aclnnGridSampler2D
接口原型
每个算子有两段接口,必须先调用“aclnnXxxGetWorkspaceSize”接口获取入参并根据计算流程计算所需workspace大小,再调用“aclnnXxx”接口执行计算。两段式接口如下:
- 第一段接口:aclnnStatus aclnnGridSampler2DGetWorkspaceSize(const aclTensor *input, const aclTensor *grid, int64_t interpolationMode, int64_t paddingMode, bool alignCorners, aclTensor *out, uint64_t *workspaceSize, aclOpExecutor **executor)
- 第二段接口:aclnnStatus aclnnGridSampler2D(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, const aclrtStream stream)
功能描述
算子功能:已知输入张量input和对应的flow-field网格grid,根据grid中每个位置提供的坐标信息(指input中pixel的坐标),将input中对应位置的像素值填充到grid指定位置。
假设input、grid、out的尺寸如下:
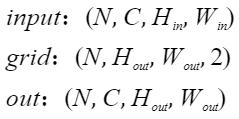
grid最后一维大小为2,即表示input中像素的位置信息为(x, y),一般会将x和y取值范围归一化到[-1, 1]之间,(-1, -1)表示左上角像素坐标,(1, 1)表示右下角像素坐标,对于超出这个范围的坐标(x, y),会根据paddingMode进行不同处理:
- paddingMode=0,表示对越界位置采用0进行填充。
- paddingMode=1,表示对越界位置采用边界值填充。
- paddingMode=2,表示对于越界位置采用边界值的对称值进行填充。
对input采样时,会根据interpolationMode进行不同处理:
- interpolationMode=0,如果(x, y)没有input对应坐标,则取(x, y)周围四个坐标进行加权平均值来取值。
- interpolationMode=1,表示取input中距离(x, y)最近的坐标值。
aclnnGridSampler2DGetWorkspaceSize
- 接口定义:
aclnnStatus aclnnGridSampler2DGetWorkspaceSize(const aclTensor *input, const aclTensor *grid, int64_t interpolationMode, int64_t paddingMode, bool alignCorners, aclTensor *out, uint64_t *workspaceSize, aclOpExecutor **executor)
- 参数说明:
- input:Device侧的aclTensor,数据类型支持FLOAT16、FLOAT、DOUBLE,支持非连续的Tensor,数据格式支持ND。
- grid:Device侧的aclTensor,数据类型支持FLOAT16、FLOAT、DOUBLE,需要和input类型保持一致,支持非连续的Tensor,数据格式支持ND。
- interpolationMode:Host侧的int64_t,表示插值模式,分别是0:bilinear(双线性插值)、1:nearest(最邻近插值)。
- paddingMode:Host侧的int64_t,表示填充模式。当(x, y)取值超过输入特征图采样范围,返回一个特定值,有0:zeros、1:border、2:reflection三种模式。
- alignCorners:Host侧的bool,表示设定特征图坐标与特征值的对应方式。设为True时,特征值位于像素中心。
- out:Device侧的aclTensor,数据类型支持FLOAT16、FLOAT、DOUBLE,支持非连续的Tensor,数据格式支持ND。
- workspaceSize:返回用户需要在Device侧申请的workspace大小。
- executor:返回op执行器,包含了算子计算流程。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。

第一段接口完成入参校验,出现以下场景时报错:
- 返回161001(ACLNN_ERR_PARAM_NULLPTR):传入的input、grid、out是空指针。
- 返回161002(ACLNN_ERR_PARAM_INVALID):
- input、grid和out的数据类型或数据格式不在支持的范围内。
- interpolationMode和paddingMode的值不在支持范围内。
- input、grid和out的维度关系不匹配。
- input最后两维为空。
aclnnGridSampler2D
- 接口定义:
aclnnStatus aclnnGridSampler2D(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, const aclrtStream stream)
- 参数说明:
- workspace:在Device侧申请的workspace内存起址。
- workspaceSize:在Device侧申请的workspace大小,由第一段接口aclnnGridSampler2DGetWorkspaceSize获取。
- executor:op执行器,包含了算子计算流程。
- stream:指定执行任务的AscendCL stream流。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。
调用示例
#include <iostream>
#include <vector>
#include "acl/acl.h"
#include "aclnnop/aclnn_grid_sampler2d.h"
#define CHECK_RET(cond, return_expr) \
do { \
if (!(cond)) { \
return_expr; \
} \
} while (0)
#define LOG_PRINT(message, ...) \
do { \
printf(message, ##__VA_ARGS__); \
} while (0)
int64_t GetShapeSize(const std::vector<int64_t>& shape) {
int64_t shapeSize = 1;
for (auto i : shape) {
shapeSize *= i;
}
return shapeSize;
}
int Init(int32_t deviceId, aclrtContext* context, aclrtStream* stream) {
// 固定写法,AscendCL初始化
auto ret = aclInit(nullptr);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclInit failed. ERROR: %d\n", ret); return ret);
ret = aclrtSetDevice(deviceId);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSetDevice failed. ERROR: %d\n", ret); return ret);
ret = aclrtCreateContext(context, deviceId);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtCreateContext failed. ERROR: %d\n", ret); return ret);
ret = aclrtSetCurrentContext(*context);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSetCurrentContext failed. ERROR: %d\n", ret); return ret);
ret = aclrtCreateStream(stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtCreateStream failed. ERROR: %d\n", ret); return ret);
return 0;
}
template <typename T>
int CreateAclTensor(const std::vector<T>& hostData, const std::vector<int64_t>& shape, void** deviceAddr,
aclDataType dataType, aclTensor** tensor) {
auto size = GetShapeSize(shape) * sizeof(T);
// 调用aclrtMalloc申请device侧内存
auto ret = aclrtMalloc(deviceAddr, size, ACL_MEM_MALLOC_HUGE_FIRST);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtMalloc failed. ERROR: %d\n", ret); return ret);
// 调用aclrtMemcpy将Host侧数据拷贝到device侧内存上
ret = aclrtMemcpy(*deviceAddr, size, hostData.data(), size, ACL_MEMCPY_HOST_TO_DEVICE);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtMemcpy failed. ERROR: %d\n", ret); return ret);
// 计算连续tensor的strides
std::vector<int64_t> strides(shape.size(), 1);
for (int64_t i = shape.size() - 2; i >= 0; i--) {
strides[i] = shape[i + 1] * strides[i + 1];
}
// 调用aclCreateTensor接口创建aclTensor
*tensor = aclCreateTensor(shape.data(), shape.size(), dataType, strides.data(), 0, aclFormat::ACL_FORMAT_ND, shape.data(), shape.size(), *deviceAddr);
return 0;
}
int main() {
// 1. (固定写法)device/context/stream初始化,参考AscendCL对外接口列表
// 根据自己的实际device填写deviceId
int32_t deviceId = 0;
aclrtContext context;
aclrtStream stream;
auto ret = Init(deviceId, &context, &stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("Init acl failed. ERROR: %d\n", ret); return ret);
// 2. 构造输入与输出,需要根据API的接口自定义构造
int64_t interpolationMode = 0;
int64_t paddingMode = 0;
bool alignCorners = false;
std::vector<int64_t> inputShape = {1, 1, 5, 8};
std::vector<int64_t> gridShape = {1, 3, 3, 2};
std::vector<int64_t> outShape = {1, 1, 3, 3};
void* inputDeviceAddr = nullptr;
void* gridDeviceAddr = nullptr;
void* outDeviceAddr = nullptr;
aclTensor* input = nullptr;
aclTensor* grid = nullptr;
aclTensor* out = nullptr;
std::vector<float> inputHostData = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40};
std::vector<float> gridHostData = {-1, -1, 0, -1, 1, -1, -1, 0, 0, 0, 1, 0, -1, 1, 0, 1, 1, 1};
std::vector<float> outHostData = {0, 0, 0, 0, 0, 0, 0, 0, 0};
// 创建input aclTensor
ret = CreateAclTensor(inputHostData, inputShape, &inputDeviceAddr, aclDataType::ACL_FLOAT, &input);
CHECK_RET(ret == ACL_SUCCESS, return ret);
// 创建grid aclTensor
ret = CreateAclTensor(gridHostData, gridShape, &gridDeviceAddr, aclDataType::ACL_FLOAT, &grid);
CHECK_RET(ret == ACL_SUCCESS, return ret);
// 创建out aclTensor
ret = CreateAclTensor(outHostData, outShape, &outDeviceAddr, aclDataType::ACL_FLOAT, &out);
CHECK_RET(ret == ACL_SUCCESS, return ret);
// 3. 调用CANN算子库API,需要修改为具体的API名称
uint64_t workspaceSize = 0;
aclOpExecutor* executor;
// 调用aclnnGridSampler2D第一段接口
ret = aclnnGridSampler2DGetWorkspaceSize(input, grid, interpolationMode, paddingMode, alignCorners, out, &workspaceSize, &executor);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclnnGridSampler2DGetWorkspaceSize failed. ERROR: %d\n", ret); return ret);
// 根据第一段接口计算出的workspaceSize申请device内存
void* workspaceAddr = nullptr;
if (workspaceSize > 0) {
ret = aclrtMalloc(&workspaceAddr, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("allocate workspace failed. ERROR: %d\n", ret); return ret);
}
// 调用aclnnGridSampler2D第二段接口
ret = aclnnGridSampler2D(workspaceAddr, workspaceSize, executor, stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclnnGridSampler2D failed. ERROR: %d\n", ret); return ret);
// 4. (固定写法)同步等待任务执行结束
ret = aclrtSynchronizeStream(stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSynchronizeStream failed. ERROR: %d\n", ret); return ret);
// 5. 获取输出的值,将device侧内存上的结果拷贝至Host侧,需要根据具体API的接口定义修改
auto size = GetShapeSize(outShape);
std::vector<float> resultData(size, 0);
ret = aclrtMemcpy(resultData.data(), resultData.size() * sizeof(resultData[0]),
outDeviceAddr, size * sizeof(resultData[0]), ACL_MEMCPY_DEVICE_TO_HOST);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("copy resultData from device to host failed. ERROR: %d\n", ret);
return ret);
for (int64_t i = 0; i < size; i++) {
LOG_PRINT("resultData[%ld] is: %f\n", i, resultData[i]);
}
// 6. 释放aclTensor,需要根据具体API的接口定义修改
aclDestroyTensor(input);
aclDestroyTensor(grid);
aclDestroyTensor(out);
return 0;
}
父主题: NN类算子接口