Sum
功能说明
获取最后一个维度的元素总和。
如果输入是向量,则在向量中对各元素相加;如果输入是矩阵,则沿最后一个维度对每行中元素求和。本接口最多支持输入为二维数据,不支持更高维度的输入。
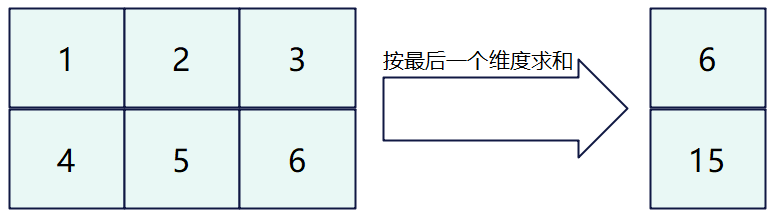
如下图所示,对shape为(2, 3)的二维矩阵进行运算,输出结果为[[ 6] [15]]。
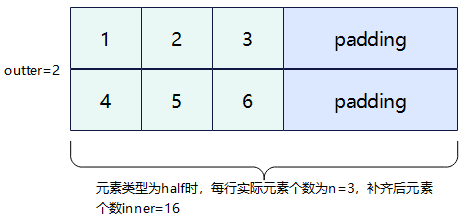
为计算如上过程,引入一些必备概念:行数称之为外轴长度(outter),每行实际的元素个数称之为内轴的实际元素个数(n),存储n个元素所需的字节长度向上补齐到32整数倍后转换的元素个数称之为补齐后的内轴元素个数(inner)。本接口要求输入的内轴长度为32字节的整数倍,所以当n占据的字节长度不是32的整数倍时,需要开发者将其向上补齐到32的整数倍。比如,如下的样例中,元素类型为half,每行的实际元素个数n为3,占据字节长度为6字节,不是32字节的整数倍,向上补齐后得到32字节,转换为元素个数为16。故outter = 2,n =3,inner=16。图中的padding代表补齐操作。n和inner的关系如下:inner = (n *sizeof(T) + 32 - 1) / 32 * 32 / sizeof(T)。
函数原型
- 通过sharedTmpBuffer入参传入临时空间
1 2 3
template <typename T, int32_t reduceDim = -1, bool isReuseSource = false, bool isBasicBlock = false> __aicore__ inline void Sum(const LocalTensor<T> &dstTensor, const LocalTensor<T> &srcTensor, const LocalTensor<uint8_t> &sharedTmpBuffer, const SumParams &sumParams)
- 接口框架申请临时空间
1 2
template <typename T, int32_t reduceDim = -1, bool isReuseSource = false, bool isBasicBlock = false> __aicore__ inline void Sum(const LocalTensor<T> &dstTensor, const LocalTensor<T> &srcTensor, const SumParams &sumParams)
由于该接口的内部实现中涉及复杂的数学计算,需要额外的临时空间来存储计算过程中的中间变量。临时空间支持开发者通过sharedTmpBuffer入参传入和接口框架申请两种方式。
- 通过sharedTmpBuffer入参传入,使用该tensor作为临时空间进行处理,接口框架不再申请。该方式开发者可以自行管理sharedTmpBuffer内存空间,并在接口调用完成后,复用该部分内存,内存不会反复申请释放,灵活性较高,内存利用率也较高。
- 接口框架申请临时空间,开发者无需申请,但是需要预留临时空间的大小。
通过sharedTmpBuffer传入的情况,开发者需要为tensor申请空间;接口框架申请的方式,开发者需要预留临时空间。临时空间大小BufferSize的获取方式如下:通过Sum Tiling中提供的接口获取需要预留空间范围的大小。
参数说明
|
参数名 |
描述 |
|---|---|
|
T |
操作数的数据类型。 |
|
reduceDim |
用于指定按数据的哪一维度进行求和。本接口按最后一个维度实现,不支持reduceDim参数,传入默认值-1即可。 |
|
isReuseSource |
是否允许修改源操作数。该参数预留,传入默认值false即可。 |
|
isBasicBlock |
srcTensor和dstTensor的shape信息和Tiling切分策略满足基本块要求的情况下,可以使能该参数用于提升性能,默认不使能。基本块要求srcTensor和dstTensor的shape需要满足如下条件:
|
|
参数名 |
输入/输出 |
描述 |
|---|---|---|
|
dstTensor |
输出 |
目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float 输出值需要outter * sizeof(T)大小的空间进行保存。开发者要根据该大小和框架的对齐要求来为dstTensor分配实际内存空间。
说明:
注意:遵循框架对内存开辟的要求(开辟内存的大小满足32Byte对齐),即outter * sizeof(T)不是32Byte对齐时,需要向上进行32Byte对齐。为了对齐而多开辟的内存空间不填值,为一些随机值。 |
|
srcTensor |
输入 |
源操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 源操作数的数据类型需要与目的操作数保持一致。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:half/float Atlas推理系列产品AI Core,支持的数据类型为:half/float |
|
sharedTmpBuffer |
输入 |
临时缓存。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 用于Sum内部复杂计算时存储中间变量,由开发者提供。 临时空间大小BufferSize的获取方式请参考Sum Tiling。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:uint8_t Atlas推理系列产品AI Core,支持的数据类型为: uint8_t |
|
sumParams |
输入 |
srcLocal的shape信息。SumParams类型,具体定义如下: struct SumParams{
uint32_t outter = 1; // 表示输入数据的外轴长度
uint32_t inner; // 表示输入数据内轴的补齐后元素个数,inner*sizeof(T)必须是32字节的整数倍
uint32_t n; // 表示输入数据内轴的实际元素个数
};
|
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas推理系列产品AI Core
约束说明
- 操作数地址偏移对齐要求请参见通用约束。
- 不支持源操作数与目的操作数地址重叠。
- 不支持sharedTmpBuffer与源操作数和目的操作数地址重叠。
- 当前仅支持ND格式的输入,不支持其他格式。
- 一维输入的outter值填为1;二维输入按实际情况填写outter和n,inner计算请按如上公式计算,否则功能不正确。
- srcTensor需要能够容纳内轴对齐后的数据占用空间大小,dstTensor需要能够容纳outter个结果对齐后的数据占用空间大小。
- 对于Sum,其内部使用的底层相加方式和ReducceSum以及WholeReducceSum的内部的相加方式一致,采用二叉树方式,两两相加:
假设源操作数为128个float16的数据[data0,data1,data2...data127],一个repeat可以计算完,计算过程如下。
- data0和data1相加得到data00,data2和data3相加得到data01...data124和data125相加得到data62,data126和data127相加得到data63;
- data00和data01相加得到data000,data02和data03相加得到data001...data62和data63相加得到data031;
- 以此类推,得到目的操作数为1个float16的数据[data]。
调用示例
kernel侧实现:sum_custom.cpp:
#include "kernel_operator.h"
template <typename T>
class KernelSumCustom
{
public:
__aicore__ inline KernelSumCustom() {}
__aicore__ inline void Init(__gm__ uint8_t *src1Gm, __gm__ uint8_t *dstGm, uint32_t tmpSize, uint32_t outter, uint32_t inner, uint32_t n)
{
elementNumPerBlk = AscendC::ONE_BLK_SIZE / sizeof(T); // half=16 float=8
elementNumPerRep = AscendC::ONE_REPEAT_BYTE_SIZE / sizeof(T);
width = inner;
height = outter;
nNum = n;
src1Global.SetGlobalBuffer((__gm__ T *)src1Gm);
dstGlobal.SetGlobalBuffer((__gm__ T *)dstGm);
pipe.InitBuffer(inQueueSrc1, 1, height * width * sizeof(T));
pipe.InitBuffer(outQueueDst, 1, (height * sizeof(T) + AscendC::ONE_BLK_SIZE - 1) / AscendC::ONE_BLK_SIZE * AscendC::ONE_BLK_SIZE);
pipe.InitBuffer(workQueue, 1, tmpSize);
}
__aicore__ inline void Process()
{
CopyIn();
Compute();
CopyOut();
}
private:
__aicore__ inline void CopyIn()
{
AscendC::LocalTensor<T> srcLocal1 = inQueueSrc1.AllocTensor<T>();
AscendC::DataCopy(srcLocal1, src1Global, height * width);
inQueueSrc1.EnQue(srcLocal1);
}
__aicore__ inline void Compute()
{
AscendC::LocalTensor<T> srcLocal1 = inQueueSrc1.DeQue<T>();
AscendC::LocalTensor<uint8_t> workLocal = workQueue.AllocTensor<uint8_t>();
AscendC::LocalTensor<T> dstLocal = outQueueDst.AllocTensor<T>();
AscendC::SumParams params{height, width, nNum};
T scalar(0);
AscendC::Duplicate<T>(dstLocal, scalar, (height * sizeof(T) + AscendC::ONE_BLK_SIZE - 1) / AscendC::ONE_BLK_SIZE * AscendC::ONE_BLK_SIZE / sizeof(T));
AscendC::Sum(dstLocal, srcLocal1, params);
outQueueDst.EnQue<T>(dstLocal);
workQueue.FreeTensor(workLocal);
inQueueSrc1.FreeTensor(srcLocal1);
}
__aicore__ inline void CopyOut()
{
AscendC::LocalTensor<T> dstLocal = outQueueDst.DeQue<T>();
AscendC::DataCopy(dstGlobal, dstLocal, (height * sizeof(T) + AscendC::ONE_BLK_SIZE - 1) / AscendC::ONE_BLK_SIZE * AscendC::ONE_BLK_SIZE / sizeof(T));
outQueueDst.FreeTensor(dstLocal);
}
private:
AscendC::TPipe pipe;
AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueSrc1;
AscendC::TQue<AscendC::QuePosition::VECIN, 1> workQueue;
AscendC::TQue<AscendC::QuePosition::VECOUT, 1> outQueueDst;
AscendC::GlobalTensor<T> src1Global, dstGlobal;
uint32_t elementNumPerBlk = 0;
uint32_t elementNumPerRep = 0;
uint32_t width = 0;
uint32_t height = 0;
uint32_t nNum = 0;
};
extern "C" __global__ __aicore__ void sum_custom(GM_ADDR x, GM_ADDR y, GM_ADDR workspace, GM_ADDR tiling)
{
GET_TILING_DATA(tiling_data, tiling);
KernelSumCustom<DTYPE_X> op;
op.Init(x, y, tiling_data.size, tiling_data.outter, tiling_data.inner, tiling_data.n);
op.Process();
}
host侧实现:sum_custom_tiling.h:
#include "register/tilingdata_base.h"
namespace optiling
{
BEGIN_TILING_DATA_DEF(SumCustomTilingData)
TILING_DATA_FIELD_DEF(uint32_t, size);
TILING_DATA_FIELD_DEF(uint32_t, outter);
TILING_DATA_FIELD_DEF(uint32_t, inner);
TILING_DATA_FIELD_DEF(uint32_t, n);
END_TILING_DATA_DEF;
REGISTER_TILING_DATA_CLASS(SumCustom, SumCustomTilingData)
}
sum_custom.cpp:
#include "sum_custom_tiling.h"
#include "register/op_def_registry.h"
#include "tiling/tiling_api.h"
namespace optiling
{
static ge::graphStatus TilingFunc(gert::TilingContext *context)
{
SumCustomTilingData tiling;
const gert::RuntimeAttrs *sumattrs = context->GetAttrs();
const uint32_t tmp = *(sumattrs->GetAttrPointer<uint32_t>(0));
const uint32_t outter = *(sumattrs->GetAttrPointer<uint32_t>(1));
const uint32_t inner = *(sumattrs->GetAttrPointer<uint32_t>(2));
uint32_t n = *(sumattrs->GetAttrPointer<uint32_t>(3));
auto dt = context->GetInputTensor(0)->GetDataType();
tiling.set_outter(outter); // 往结构体设置
tiling.set_inner(inner);
tiling.set_n(n);
uint32_t maxValue = 0;
uint32_t minValue = 0;
uint32_t dtypesize;
if (dt == ge::DT_FLOAT16) {
dtypesize = 2;
} else {
dtypesize = 4;
}
AscendC::GetSumMaxMinTmpSize(n, dtypesize, false, maxValue, minValue);
tiling.set_size(minValue);
context->SetBlockDim(8);
tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity());
context->GetRawTilingData()->SetDataSize(tiling.GetDataSize());
size_t *currentWorkspace = context->GetWorkspaceSizes(1);
currentWorkspace[0] = 0;
return ge::GRAPH_SUCCESS;
}
}
namespace ge
{
static ge::graphStatus InferShape(gert::InferShapeContext *context)
{
const gert::Shape *x1_shape = context->GetInputShape(0);
gert::Shape *y_shape = context->GetOutputShape(0);
*y_shape = *x1_shape;
return GRAPH_SUCCESS;
}
}
namespace ops
{
class SumCustom : public OpDef
{
public:
explicit SumCustom(const char *name) : OpDef(name)
{
this->Input("x")
.ParamType(REQUIRED)
.DataType({ge::DT_FLOAT16})
.Format({ge::FORMAT_ND});
this->Output("y")
.ParamType(REQUIRED)
.DataType({ge::DT_FLOAT16})
.Format({ge::FORMAT_ND});
this->Attr("size")
.AttrType(REQUIRED)
.Int(0);
this->Attr("outter")
.AttrType(REQUIRED)
.Int(0);
this->Attr("inner")
.AttrType(REQUIRED)
.Int(0);
this->Attr("n")
.AttrType(REQUIRED)
.Int(0);
this->SetInferShape(ge::InferShape);
this->AICore()
.SetTiling(optiling::TilingFunc);
this->AICore().AddConfig("ascendxxx"); // ascendxxx请修改为对应的昇腾AI处理器型号。
}
};
OP_ADD(SumCustom);
} // namespace ops
结果示例如下:
输入数据(srcLocal): [[1 2 3 0 0 0 0 0 0 0 0 0 0 0 0 0],
[4 5 6 0 0 0 0 0 0 0 0 0 0 0 0 0]]
输出数据(dstLocal): [6 15 0 0 0 0 0 0 0 0 0 0 0 0 0 0]