图像分割应用样例开发介绍(Python)
本章节介绍基于AscendCL接口如何开发一个基于Unet++模型的图像分割样例。
样例介绍
图像分割应用,即将图片各个部分进行识别划分。

本例中使用的是开源数据集训练的Unet++图片分割模型(参见ModelZoo-PyTorch-Unet++)。可以直接使用训练好的开源模型,也可以基于开源模型的源码进行修改、重新训练,还可以基于算法、框架构建适合的模型。
- 输入数据:RGB格式图片,分辨率为 96*96,输入形状为(1,3,96,96),也即(batchsize,channel,height,width)。
- 输出数据:分割结果灰度图,分辨率也为 96*96,输入形状为(1,1,96,96),也即(batchsize,channel,height,width)。

输出数组需要经过一定后处理,才能显示为正常的图片。
业务模块介绍
业务模块的操作流程如图2所示。

- 图片输入:收集待分割的数据集做为输入数据。
- 输入预处理:将图片或视频读入为数组,并缩放到模型所需大小,然后调整像素范围。
- 模型推理:经过模型推理后得到图片分割结果。
- 后处理:调整模型输出值的范围,将其缩放到原始图片大小,并在原始图像上画出分割结果。
- 可视化或保存到文件:将分割后的图片显示在界面或保存到文件。
获取代码
- 获取代码文件。
单击获取链接或使用wget命令获取代码(使用wget时需确保开发者套件能够连接外网),下载代码文件压缩包,以root用户登录开发者套件。
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Atlas%20200I%20DK%20A2/DevKit/models/sdk_cal_samples/Unetplusplus_acl_sample.zip
- 将“Unetplusplus_acl_sample.zip”压缩包上传到开发者套件,解压并进入解压后的目录。
unzip Unetplusplus_acl_sample.zip cd Unetplusplus_acl_sample
代码目录结构如下所示,按照正常开发流程,需要将框架模型文件转换成昇腾AI处理器支持推理的om格式模型文件,鉴于当前是入门内容,用户可直接获取已转换好的om模型进行推理。
|-- Unetplusplus_acl_sample |-- unetplusplus.om # om模型 |-- main.py # 主程序 |-- img.png # 测试图片
代码解析
开发代码过程中,在“Unetplusplus_acl_sample/main.py”文件中已包含读入数据、前处理、推理、后处理等功能,串联整个应用代码逻辑,此处仅对代码进行解析。
- 在“main.py”文件的开头有如下代码,导入需要的第三方库以及调用AscendCL接口推理所需文件。
# 引用库 #!/usr/bin/python # -*- coding: utf-8 -*- import cv2 # 图片处理三方库,用于对图片进行前后处理 import numpy as np # 用于对多维数组进行计算 from albumentations.augmentations import transforms # 数据增强库,用于对图片进行变换 import acl # AscnedCL推理所需库文件 import constants as const # 其中包含acl相关状态值,用于判断推理时程序状态是否正常
- 定义模型相关变量,如图片路径、模型路径、类别数量等,并进行acl的资源初始化,使用AscendCL接口开发应用时,必须先初始化AscendCL,否则可能会导致后续系统内部资源初始化出错,进而导致其它业务异常。
# 初始化变量 pic_input = 'img.png' # 单张图片 model_path = "unetplusplus.om" # 模型路径 num_class = 1 # 类别数量, 需要根据模型结构、任务类别进行改变; 此处只分割出细胞, 即为一分类 device_id = 0 # 指定运算的Device # acl初始化 print("init resource stage:") ret = acl.init() ret = acl.rt.set_device(device_id) # 指定运算的Device context, ret = acl.rt.create_context(device_id) # 显式创建一个Context print("Init resource success") - 模型加载。使用acl接口加载om模型。
# 加载模型 model_id, ret = acl.mdl.load_from_file(model_path) # 加载离线模型文件, 返回标识模型的ID model_desc = acl.mdl.create_desc() # 初始化模型描述信息, 包括模型输入个数、输入维度、输出个数、输出维度等信息 ret = acl.mdl.get_desc(model_desc, model_id) # 根据加载成功的模型的ID, 获取该模型的描述信息 print("Init model resource success") - 准备输入数据集。先使用opencv读入图片,得到三维数组,再进行相应的图片大小缩放、像素值缩放等处理,并将其转化为模型推理所需要的数据集格式。
# 前处理 img_bgr = cv2.imread(pic_input) # 读入图片 img = cv2.resize(img_bgr, (96, 96)) # 将原图缩放到 96*96 大小 img= transforms.Normalize().apply(img) # 将像素值标准化(减去均值除以方差) img = img.astype('float32') / 255 # 将像素值缩放到 0~1 范围内 img = img.transpose(2, 0, 1) # 将形状转换为 channel first (3, 96, 96) # 准备输入数据集 input_buffer = [] # 初始化输入buffer列表 input_list = [img, ] # 初始化输入数据列表 input_num = acl.mdl.get_num_inputs(model_desc) # 得到模型输入个数 for i in range(input_num): # 根据模型输入个数, 初始化输入 buffer item = {"addr": None, "size": 0} # 每个输入的地址、所占字节数 input_buffer.append(item) # 加入buffer列表 input_dataset = acl.mdl.create_dataset() # 创建输入数据 for i in range(input_num): input_data = input_list[i] # 得到每个输入数据 # 得到每个输入数据流的指针(input_ptr)和所占字节数(size) size = input_data.size * input_data.itemsize # 得到所占字节数 bytes_data=input_data.tobytes() # 将每个输入数据转换为字节流 input_ptr=acl.util.bytes_to_ptr(bytes_data) # 得到输入数据指针 model_size = acl.mdl.get_input_size_by_index(model_desc, i) # 从模型信息中得到输入所占字节数 if size != model_size: # 判断所分配的内存是否和模型的输入大小相符 print(" Input[%d] size: %d not equal om size: %d" % (i, size, model_size) + ", may cause inference result error, please check model input") dataset_buffer = acl.create_data_buffer(input_ptr, size) # 为每个输入创建 buffer _, ret = acl.mdl.add_dataset_buffer(input_dataset, dataset_buffer) # 将每个 buffer 添加到输入数据中 print("Create model input dataset success") - 准备输出数据集。构造输出数据集数据结构,为其分配内存,为之后的推理步骤做准备。
# 准备输出数据集 output_size = acl.mdl.get_num_outputs(model_desc) # 得到模型输出个数 output_dataset = acl.mdl.create_dataset() # 创建输出数据 for i in range(output_size): size = acl.mdl.get_output_size_by_index(model_desc, i) # 得到每个输出所占内存大小 buf, ret = acl.rt.malloc(size, const.ACL_MEM_MALLOC_NORMAL_ONLY) # 为输出分配内存 dataset_buffer = acl.create_data_buffer(buf, size) # 为每个输出创建 buffer _, ret = acl.mdl.add_dataset_buffer(output_dataset, dataset_buffer) # 将每个 buffer 添加到输出数据中 if ret: # 若分配出现错误, 则释放内存 acl.rt.free(buf) acl.destroy_data_buffer(dataset_buffer) print("Create model output dataset success") - 使用acl接口进行模型推理,得到模型输出结果。
# 模型推理, 得到的输出将写入 output_dataset 中 ret = acl.mdl.execute(model_id, input_dataset, output_dataset) if ret != const.ACL_SUCCESS: # 判断推理是否出错 print("Execute model failed for acl.mdl.execute error ", ret) - 对模型输出进行解析,再进行后处理,保存推理后的图片。由于模型推理后的数据以buffer的形式存储在output_dataset中,需要将其提取出,并转换为利于处理的numpy数组,再进行后处理。后处理步骤即将像素值变换到 0~1范围内后,再将其画在原图上,得到最终可以用于显示的的分割结果。
# 解析 output_dataset, 得到模型输出列表 model_output = [] # 模型输出列表 for i in range(output_size): buf = acl.mdl.get_dataset_buffer(output_dataset, i) # 获取每个输出buffer data_addr = acl.get_data_buffer_addr(buf) # 获取输出buffer的地址 size = int(acl.get_data_buffer_size(buf)) # 获取输出buffer的字节数 byte_data = acl.util.ptr_to_bytes(data_addr, size) # 将指针转为字节流数据 dims = tuple(acl.mdl.get_output_dims(model_desc, i)[0]["dims"]) # 从模型信息中得到每个输出的维度信息 output_data = np.frombuffer(byte_data, dtype=np.float32).reshape(dims) # 将 output_data 以流的形式读入转化成 ndarray 对象 model_output.append(output_data) # 添加到模型输出列表 # 后处理 model_out_msk = model_output[0] # 取出模型推理结果, 推理结果形状为 (1, 1, 96, 96),即(batchsize, num_class, height, width) model_out_msk = sigmoid(model_out_msk[0][0]) # 将模型输出变换到 0~1 范围内 img_to_save = plot_mask(img_bgr, model_out_msk) # 将处理后的输出画在原图上, 并返回 # 保存图片到文件 cv2.imwrite('result.png', img_to_save) - 释放输入、输出、模型等资源。
# 释放输入资源, 包括数据结构和内存 num = acl.mdl.get_dataset_num_buffers(input_dataset) # 获取输入个数 for i in range(num): data_buf = acl.mdl.get_dataset_buffer(input_dataset, i) # 获取每个输入buffer if data_buf: ret = acl.destroy_data_buffer(data_buf) # 销毁每个输入buffer (销毁 aclDataBuffer 类型) ret = acl.mdl.destroy_dataset(input_dataset) # 销毁输入数据 (销毁 aclmdlDataset类型的数据) # 释放输出资源, 包括数据结构和内存 num = acl.mdl.get_dataset_num_buffers(output_dataset) # 获取输出个数 for i in range(num): data_buf = acl.mdl.get_dataset_buffer(output_dataset, i) # 获取每个输出buffer if data_buf: ret = acl.destroy_data_buffer(data_buf) # 销毁每个输出buffer (销毁 aclDataBuffer 类型) ret = acl.mdl.destroy_dataset(output_dataset) # 销毁输出数据 (销毁 aclmdlDataset类型的数据) # 卸载模型 if model_id: ret = acl.mdl.unload(model_id) # 释放模型描述信息 if model_desc: ret = acl.mdl.destroy_desc(model_desc) # 释放 Context if context: acl.rt.destroy_context(context) # 释放Device acl.rt.reset_device(device_id) acl.finalize() print("Release acl resource success") - 主体函数定义。
其中sigmoid函数用于将矩阵的每个元素变换到0~1范围内,plot_mask用于将得到的分割结果画在原图上。
以下代码定义了这两个函数功能。
def sigmoid(x): y = 1.0 / (1 + np.exp(-x)) # 对矩阵的每个元素执行 1/(1+e^(-x)) return y def plot_mask(img, msk): """ 将推理得到的 mask 覆盖到原图上 """ msk = msk + 0.5 # 将像素值范围变换到 0.5~1.5, 有利于下面转为二值图 msk = cv2.resize(msk, (img.shape[1], img.shape[0])) # 将 mask 缩放到原图大小 msk = np.array(msk, np.uint8) # 转为二值图, 只包含 0 和 1 # 从 mask 中找到轮廓线, 其中第二个参数为轮廓检测的模式, 第三个参数为轮廓的近似方法 # cv2.RETR_EXTERNAL 表示只检测外轮廓, cv2.CHAIN_APPROX_SIMPLE 表示压缩水平方向、 # 垂直方向、对角线方向的元素, 只保留该方向的终点坐标, 例如一个矩形轮廓只需要4个点来保存轮廓信息 # contours 为返回的轮廓(list) contours, _ = cv2.findContours(msk, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 在原图上画出轮廓, 其中 img 为原图, contours 为检测到的轮廓列表 # 第三个参数表示绘制 contours 中的哪条轮廓, -1 表示绘制所有轮廓 # 第四个参数表示颜色, (0, 0, 255)表示红色, 第五个参数表示轮廓线的宽度 cv2.drawContours(img, contours, -1, (0, 0, 255), 1) # 将轮廓线以内(即分割区域)覆盖上一层红色 img[..., 2] = np.where(msk == 1, 255, img[..., 2]) return img
运行推理
python main.py
界面显示结果如下。
init resource stage: Init resource success Init model resource success Create model input dataset success Create model output dataset success Release acl resource success
推理完成后,在当前文件夹下生成“result.png”文件,如图3所示。
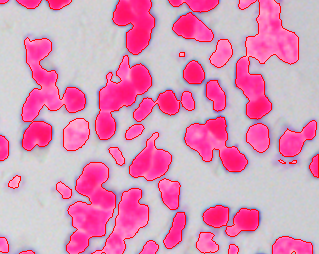
样例总结与扩展
以上代码包括以下几个步骤:
从AscendCL初始化、指定计算设备,到加载模型、准备测试数据,再到执行推理、处理推理的结果数据,最后到释放各类资源,包括卸载模型、释放内存、销毁各种数据类型等,最后释放指定的计算设备、进行AscendCL去初始化
1. 初始化acl资源:此样例中,包括指定计算设备、创建context、创建stream等操作,再进行了模型的加载。
2. 前处理:包括缩放、标准化、数据类型转换以及维度转换等操作。
3. 推理:包括准备输入数据集结构、准备输出数据集结构、并利用acl.mdl.execute()接口进行推理等,并将结果解析为numpy array类型。
4. 后处理:包括sigmoid变换以及将输出画在原图上,并保存图片。
5. 资源销毁:最后记得释放相关资源,包括卸载模型、销毁输入输出数据集、释放 Context、释放指定的计算设备、以及AscendCL去初始化等操作。
AscendCL接口分类总结:
分类 |
接口函数 |
描述 |
|---|---|---|
AscendCL初始化相关 |
acl.init() |
pyACL初始化函数 |
acl.rt.set_device(device_id) |
指定当前进程或线程中用于运算的Device,同时隐式创建默认Context |
|
acl.rt.create_context(device_id) |
在当前进程或线程中显式创建一个Context |
|
模型描述信息相关 |
acl.mdl.load_from_file(model_path) |
从文件加载离线模型数据(适配昇腾AI处理器的离线模型) |
acl.mdl.create_desc() |
创建aclmdlDesc类型的数据 |
|
acl.mdl.get_desc(model_desc, model_id) |
根据模型ID获取该模型的aclmdlDesc类型数据 |
|
acl.mdl.get_num_inputs(model_desc) |
根据aclmdlDesc类型的数据,获取模型的输入个数 |
|
acl.mdl.get_num_outputs(model_desc) |
根据aclmdlDesc类型的数据,获取模型的输出个数 |
|
acl.mdl.get_output_size_by_index(model_desc, i) |
根据aclmdlDesc类型的数据,获取指定输出的大小,单位为Byte |
|
acl.mdl.get_output_dims(model_desc, i) |
根据模型描述信息获取指定的模型输出tensor的维度信息 |
|
数据集结构相关 |
acl.mdl.create_dataset() |
创建aclmdlDataset类型的数据 |
acl.create_data_buffer(data_addr, size) |
创建aclDataBuffer类型的数据,该数据类型用于描述内存地址、大小等内存信息 |
|
acl.mdl.add_dataset_buffer(dataset, date_buffer) |
向aclmdlDataset中增加aclDataBuffer |
|
acl.mdl.get_dataset_num_buffers(dataset) |
获取aclmdlDataset中aclDataBuffer的个数 |
|
acl.mdl.get_dataset_buffer(dataset, i) |
获取aclmdlDataset中的第i个aclDataBuffer |
|
acl.get_data_buffer_addr(buffer) |
获取aclDataBuffer类型中的数据的地址对象 |
|
acl.get_data_buffer_size(buffer) |
获取aclDataBuffer类型中数据的内存大小,单位Byte |
|
acl.util.bytes_to_ptr(bytes_data) |
将bytes对象转换成为void*数据,可以将转换好的数据传递给C函数直接使用 |
|
acl.util.ptr_to_bytes(ptr, size) |
将void*数据转换为bytes对象,可以使python代码直接访问 |
|
acl.rt.malloc(size, policy) |
申请Device上的内存 |
|
acl.rt.free(data_buffer) |
释放通过acl.rt.malloc申请的内存 |
|
推理相关 |
acl.mdl.execute(model_id, input_dataset, output_dataset) |
执行模型推理,直到返回推理结果 |
销毁资源相关 |
acl.destroy_data_buffer(data_buffer) |
销毁aclDataBuffer类型的数据 |
acl.mdl.destroy_dataset(dataset) |
销毁aclmdlDataset类型的数据 |
|
acl.mdl.unload(model_id) |
系统完成模型推理后,可调用该接口卸载模型,释放资源 |
|
acl.mdl.destroy_desc(model_desc) |
销毁aclmdlDesc类型的数据 |
|
acl.rt.destroy_context(context) |
销毁一个Context,释放Context的资源 |
|
acl.rt.reset_device(device_id) |
复位当前运算的Device,释放Device上的资源,包括默认Context、默认Stream以及默认Context下创建的所有Stream |
|
acl.finalize() |
pyACL去初始化函数,用于释放进程内的pyACL相关资源 |
理解各个接口含义后,用户可进行灵活运用。除此外,此样例中只示范了图片推理,若需要对视频流数据进行推理,可用三种方式输入视频流数据:USB摄像头、手机摄像头。具体使用方式可参考《摄像头拉流》,用户只需将前处理、推理及后处理代码放入摄像头推理代码的循环中即可,注意有些细节地方需进行相应修改,具体逻辑可参照图像分类应用中的样例总结与扩展。