aclnnBatchNormReduceBackward
接口原型
每个算子有两段接口,必须先调用“aclnnXxxGetWorkspaceSize”接口获取入参并根据计算流程计算所需workspace大小,再调用“aclnnXxx”接口执行计算。两段式接口如下:
- 第一段接口:aclnnStatus aclnnBatchNormReduceBackwardGetWorkspaceSize(const aclTensor* gradOut, const aclTensor* input, const aclTensor* mean, const aclTensor* invstd, const aclTensor* weight, const bool inputG, const bool weightG, const bool biasG, aclTensor* sumDy, aclTensor* sumDyXmu, aclTensor* gradWeight, aclTensor* gradBias, uint64_t* workspaceSize, aclOpExecutor** executor)
- 第二段接口:aclnnStatus aclnnBatchNormReduceBackward(void* workspace, uint64_t workspaceSize, aclOpExecutor* executor, const aclrtStream stream)
功能描述
- 算子功能:BN的反向传播计算了损失函数L相对于对应层各输入xi 的梯度(∂L/∂xi)、对缩放权重γ的梯度(∂L/∂γ)以及对偏移量β的梯度(∂L/∂β),具体参见aclnnBatchNormBackward。本算子计算了其中的“∂L/∂γ”和“∂L/∂β”,并且还用损失函数L相对于输出yi 的偏差推导出“∂L/∂xi”所需的中间量sumDy和sumDyXmu。
- 计算公式:
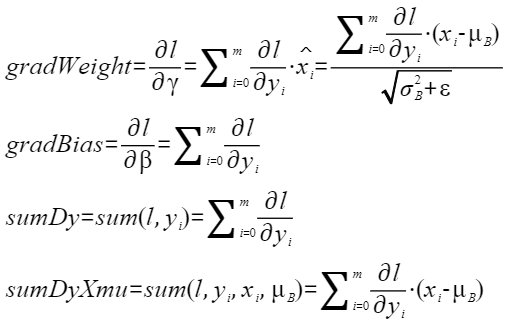
aclnnBatchNormReduceBackwardGetWorkspaceSize
- 接口定义:
aclnnStatus aclnnBatchNormReduceBackwardGetWorkspaceSize(const aclTensor* gradOut, const aclTensor* input, const aclTensor* mean, const aclTensor* invstd, const aclTensor* weight, const bool inputG, const bool weightG, const bool biasG, aclTensor* sumDy, aclTensor* sumDyXmu, aclTensor* gradWeight, aclTensor* gradBias, uint64_t* workspaceSize, aclOpExecutor** executor)
- 参数说明:
- gradOut:Device侧的aclTensor,数据类型仅支持FLOAT、FLOAT16,支持非连续的Tensor,数据格式为ND。
- input:Device侧的aclTensor,数据类型仅支持FLOAT、FLOAT16,支持非连续的Tensor,数据格式为ND。
- mean:Device侧的aclTensor,数据类型仅支持FLOAT、FLOAT16,支持非连续的Tensor,数据格式为ND。
- invstd:Device侧的aclTensor,数据类型仅支持FFLOAT、FLOAT16,支持非连续的Tensor,数据格式为ND。
- weight:Device侧的aclTensor,数据类型仅支持FLOAT、FLOAT16,支持非连续的Tensor,数据格式为ND。
- inputG:BOOL类型,输出掩码,标记是否需要输出sumDy和sumDyXmu。
- weightG:BOOL类型,输出掩码,标记是否需要输出gradWeight。
- biasG:BOOL类型,输出掩码,标记是否需要输出gradBias。
- sumDy:Device侧的aclTensor,如果inputG为True则输出,支持非连续的Tensor,数据格式与输入一致。
- sumDyXmu:Device侧的aclTensor,如果inputG为True则输出,支持非连续的Tensor,数据格式与输入一致。
- gradWeight:Device侧的aclTensor,如果weightG为True则输出,支持非连续的Tensor,数据格式与输入一致。
- gradBias:Device侧的aclTensor,如果biasG为True则输出,支持非连续的Tensor,数据格式与输入一致。
- workspaceSize:返回用户需要在Device侧申请的workspace大小。
- executor:返回op执行器,包含了算子计算流程。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。

第一段接口完成入参校验,出现以下场景时报错:
- 返回161001(ACLNN_ERR_PARAM_NULLPTR):传入的张量参数是空指针。
- 返回161002(ACLNN_ERR_PARAM_INVALID):
- gradOut和input的数据类型和数据格式不在支持的范围内。
- gradOut和input数据类型不相同。
aclnnBatchNormReduceBackward
- 接口定义:
aclnnStatus aclnnBatchNormReduceBackward(void* workspace, uint64_t workspaceSize, aclOpExecutor* executor, const aclrtStream stream)
- 参数说明:
- workspace:在Device侧申请的workspace内存起址。
- workspaceSize:在Device侧申请的workspace大小,由第一段接口aclnnBatchNormReduceBackwardGetWorkspaceSize获取。
- executor:op执行器,包含了算子计算流程。
- stream:指定执行任务的AscendCL stream流。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。
调用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 | #include <iostream> #include <vector> #include "acl/acl.h" #include "aclnnop/aclnn_batch_norm_backward_reduce.h" #define CHECK_RET(cond, return_expr) \ do { \ if (!(cond)) { \ return_expr; \ } \ } while (0) #define LOG_PRINT(message, ...) \ do { \ printf(message, ##__VA_ARGS__); \ } while (0) int64_t GetShapeSize(const std::vector<int64_t>& shape) { int64_t shape_size = 1; for (auto i : shape) { shape_size *= i; } return shape_size; } void PrintOutResult(std::vector<int64_t> &shape, void** deviceAddr) { auto size = GetShapeSize(shape); std::vector<float> resultData(size, 0); auto ret = aclrtMemcpy(resultData.data(), resultData.size() * sizeof(resultData[0]), *deviceAddr, size * sizeof(float), ACL_MEMCPY_DEVICE_TO_HOST); CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("copy result from device to host failed. ERROR: %d\n", ret); return); for (int64_t i = 0; i < size; i++) { LOG_PRINT("result[%ld] is: %f\n", i, resultData[i]); } } int Init(int32_t deviceId, aclrtContext* context, aclrtStream* stream) { // 固定写法,AscendCL初始化 auto ret = aclInit(nullptr); CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclInit failed. ERROR: %d\n", ret); return ret); ret = aclrtSetDevice(deviceId); CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSetDevice failed. ERROR: %d\n", ret); return ret); ret = aclrtCreateContext(context, deviceId); CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtCreateContext failed. ERROR: %d\n", ret); return ret); ret = aclrtSetCurrentContext(*context); CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSetCurrentContext failed. ERROR: %d\n", ret); return ret); ret = aclrtCreateStream(stream); CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtCreateStream failed. ERROR: %d\n", ret); return ret); return 0; } template <typename T> int CreateAclTensor(const std::vector<T>& hostData, const std::vector<int64_t>& shape, void** deviceAddr, aclDataType dataType, aclTensor** tensor) { auto size = GetShapeSize(shape) * sizeof(T); // 调用aclrtMalloc申请device侧内存 auto ret = aclrtMalloc(deviceAddr, size, ACL_MEM_MALLOC_HUGE_FIRST); CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtMalloc failed. ERROR: %d\n", ret); return ret); // 调用aclrtMemcpy将Host侧数据拷贝到device侧内存上 ret = aclrtMemcpy(*deviceAddr, size, hostData.data(), size, ACL_MEMCPY_HOST_TO_DEVICE); CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtMemcpy failed. ERROR: %d\n", ret); return ret); // 计算连续tensor的strides std::vector<int64_t> strides(shape.size(), 1); for (int64_t i = shape.size() - 2; i >= 0; i--) { strides[i] = shape[i + 1] * strides[i + 1]; } // 调用aclCreateTensor接口创建aclTensor *tensor = aclCreateTensor(shape.data(), shape.size(), dataType, strides.data(), 0, aclFormat::ACL_FORMAT_ND, shape.data(), shape.size(), *deviceAddr); return 0; } int main() { // 1. (固定写法)device/context/stream初始化, 参考AscendCL对外接口列表 // 根据自己的实际device填写deviceId int32_t deviceId = 0; aclrtContext context; aclrtStream stream; auto ret = Init(deviceId, &context, &stream); CHECK_RET(ret == 0, LOG_PRINT("Init acl failed. ERROR: %d\n", ret); return ret); // check根据自己的需要处理 // 2. 构造输入与输出,需要根据API的接口自定义构造 std::vector<int64_t> gradOutShape = {4, 2}; std::vector<int64_t> inputShape = {4, 2}; std::vector<int64_t> meanShape = {2}; std::vector<int64_t> invstdShape = {2}; std::vector<int64_t> weightShape = {2}; std::vector<int64_t> sumDyShape = {2}; std::vector<int64_t> sumDyXmuShape = {2}; std::vector<int64_t> gradWeightShape = {2}; std::vector<int64_t> gradBiasShape = {2}; void* inputDeviceAddr = nullptr; void* gradOutDeviceAddr = nullptr; void* meanDeviceAddr = nullptr; void* invstdDeviceAddr = nullptr; void* weightDeviceAddr = nullptr; void* sumDyDeviceAddr = nullptr; void* sumDyXmuDeviceAddr = nullptr; void* gradWeightDeviceAddr = nullptr; void* gradBiasDeviceAddr = nullptr; aclTensor* input = nullptr; aclTensor* gradOut = nullptr; aclTensor* mean = nullptr; aclTensor* invstd = nullptr; aclTensor* weight = nullptr; aclTensor* sumDy = nullptr; aclTensor* sumDyXmu = nullptr; aclTensor* gradWeight = nullptr; aclTensor* gradBias = nullptr; std::vector<float> gradOutHostData = {1, 1, 1, 2, 2, 2, 3, 3}; std::vector<float> inputHostData = {0, 1, 2, 3, 4, 5, 6, 7}; std::vector<float> meanHostData = {1, 1}; std::vector<float> invstdHostData = {1, 1}; std::vector<float> weightHostData = {1, 1}; std::vector<float> sumDyHostData = {1, 1}; std::vector<float> sumDyXmuHostData = {1, 1}; std::vector<float> gradWeightHostData = {1, 1}; std::vector<float> gradBiasHostData = {1, 1}; ret = CreateAclTensor(gradOutHostData, gradOutShape, &gradOutDeviceAddr, aclDataType::ACL_FLOAT, &gradOut); CHECK_RET(ret == ACL_SUCCESS, return ret); ret = CreateAclTensor(inputHostData, inputShape, &inputDeviceAddr, aclDataType::ACL_FLOAT, &input); CHECK_RET(ret == ACL_SUCCESS, return ret); ret = CreateAclTensor(meanHostData, meanShape, &meanDeviceAddr, aclDataType::ACL_FLOAT, &mean); CHECK_RET(ret == ACL_SUCCESS, return ret); ret = CreateAclTensor(invstdHostData, invstdShape, &invstdDeviceAddr, aclDataType::ACL_FLOAT, &invstd); CHECK_RET(ret == ACL_SUCCESS, return ret); ret = CreateAclTensor(weightHostData, weightShape, &weightDeviceAddr, aclDataType::ACL_FLOAT, &weight); CHECK_RET(ret == ACL_SUCCESS, return ret); bool inputG = true; bool weightG = true; bool biasG = true; ret = CreateAclTensor(sumDyHostData, sumDyShape, &sumDyDeviceAddr, aclDataType::ACL_FLOAT, &sumDy); CHECK_RET(ret == ACL_SUCCESS, return ret); ret = CreateAclTensor(sumDyXmuHostData, sumDyXmuShape, &sumDyXmuDeviceAddr, aclDataType::ACL_FLOAT, &sumDyXmu); CHECK_RET(ret == ACL_SUCCESS, return ret); ret = CreateAclTensor(gradWeightHostData, gradWeightShape, &gradWeightDeviceAddr, aclDataType::ACL_FLOAT, &gradWeight); CHECK_RET(ret == ACL_SUCCESS, return ret); ret = CreateAclTensor(gradBiasHostData, gradBiasShape, &gradBiasDeviceAddr, aclDataType::ACL_FLOAT, &gradBias); CHECK_RET(ret == ACL_SUCCESS, return ret); // 3. 调用CANN算子库API uint64_t workspaceSize = 0; aclOpExecutor* executor; // 调用aclnnBatchNormReduceBackward第一段接口 ret = aclnnBatchNormReduceBackwardGetWorkspaceSize(gradOut, input, mean, invstd, weight, inputG, weightG, biasG, sumDy, sumDyXmu, gradWeight, gradBias, &workspaceSize, &executor); CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclnnBatchNormReduceBackwardGetWorkspaceSize failed. ERROR: %d\n", ret); return ret); // 根据第一段接口计算出的workspaceSize申请device内存 void* workspaceAddr = nullptr; if (workspaceSize > 0) { ret = aclrtMalloc(&workspaceAddr, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST); CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("allocate workspace failed. ERROR: %d\n", ret); return ret;); } // 调用aclnnBatchNormReduceBackwardNpuImpl第二段接口 ret = aclnnBatchNormReduceBackward(workspaceAddr, workspaceSize, executor, stream); CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclnnBatchNormReduceBackward failed. ERROR: %d\n", ret); return ret); // 4. (固定写法)同步等待任务执行结束 ret = aclrtSynchronizeStream(stream); CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSynchronizeStream failed. ERROR: %d\n", ret); return ret); // 5. 获取输出的值,将device侧内存上的结果拷贝至Host侧,需要根据具体API的接口定义修改 PrintOutResult(sumDyShape, &sumDyDeviceAddr); PrintOutResult(sumDyXmuShape, &sumDyXmuDeviceAddr); PrintOutResult(gradWeightShape, &gradWeightDeviceAddr); PrintOutResult(gradBiasShape, &gradBiasDeviceAddr); // 6. 释放aclTensor和aclScalar,需要根据具体API的接口定义修改 aclDestroyTensor(input); aclDestroyTensor(gradOut); aclDestroyTensor(mean); aclDestroyTensor(invstd); aclDestroyTensor(weight); aclDestroyTensor(sumDy); aclDestroyTensor(sumDyXmu); aclDestroyTensor(gradWeight); aclDestroyTensor(gradBias); return 0; } |
父主题: NN类算子接口