aclnnIncreFlashAttention
接口原型
每个算子有两段接口,必须先调用“aclnnIncreFlashAttentionGetWorkspaceSize”接口获取入参并根据计算流程计算所需workspace大小,再调用“aclnnIncreFlashAttention”接口执行计算。两段式接口如下:
- 第一段接口:aclnnStatus aclnnIncreFlashAttentionGetWorkspaceSize(const aclTensor *query, const aclTensorList *key, const aclTensorList *value, const aclTensor *paddingMask, const aclTensor *attenMask, const aclIntArray *actualSeqLengths, int64_t numHeads, double scaleValue, char *inputLayout, int64_t numKeyValueHeads, const aclTensor *attentionOut, uint64_t *workspaceSize, aclOpExecutor **executor)
- 第二段接口:aclnnstatus aclnnIncreFlashAttention(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream)
功能描述
- 算子功能:对于自回归(Auto-regressive)的语言模型,随着新词的生成,推理输入长度不断增大。在原来全量推理的基础上实现增量推理,query的S轴固定为1,key和value是经过KV Cache后,将之前推理过的state信息,叠加在一起,每个Batch对应S轴的实际长度可能不一样,输入的数据是经过padding后的固定长度数据。相比全量场景的FlashAttention算子(aclnnPromptFlashAttention),增量推理的流程与正常全量推理并不完全等价,不过增量推理的精度并无明显劣化。

KV Cache是大模型推理性能优化的一个常用技术。采样时,Transformer模型会以给定的prompt/context作为初始输入进行推理(可以并行处理),随后逐一生成额外的token来继续完善生成的序列(体现了模型的自回归性质)。在采样过程中,Transformer会执行自注意力操作,为此需要给当前序列中的每个项目(无论是prompt/context还是生成的token)提取键值(KV)向量。这些向量存储在一个矩阵中,通常被称为kv缓存(KV Cache)。
- 计算公式:
self-attention(自注意力)利用输入样本自身的关系构建了一种注意力模型。其原理是假设有一个长度为n的输入样本序列x,x的每个元素都是一个d维向量,可以将每个d维向量看作一个token embedding,将这样一条序列经过3个权重矩阵变换得到3个维度为n*d的矩阵。
self-attention的计算公式一般定义如下,其中Q、K、V为输入样本的重要属性元素,是输入样本经过空间变换得到,且可以统一到一个特征空间中。
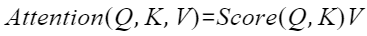
本算子中Score函数采用Softmax函数,self-attention计算公式为
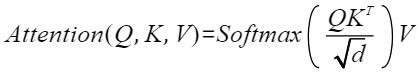
其中Q和KT的乘积代表输入x的注意力,为避免该值变得过大,通常除以d的开根号进行缩放,并对每行进行softmax归一化,与V相乘后得到一个n*d的矩阵。
aclnnIncreFlashAttentionGetWorkspaceSize
- 接口定义:
aclnnStatus aclnnIncreFlashAttentionGetWorkspaceSize(const aclTensor *query, const aclTensorList *key, const aclTensorList *value, const aclTensor *paddingMask, const aclTensor *attenMask, const aclIntArray *actualSeqLengths, int64_t numHeads, double scaleValue, char *inputLayout, int64_t numKeyValueHeads, const aclTensor *attentionOut, uint64_t *workspaceSize, aclOpExecutor **executor)
- 参数说明:
- query:Device侧的aclTensor,公式中的输入Q,数据类型支持FLOAT16,数据格式支持ND。
- key:Device侧的aclTensorList,公式中的输入K,数据类型支持FLOAT16,数据格式支持ND。
- value:Device侧的aclTensorList,公式中的输入V,数据类型支持FLOAT16,数据格式支持ND。
- paddingMask:Device侧的aclTensor,可选参数,数据类型支持FLOAT16,数据格式支持ND。
- attenMask:Device侧的aclTensor,可选参数,数据类型支持BOOL、FLOAT16,数据格式支持ND。
- actualSeqLengths:Host侧的aclIntArray,可选参数,数据类型支持INT64。
- numHeads:Host侧的int64_t,代表head个数,数据类型支持INT64。
- scaleValue:Host侧的double,公式中d开根号的倒数,代表缩放系数,作为计算流中Muls的scalar值,数据类型支持DOUBLE。
- inputLayout:Host侧的字符指针,用于标识输入query、key、value的数据排布格式,当前支持BSH、BNSD。
query、key、value数据排布格式支持从多种维度解读,其中B(Batch)表示输入样本批量大小、S(Seq-Length)表示输入样本序列长度、H(Head-Size)表示隐藏层的大小、N(Head-Num)表示多头数、D(Head-Dim)表示隐藏层最小的单元尺寸,且满足D=H/N。
- numKeyValueHeads:Host侧的int64_t,可选参数,代表key、value中head个数,用于支持GQA(Grouped-Query Attention,分组查询注意力)场景,默认为0,表示和query的head个数相等,数据类型支持INT64。
- attentionOut:Device侧的aclTensor,公式中的输出,数据类型支持FLOAT16,数据格式支持ND。
- workspaceSize:返回用户需要在Device侧申请的workspace大小。
- executor:返回op执行器,包含了算子计算流程。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。
第一段接口完成入参校验,出现以下场景时报错:
- 返回161001(ACLNN_ERR_PARAM_NULLPTR):传入的query、key、value、attentionOut是空指针。
- 返回161002(ACLNN_ERR_PARAM_INVALID):query、key、value、paddingMask、attenMask、attentionOut的数据类型和数据格式不在支持的范围内。
aclnnIncreFlashAttention
- 接口定义:
aclnnstatus aclnnIncreFlashAttention(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream)
- 参数说明:
- workspace:在Device侧申请的workspace内存起址。
- workspaceSize:在Device侧申请的workspace大小,由第一段接口aclnnIncreFlashAttentionGetWorkspaceSize获取。
- executor:op执行器,包含了算子计算流程。
- stream:指定执行任务的AscendCL stream流。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。
约束与限制
- 参数key、value 中对应tensor的shape需要完全一致;非连续场景下 key、value 的tensorlist中的tensor的shape也需要完全一致,且batch只能为1。
- 参数query和attentionOut的shape需要完全一致。
- 参数query中的N和numHeads值相等,key、value的N和numKeyValueHeads值相等,并且numHeads是numKeyValueHeads的倍数关系。
- 非连续场景下,参数key、value的tensorlist中tensor的个数等于query的B,shape需要完全一致。