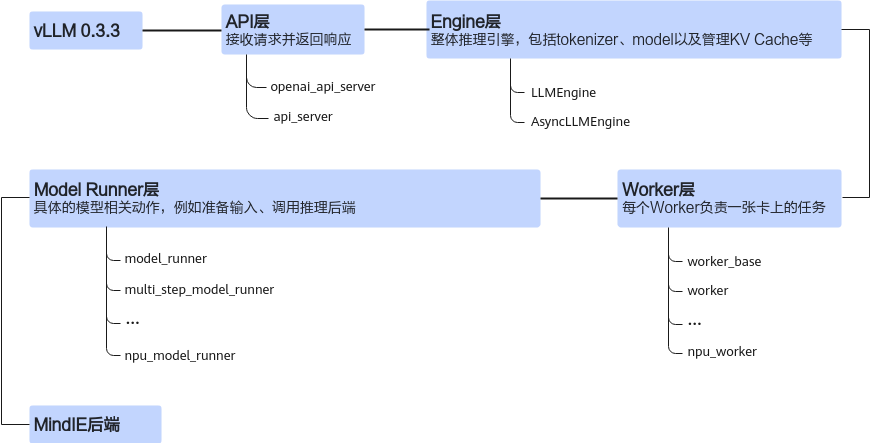
vllm_npu_0.3.3版本(即:vLLM 0.3.3版本昇腾框架适配代码)中主要修改了core、engine、model_executor、worker四个模块,与vLLM原生框架中的同名模块一一对应进行热替换适配。vllm_npu_0.3.3版本可参考参考代码制作。
图1 vLLM 0.3.3版本架构图
模块 |
简介 |
|---|---|
core模块 |
该模块中对于“num_batched_tokens”的计算与MindIE后端有所不同,因此在此处需要修改该变量计算逻辑。 |
engine模块 |
该模块替换了部分内容,主要是为了确保vLLM框架可以正确获取到后续的worker与model_executor模块。例如:
|
model_executor模块 |
该模块负责与MindIE LLM模型的推理与后处理进行对接,包含两个子模块:“layers”和 “models”。
同时添加了ascend_model_loader.py文件,为后续的“ModelRunner”加载模型提供“get_model”方法。 |
worker模块 |
该模块覆写了“Worker”类与“ModelRunner”类中的部分函数,在ascend_worker.py和model_runner.py中与 “MindIELlmWrapper”交互,确保模型的加载、预热、推理和后处理等过程能够正确在后端执行。 此外,修改了原生框架中“CacheEngine”的“_allocate_kv_cache”函数,确保与后端接收的参数形式一致。 |