以首token平均时延限制在8000ms以内、Decode平均时延限制50ms以内为目标,首token时延限制严格,且非首token时延也有限制的调试方式如下所示。
- 服务端:
- “maxBatchSize”调小到卡对应的时延,一般情况下“maxBatchSize”越小,则Decode时延越小。
- 设置supportSelectBatch为false。
- 客户端:
- 按并发数发送请求:客户端Concurrency通常配置为maxBatchSize-1。
- 按频率发送请求:则Concurrency可设置为1000,请求发送频率根据实际业务场景或按模型实际QPS设置。
- 性能调优前需要开启CPU高性能模式、透明大页以及jemalloc优化。
- 在裸机中执行以下命令开启CPU高性能模式和透明大页,开启后可提升性能,建议开启。
- 开启CPU高性能模式,在相同时延约束下,TPS会有约3%的提升。
cpupower -c all frequency-set -g performance
- 开启透明大页,多次实验的吞吐率结果会更稳定。
echo always > /sys/kernel/mm/transparent_hugepage/enabled

服务化进程可能与模型执行进程抢占CPU资源,导致性能时延波动;可以在启动服务时将服务化进程手动绑核至CPU奇数核,以减少CPU抢占影响,降低性能波动,具体方法如下所示。
- 使用lscpu命令查看系统CPU配置情况。
lscpu
CPU相关配置回显信息如下所示:
NUMA: NUMA node(s): 8 NUMA node0 CPU(s): 0-23 NUMA node1 CPU(s): 24-47 NUMA node2 CPU(s): 48-71 NUMA node3 CPU(s): 72-95 NUMA node4 CPU(s): 96-119 NUMA node5 CPU(s): 120-143 NUMA node6 CPU(s): 144-167 NUMA node7 CPU(s): 168-191
- 使用taskset -c命令将服务化进程绑核至CPU奇数核并启动。
taskset -c $cpus ./bin/mindieservice_daemon
$cpus:为CPU配置回显信息中node1、node3、node5或node7的值。
- 使用lscpu命令查看系统CPU配置情况。
- 开启CPU高性能模式,在相同时延约束下,TPS会有约3%的提升。
- jemalloc优化需要用户自行编译jemalloc动态链接库,并在脚本里引入编译好的动态链接库,具体步骤如下。
- 单机链接下载jemalloc源码,并参考INSTALL.md文件编译安装。
- 在kubernetes_deploy_scripts/boot_helper/boot.sh脚本中引入jemalloc动态链接库,具体为在脚本第2行增加如下命令:
export LD_PRELOAD="{$path_to_lib}/libjemalloc.so:$LD_PRELOAD"其中path_to_lib为libjemalloc.so所在路径。
- 在裸机中执行以下命令开启CPU高性能模式和透明大页,开启后可提升性能,建议开启。
- 使用以下命令启动服务,以当前所在Ascend-mindie-service_{version}_linux-{arch}目录为例。
./bin/mindieservice_daemon
回显如下则说明启动成功。
Daemon start success!
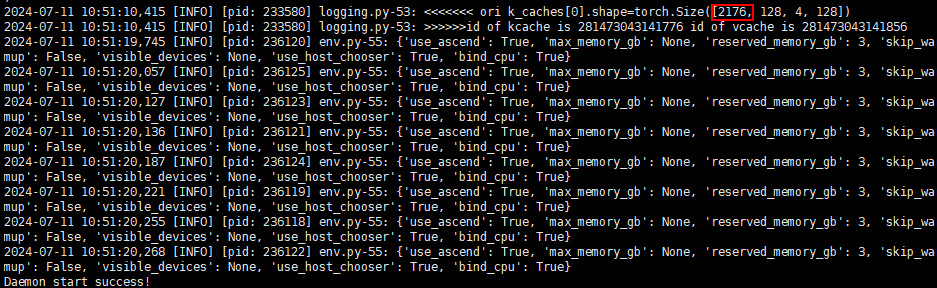
服务启动后,可通过info级打屏日志k_caches[0].shape=torch.Size([npuBlockNum, x, x, x])中torch.Size的第一个值获取npuBlockNum的值,如图1所示,与3.a中计算出来的值一致。
- 根据3.c计算出“maxBatchSize”的取值范围为[90,272],设置初始值为200;“maxPrefillBatchSize”参数的值设置为“maxBatchSize”值的一半,取值为100。
需要将“supportSelectBatch”参数设置为false,以获取更低的首token时延。
- 配置完成后,用户可使用HTTPS客户端(Linux curl命令,Postman工具等)发送HTTPS请求,此处以Linux curl命令为例进行说明。
重开一个窗口,使用以下命令发送请求,获取当前首token平均值(Average)和DecodeTime的平均值(Average),此时首token平均时延为21252.0612ms,decode平均时延为73.7486ms。
benchmark \ --DatasetPath "/{数据集路径}/GSM8K" \ --DatasetType "gsm8k" \ --ModelName LLaMa3-8B \ --ModelPath "/{模型路径}/LLaMa3-8B" \ --TestType client \ --Http https://{ipAddress}:{port} \ --ManagementHttp https://{managementIpAddress}:{managementPort} \ --Concurrency 1000 \ --TaskKind stream \ --Tokenizer True \ --MaxOutputLen 512以上结果超过了首token平均时延为8000ms和Decode平均时延为50ms的限制,所以需要调小“maxBatchSize”的值继续调试。
- 设置“maxBatchSize”的值为150,“maxPrefillBatchSize”参数的值设置为75。然后执行4,继续观察首token平均时延和Decode平均时延,此时首token平均时延为11265.0242ms,Decode平均时延为61.9161ms。
以上结果同样超过了首token平均时延为8000ms和Decode平均时延为50ms的限制,所以需要调小“maxBatchSize”的值继续调试。
- 设置“maxBatchSize”的值为100,“maxPrefillBatchSize”参数的值设置为50。然后执行4,继续观察首token平均时延和Decode平均时延,此时首token平均时延为6364.6507ms,Decode平均时延为49.9804ms。
以上结果可以看到首token平均时延和Decode平均时延已经在限制的8000ms和50ms以内,且Decode平均时延已经很接近50ms,此时几乎已达到限制首token时延和Decode时延下的最大吞吐量。如需获取Decode平均时延更接近50ms时的“maxBatchSize”值,请根据以上操作步骤继续调试。