性能调优的目的是使用性能分析工具分析AI任务运行时采集的性能数据,判断AI任务运行时的软硬件性能瓶颈,基本的分析思路如图1所示。
性能分析工具(Profiling)的具体使用指导请参见《CANN 性能分析工具指南》章节。
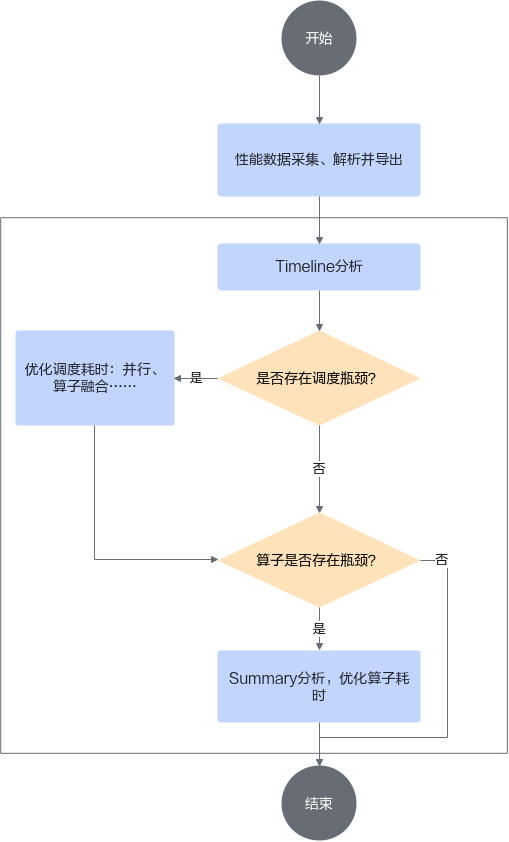
基础的性能分析主要围绕两部分展开:
- Timeline:基于TensorBoard可视化或者基于Chrome插件打开(在Chrome浏览器中输入chrome://tracing,然后将文件拖入空白处)。
- Summary:主要为*.csv文件,可以获取到详细的算子执行耗时信息。
以ChatGLM模型为例,先基于Profiling工具得到Timeline流水文件(msprof*.json)和对应算子耗时统计信息文件(op_statistic_*.csv/op_summary_*.csv)。性能分析基本流程如下:
- 分析前后处理时间。
大模型推理端到端的时间主要包括前后处理和模型推理时间。大模型的核心推理部分为Transformer结构,前后处理通常是一系列简单小算子的计算,如输入Mask生成,后处理Sample/Beam_Search等。通常前后处理小算子在torch/torch_npu上执行,对于小算子数目较多的情况下,会存在调度时间过长的问题,如图2 模型处理以及推理时间所示,需要将前后处理操作合并到加速库Model层来减少调用时间。
- 分析模型推理流水,主要围绕以下两点展开。
- 分析算子执行耗时。
基于op_statistic文件判断瓶颈算子类别(如MatMul算子等),如图3 op_statistic所示。基于op_summary文件判断具体瓶颈算子详细信息,如图4 op_summary所示。例如MatMul算子在大模型场景下受限于带宽,则mte2_ratio需要大于90%,否则需要优化具体Shape的算子性能,具体可参考单算子性能分析及优化章节。
op_statistic样例如下:
op_summary样例如下:
Task Duration字段为算子耗时信息,可以按照Task Duration排序,找出高耗时算子,也可以按照Task Type排序,查看不同核(AI Core和AI CPU)上运行的高耗时算子。


