aclnnMoeFFN
接口原型
每个算子有两段接口,必须先调用“aclnnMoeFFNGetWorkspaceSize”接口获取入参并根据计算流程计算所需workspace大小,再调用“aclnnMoeFFN”接口执行计算。两段式接口如下:
- 第一段接口:aclnnStatus aclnnMoeFFNGetWorkspaceSize(const aclTensor *x, const aclIntArray *expertTokens, const aclTensor *weight1, const aclTensor *bias1, const aclTensor *weight2, const aclTensor *bias2, const aclTensor *scale, const aclTensor *offset, const aclTensor *deqScale1, const aclTensor *deqScale2, char *activation, const aclTensor *y, uint64_t *workspaceSize, aclOpExecutor **executor)
- 第二段接口:aclnnStatus aclnnMoeFFN(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream)
功能描述
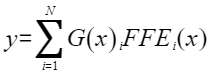
aclnnMoeFFNGetWorkspaceSize
- 接口定义:
aclnnStatus aclnnMoeFFNGetWorkspaceSize(const aclTensor *x, const aclIntArray *expertTokens, const aclTensor *weight1, const aclTensor *bias1, const aclTensor *weight2, const aclTensor *bias2, const aclTensor *scale, const aclTensor *offset, const aclTensor *deqScale1, const aclTensor *deqScale2, char *activation, const aclTensor *y, uint64_t *workspaceSize, aclOpExecutor **executor)
- 参数说明:
- x:Device侧的aclTensor,公式中的输入样本x,数据类型支持FLOAT16、INT8,数据格式支持ND,只支持输入为2维。
- expertTokens:Host侧的aclIntArray类型,代表各专家的评估权重,数据类型支持INT64,数据格式支持ND,支持的最大长度为256个。
- weight1:Device侧的aclTensor,专家的评估数据,数据类型支持FLOAT16、INT8,数据格式支持ND,输入为3维。
- bias1:Device侧的aclTensor,专家的评估数据修正值,可选参数,数据类型支持FLOAT16、INT8,数据格式支持ND。
- weight2:Device侧的aclTensor,专家的评估数据,数据类型支持FLOAT16、INT8,数据格式支持ND。
- bias2:Device侧的aclTensor,专家的评估数据修正值,可选参数,数据类型支持FLOAT16、INT8,数据格式支持ND。
- scale:Device侧的aclTensor,量化参数,可选,数据类型支持FLOAT,数据格式支持ND,一维向量,元素个数与expertTokens长度一致。
- offset:Device侧的aclTensor,量化参数,可选,数据类型支持FLOAT,数据格式支持ND,一维向量,元素个数与expertTokens长度一致。
- deqScale1:Device侧的aclTensor,第一个分组matmul的反量化参数,可选,数据类型支持UINT64,数据格式支持ND,输入2维,第一维等于expertTokens长度,第二维等于weight1第三维度。
- deqScale2:Device侧的aclTensor,第二个分组matmul的反量化参数,可选,数据类型支持UINT64,数据格式支持ND,输入2维,第一维等于expertTokens长度,第二维等于weight2第三维度。
- activation:Host侧的属性值,代表使用的激活函数,当前仅支持fastgelu。
- y:Device侧的aclTensor,公式中的输出y,数据类型支持FLOAT、FLOAT16,数据格式支持ND。
- workspaceSize:返回用户需要在Device侧申请的workspace大小。
- executor:返回op执行器,包含了算子计算流程。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。

第一段接口完成入参校验,出现以下场景时报错:
- 返回161001(ACLNN_ERR_PARAM_NULLPTR):传入的x、expertTokens、weight1、y或executor是空指针。
- 返回161002(ACLNN_ERR_PARAM_INVALID):x、expertTokens、weight1、bias1、weight2、bias2、y的数据类型和数据格式不在支持的范围内。
aclnnMoeFFN
- 接口定义:
aclnnStatus aclnnMoeFFN(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream)
- 参数说明:
- workspace:在Device侧申请的workspace内存起址。
- workspaceSize:在Device侧申请的workspace大小,由第一段接口aclnnMoeFFNGetWorkspaceSize获取。
- executor:op执行器,包含了算子计算流程。
- stream:指定执行任务的AscendCL stream流。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。
约束与限制
- 专家数据的总数需要与BS(其中B表示输入样本批量大小、S表示输入样本序列长度)长度保持一致;
- 专家个数不超过256个;
- 当前MoeFFN实现过程中默认使用fastGelu激活函数,不支持gelu激活函数。
父主题: 融合类算子接口