轴归约计算等
如下图所示,假设输入数据的Shape为16*4,将输入数据搬入到UB后每行数据前4个half数据为有效数据,其余为冗余数据。为只对前4个half数据进行ReduceMin计算,且保证冗余数据不参与到计算,可以通过设置ReduceMin API的mask参数的方法掩盖掉脏数据。这里步骤为:
- 使用DataCopy搬运16个half数据到Local中;
- 对归约计算的目的操作数DstLocal清零,如使用Duplicate等;
- 进行归约操作,将ReduceMin的mask模式设置为前4个数据有效,来掩掉对冗余数据区域的处理。
图5 冗余数据不参与计算
- 搬入Local中,逐行调用基础API Duplicate,脏数据位置填充0值
如下图所示,对于搬入后的非对齐数据,逐行进行Duplicate清零处理,步骤为:
- 使用DataCopy搬运16个half数据到Local;
- 使用高阶API Duplicate,按照如下方式设置mask值,控制仅后5个元素位置有效,将冗余数据填充为0。
uint64_t mask0 = ((uint64_t)1 << 16) - ((uint64_t)1 << 11); uint64_t mask[2] = {mask0, 0};
图6 逐行填充0值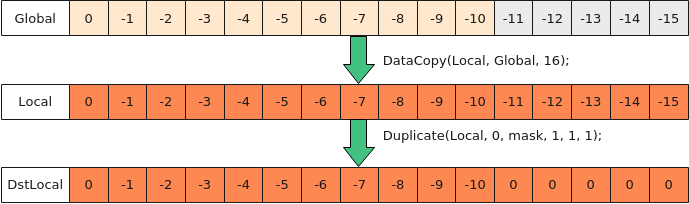
- 冗余数据参与计算
- Global搬运非对齐数据到Local, 逐行搬入后,Pad成0值
如下图所示,将Local内16*16大小的数据块进行脏数据清零,逐行清零性能会很差,可以使用Pad一次性清零,步骤为:
图7 使用Pad接口补齐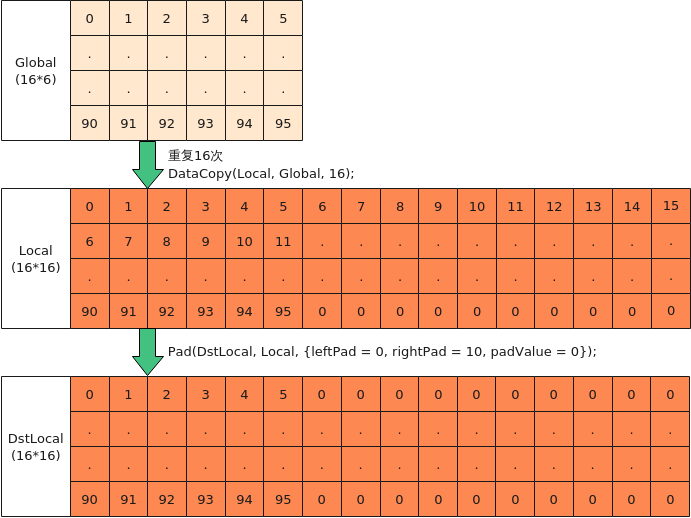
- Local非对齐拷贝出Global,拷贝长度大于32B
- Local中存在冗余数据,如果有效数据为32B整除,使用UnPad接口去除冗余数据并完整搬出
如下图所示,Local内存为16*16, 需要将16*6的有效内存搬到Global中,步骤如下:
图8 使用UnPad去除冗余值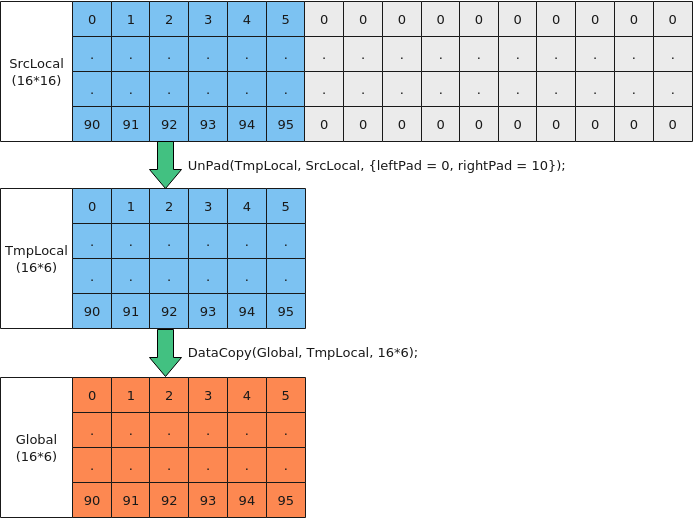
- 使用GatherMask处理
如下图所示,为搬出19个half数据到Global中,使用GatherMask处理,步骤如下:
- 完整拷贝前16个half(32B)数据到Global中;
- 使用GatherMask接口,将SrcLocal[4]~[19]的数Gather到TmpLocal中,TmpLocal从对齐地址开始;
- 从TmpLocal中搬运Gather的数据(32B整数倍)到Global中。
图9 使用GatherMask借位搬运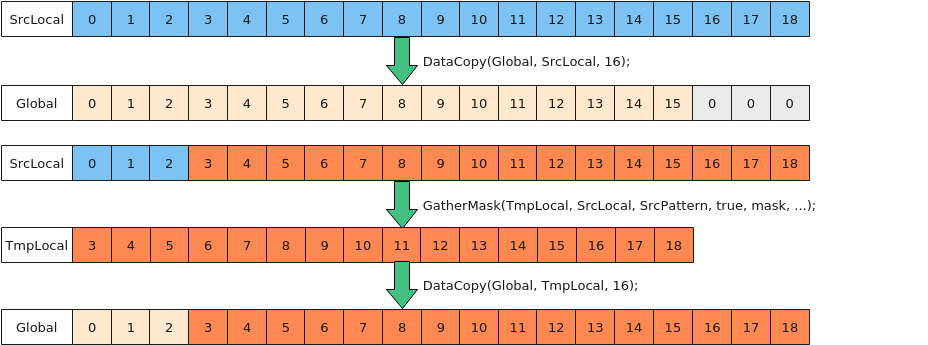
- Local中存在冗余数据,如果有效数据为32B整除,使用UnPad接口去除冗余数据并完整搬出
- Local非对齐拷贝出Global, 拷贝长度小于32B
- 将目标Global完整清零,可以通过在Host清零或者在Kernel侧用UB覆盖的方式处理;
- 将本核内的Local数据,除了要搬出的4个有效数,其余冗余部分清零(使用Duplicate);
- 使用atomic累加的方式拷贝到Global,因为冗余数据已被清成0值,所以不会出现数据踩踏。
图10 使用atomic累加的方式处理拷贝长度小于32B的场景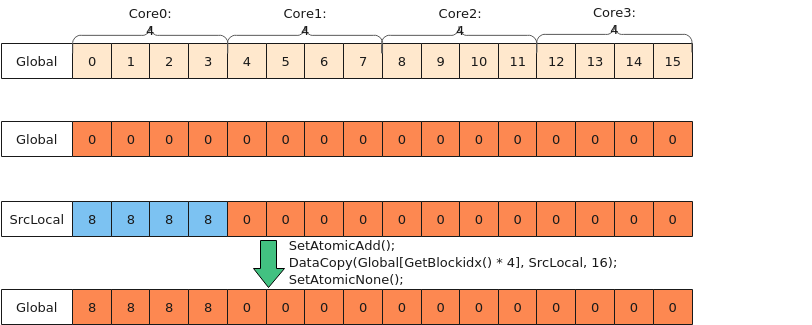
父主题: 矢量编程