本文档以Atlas 800I A2 推理服务器和Qwen2.5-7B模型为例,让开发者快速了解通过MindIE Turbo使用vLLM进行大模型推理流程。
前提条件
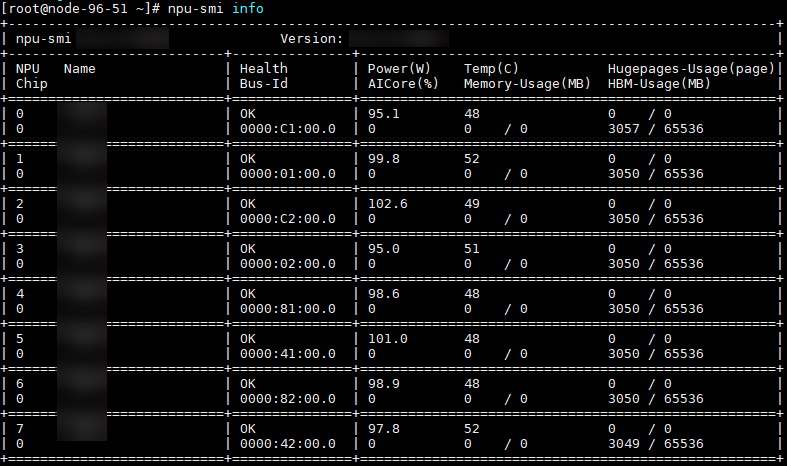
物理机部署场景,需要在物理机安装NPU驱动固件以及部署Docker,执行如下步骤判断是否已安装NPU驱动固件和部署Docker。
获取模型权重
请先下载权重,这里以Qwen2.5-7B为例,下载链接:https://huggingface.co/Qwen/Qwen2.5-7B,将权重文件上传至服务器任意目录(如/home/weight)。
制作镜像
参见《MindIE Turbo开发指南》中的“安装MindIE Turbo(容器化)”章节,通过Dockerfile文件构建MindIE Turbo镜像(镜像文件以mindie-turbo:800I-A2-py311-Openeuler24.03-aarch64为例)。
该镜像包括模型运行所需的基础环境,包括:CANN、FrameworkPTAdapter、MindIE Turbo、vLLM与vLLM-ascend,可实现模型快速上手推理。