背景介绍
AI CPU是昇腾AI处理器计算单元,因为该CPU计算处理单位自身瓶颈,导致运行在AI CPU上的算子影响模型的执行时间。AI CPU算子的优化往往是重点关注点和优化对象。本节以MLP模型为例,介绍通过专家系统AI CPU识别功能, 自动识别串行执行AI CPU算子,给出优化建议,提升模型整体性能。
专家系统操作
以HwHiAiUser用户为例执行以下操作。
- 参见《CANN 软件安装指南》安装Ascend-cann-toolkit包。
- 准备通过Profiling采集生成的timeline文件作为AI CPU算子识别功能的输入文件。timeline文件路径为${data_path}数据目录根路径的下profiling/PROF_XXX_XXX/device_0目录下的timeline文件夹。
- 配置环境变量。
. /home/HwHiAiUser/Ascend/ascend-toolkit/set_env.sh
- 执行分析命令。
msadvisor -d /home/HwHiAiUser/data -c model
-d参数数据指定profiling文件的路径,指定到数据目录的根目录(包含所有专家系统输入数据的目录);AI CPU算子识别功能属于对模型的分析,所以-c参数配置值为model。
- 完成分析后,系统会将分析结果以打屏的形式展示。输出MLP模型内的AI CPU算子如下。

问题分析
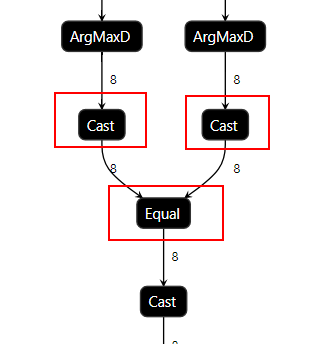
根据专家系统AI CPU算子识别的推荐结果,发现计算图中两个Cast算子和Equal算子都在AI CPU上执行,需要考虑将Cast算子和Equal算子在AI CPU上消除。
由于Cast算子的作用是将算子输出结果进行格式转换,且在AI Core上的运算仅支持32位及以下的数据类型,根据图1,可推测下层的Equal算子数据类型应该在32位以上,所以生成了负责数据格式转换的Cast算子且这两个算子转移到了AI CPU上进行运算。
问题解决
根据优化建议3. Change the model structure, for example, from INT64 to FP16.(更改模型结构,如:int64转FP16。)
可将Equal算子数据类型修改为与上层ArgMaxD算子一样的数据类型,即可消除掉Cast算子并将Equal算子转移回AI Core上运算。
修改Equal算子后再次进行专家系统分析可以发现Cast算子和Equal算子已不在AI CPU算子优化分析结果中,同时还输出UB融合推荐发现还可以对ArgMaxD和Equal算子进行融合,进一步提升效率。相关分析方式请参见UB算子融合推荐分析样例。
结论
通过专家系统工具的分析,可以快速找出AI CPU算子。并根据专家系统的提示,结合实际的网络模型实际特点,对问题分析后得到解决方案。提升了网络性能问题分析效率。