Atlas 800-3010 执行带IO拔NVMe盘导致系统崩溃
更新时间: 2022/03/03
问题信息
| 问题来源 | 产品大类 | 产品子类 | 关键字 |
|---|---|---|---|
| 版本问题 | 安装部署 | 驱动固件 | NVMe、暴力热插拔、call trace |
问题现象描述
硬件配置:Atlas 800-3010
问题现象:服务器带盘启动,正常进入OS后对NVMe盘进行跑IO操作,然后执行暴力拔盘操作概率性会出现系统崩溃。这个现象在海思自研盘和Intel盘都出现。系统奔溃时的calltrace如下图所示:
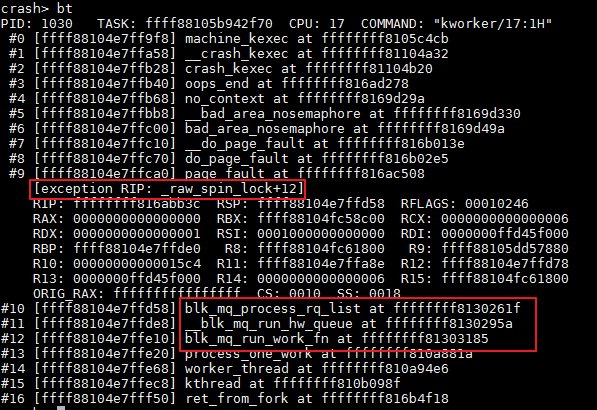
关键过程、根本原因分析
在NVMe盘暴力拔盘时出现系统crash的直接原因是NVMe驱动访问了已经free的内存,从而导致了页面请求失败。根本原因是NVMe驱动中的nvme_remove函数和nvme_watchdog_timer函数执行的顺序是随机的,仅当nvme_remove->blk_mq_exit_hctx函数先于nvme_watchdog_timer->flush_busy_ctxs函数执行才会触发此问题。下面是分析过程:
- 当我们执行拔盘操作时,由于NVMe盘是PCIe设备,因此会执行pci_driver.remove函数,对于NVMe驱动,这个函数被注册为nvme_remove函数,nvme_remove函数在执行的过程中会调用到blk_mq_exit_hctx,这个调用关系是:
nvme_remove -> nvme_uninit_ctrl -> nvme_remove_namespaces -> nvme_ns_remove -> blk_cleanup_queue -> blk_mq_free_queue -> blk_mq_exit_hw_queues -> blk_mq_exit_hctx,blk_mq_exit_hctx函数执行后,硬队列hctx的所有软队列ctxs以及ctx_map成员的内存将会被free掉。
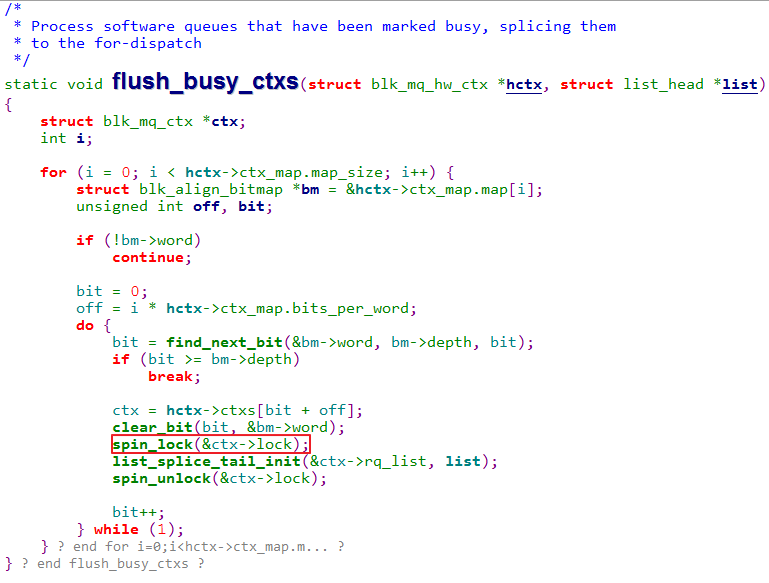
- nvme_probe函数中注册了一个看门狗定时器,这个看门狗定时器的作用是当NVMe驱动和NVMe盘失去通信时将会对NVMe盘进行复位。在复位的过程中将会调用到nvme_kill_queues函数,该函数将会访问硬队列hctx的ctxs成员,如果这个访问的时机在第1步的ctxs以及ctx_map成员的内存将会被free掉之后,将会导致NVMe驱动访问到了已经free的内存,导致内存请求错误,从而导致系统crash。从nvme_kill_queues后的函数调用关系如下:nvme_kill_queues -> blk_mq_start_hw_queues -> blk_mq_start_hw_queue -> blk_mq_run_hw_queue -> __blk_mq_delay_run_hw_queue -> kblockd_schedule_delayed_work_on -> blk_mq_run_work_fn -> __blk_mq_run_hw_queue -> blk_mq_process_rq_list -> flush_busy_ctxs。其中flush_busy_ctxs函数的实现如下:
如上图所示,ctx已经被free掉,但是又出现了访问ctx->lock的情况,因此导致了系统crash。
结论、解决方案及效果
结论:这是RHEL 7.4系统的NVMe驱动BUG,这个BUG的链接如下:
https://lore.kernel.org/patchwork/patch/777286/
解决方案:将OS的内核升级到RHEL 7.5 GA版本以上(3.10.0-862以上)的内核。解决该BUG的补丁如下图红框所示。

经验总结、预防措施和规范建议
无
备注
无
本页内容