功能
KVCache + KVCache + Muls + FlashAttention。
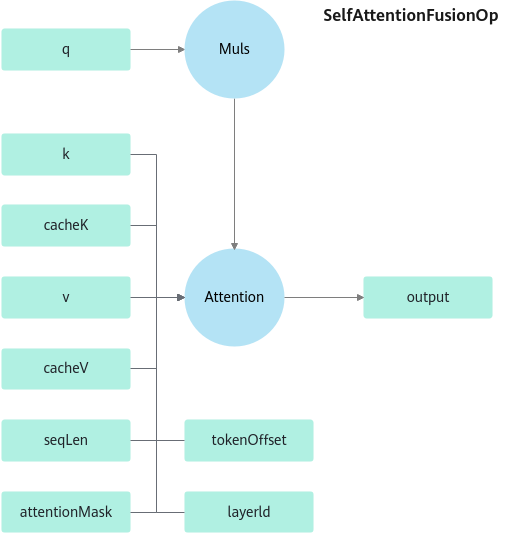
约束
- tokenOffset ≥ seqLen。
- attentionMask的维度:
- 支持[batch, maxSeqLen, maxSeqLen],此时需要保证batch的维度和其他输入batch维度的一致性。
- 支持[maxSeqLen, maxSeqLen],此时所有batch的mask相同。
- 支持[batch, 1, maxSeqLen],此时所有batch的mask不同,mask为向量。
- 在Atlas 推理系列产品(配置Ascend 310P AI处理器)上,q、k、v、attentionMask输入的数据类型不支持bf16。
- 在calcType = PA_ENCODER下,Atlas 800I A2推理产品上的q,k,v可传二维[nTokens, hiddenSize]或四维[batch, seq_len, head_num, head_size]。
- 当开启高精度功能且“maskType”为“NORM”或“NORM_COMPRESS”时,“mask”值需传1。
- 对于Atlas 推理系列产品(Ascend 310P AI处理器)上,0< batch <= 2000。
- 如需使用GQA模式,需满足以下条件:
- headNum > kvHeadNum
- headNum == 0且kvHeadNum == 0
- head_size取值范围为(0, 256]。
- Atlas 推理系列产品(Ascend 310P AI处理器)上的mask大小必须使用真实的max_seq_len,q_seq_len必须等于kv_seq_len。
- 关于tensor维度中的nTokens:
- Atlas 800I A2推理产品上为各batch上seq_len之和。
- Atlas 推理系列产品(Ascend 310P AI处理器)上:PA_ENCODER下为所有batch的seq_len之和向上对齐到16的整数倍,其余情况下为所有batch上的seq_len先向上对齐到16的整数倍,再求和。
- 开启压缩mask功能且maskType为MASK_TYPE_ALIBI_COMPRESS时,mask的维度:在Atlas 800I A2推理产品上为[head_num, seqlen, 128]或[256, 256]。Atlas 推理系列产品(Ascend 310P AI处理器)上为[head_num, 128//16, maxSeqlen, 16]或[1, 256//16, 256, 16]。
- 开启压缩mask功能且maskType为MASK_TYPE_NORM_COMPRESS时,mask的维度:在Atlas 800I A2推理产品上为[128, 128]。Atlas 推理系列产品(Ascend 310P AI处理器)上为[1, 128//16, 128, 16]。
定义
struct SelfAttentionParam {
enum CalcType : int {
UNDEFINED = 0,
ENCODER, // encoder for flashAttention
DECODER, // decoder for flashAttention
PA_ENCODER // encoder for pagedAttention
};
enum KernelType : int {
KERNELTYPE_DEFAULT = 0, // i:fp16, bmm:fp16, o:fp16
KERNELTYPE_HIGH_PRECISION // i:fp16, bmm:fp32, o:fp16
};
enum ClampType : int {
CLAMP_TYPE_UNDEFINED = 0,
CLAMP_TYPE_MIN_MAX
};
enum MaskType : int {
MASK_TYPE_UNDEFINED = 0,
MASK_TYPE_NORM,
MASK_TYPE_ALIBI,
MASK_TYPE_NORM_COMPRESS,
MASK_TYPE_ALIBI_COMPRESS,
MASK_TYPE_ALIBI_COMPRESS_SQRT
};
int32_t headNum = 0;
int32_t kvHeadNum = 0;
float qScale = 1; // qtensor scale before qkbmm
float qkScale = 1; // scale after qkbmm
bool batchRunStatusEnable = false;
uint32_t isTriuMask = 0;
CalcType calcType = UNDEFINED;
KernelType kernelType = KERNELTYPE_DEFAULT;
ClampType clampType = CLAMP_TYPE_UNDEFINED;
float clampMin = 0;
float clampMax = 0;
MaskType maskType = MASK_TYPE_UNDEFINED;
};
成员
成员名称 |
描述 |
|---|---|
CalcType |
计算类型。
|
KernelType |
算子内部计算类型。
|
ClampType |
缩放类型。
|
MaskType |
AttentionMask类型
|
headNum |
多头数量。 headNum需大于或等于0。 |
kvHeadNum |
该值需要用户根据使用的模型实际情况传入。
|
qScale |
q缩放系数。 |
qkScale |
qk缩放系数。 |
batchRunStatusEnable |
是否动态batch。 |
isTriuMask |
TriuMask性能优化。只有maskType为倒三角模式时支持该优化。
|
calcType |
计算类型。CalcType类型枚举值。 |
kernelType |
算子内部计算类型。KernelType类型枚举值。 |
clampType |
缩放类型。ClampType类型枚举值。Atlas 推理系列产品(配置Ascend 310P AI处理器)FlashAttention不支持clamp。 |
clampMin |
缩放最小值。 |
clampMax |
缩放最大值。 |
maskType |
AttentionMask类型,MaskType类型枚举值。 |
函数输入输出描述

当在Atlas 推理系列产品(Ascend 310P AI处理器)上运行时,cacheK,cacheV的格式为NZ格式,相应的维度为[layer, batch, hiddenSize/16, maxSeqLen, 16],且maxSeqLen应与16对齐。
当在Atlas 推理系列产品(Ascend 310P AI处理器)上运行时,mask的格式可以为NZ格式,相应的维度为[batch, kvMaxSeqLen / 16, qMaxSeqLen, 16], [1, kvMaxSeqLen / 16, qMaxSeqLen, 16], [batch * head, kvMaxSeqLen / 16, qMaxSeqLen, 16], [head, kvMaxSeqLen / 16, qMaxSeqLen, 16],且kvMaxSeqLen,qMaxSeqLen应与16对齐。
以上维度说明中,涉及除法的均为ceil div。
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
q |
[nTokens, qHiddenSize] |
float16/bf16 |
ND |
query矩阵。qHiddenSize = headNum * head_size |
k |
[nTokens, hiddenSize] |
float16/bf16 |
ND |
key矩阵。 hiddenSize = kvHeadNum * head_size |
v |
[nTokens, hiddenSize] |
float16/bf16 |
ND |
value矩阵。 |
cacheK |
[layer, batch, maxSeqLen, hiddenSize] |
float16 |
ND/NZ |
之前所有的key, 待与当前key拼接。 |
cacheV |
[layer, batch, maxSeqLen, hiddenSize] |
float16/int32 |
ND/NZ |
之前所有value, 待与当前value拼接。 |
attentionMask |
[maxSeqLen, maxSeqLen] [batch, maxSeqLen, maxSeqLen] [batch, 1, maxSeqLen] [batch, headNum, maxSeqLen, maxSeqLen] |
float16/bf16 |
ND/NZ |
支持场景:
|
tokenOffset |
[batch] |
uint32/int32 |
ND |
计算完成后的token偏移。 |
seqLen |
[batch] |
uint32/int32 |
ND |
|
layerId |
[1] |
uint32/int32 |
ND |
当前处于第几个layer。 |
batchStatus |
[batch] |
uint32/int32 |
ND |
batchRunStatusEnable = true,即开启动态batch时,控制具体需要运算的batch。 |
output |
[ntokens, qHiddenSize] |
float16 |
ND |
输出。 |
函数输入输出描述(calcType = PA_ENCODER)
参数 |
维度 |
数据类型 |
格式 |
设备 |
描述 |
|---|---|---|---|---|---|
query |
[nTokens, head_num, head_size] |
float16/bfloat16 |
ND |
npu |
query矩阵。 |
key |
[nTokens, head_num, head_size] |
float16/bfloat16 |
ND |
npu |
key矩阵。 |
value |
[nTokens, head_num, head_size] |
float16/bfloat16 |
ND |
npu |
value矩阵。 |
mask |
与FlashAttention相同。 |
float16/bfloat16 |
ND/NZ |
npu |
与FlashAttention相同,当maskType为undefined时不传此tensor。 |
seqLen |
[batch] |
int32 |
ND |
cpu |
|
slopes |
[head_num] |
Atlas 800I A2推理产品:float16 Atlas 推理系列产品(Ascend 310P AI处理器):float |
ND |
npu |
当maskType为alibi压缩,且mask为[256,256]时需传入此tensor,为alibi mask每个head的系数。 |
output |
[nTokens, head_num, head_size] |
float16/bfloat16 |
ND |
npu |
输出。 |