在本章节中,您可以通过LLaMA模型代码了解使用ATB高性能加速库接口的迁移适配以及迁移过程中涉及的关键概念,并以LLaMA模型为例,讲解如何使用加速库API,方便您基于加速库快速部署您的第一个大模型,并完成相应的精度和性能测试。
前提条件
已在环境上部署昇腾AI软件栈并安装MindIE和ATB-Models模型库(请联系华为工程师获取)。

本次样例参考以下安装路径进行:
- 安装MindIE至当前工作目录“${working_dir}/mindie”。
- 解压MindIE ATB-Models模型库至当前工作目录“${working_dir}/atb_models”。
什么是大模型推理?
大模型推理的主要任务是优化模型推理的流程,因此您首先需要了解大模型的基本结构。通常情况下,单个模型由N层Layer堆叠而成,单层Layer由Embedding、Normalization、Transformer Block (Self-Attention、MLP)、Residual Add、和LM Head几个关键的计算模块构成,下图为LLaMA模型结构的示例:

了解基本概念
ATB高性能加速库,用于Transformer神经网络推理,包含了各种基于C++开发的Transformer类模型的高度优化模块,如Encoder和Decoder(Transformer Block)。加速库主要划分三个层级,如下图所示:
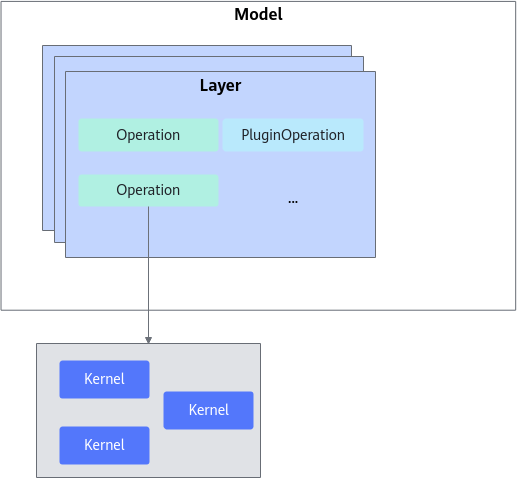
- Operation
Operation可以分为两类,加速库本身提供的基础Operation和用户根据自身需求使用Ascend C开发的PluginOperation。
Operation为加速库成图的最小单元,是Transformer类模型可识别的最小单元模块,通常对应PyTorch的Module或者Function,如:ROPE、Self-Attention、FFN等。Operation通常也是基于不同底层算子(Kernel)的组合,例如FFN是matmul/add/activation等算子的组合,是模型之间可复用的模块。
底层Kernel算子由公共算子库提供,对用户不可见。模型适配不涉及Kernel的开发,如果存在不支持的Operation,用户可以给加速库提需求或者用户使用Ascend C开发自定义的PluginOperation。
- Layer
Layer层为Operation的组合单元,定义为不同模型的通用大颗粒结构,如Transformer_Block/LM_Head层等。
- Model
将定义的Layer进行拼接,组成完整的推理流程即为Model层。Model层通常包含了完整的模型推理过程,PyTorch等框架可以直接在对应Python代码侧调用已实现的Model类,实现模型的推理调用。
基于已实现的Model类,PyTorch等框架直接在对应Python代码侧调用,借助加速库提供的API实现加速库模型的推理调用。
模型部署
- 配置加速库环境。
# 配置CANN环境,默认安装在/usr/local目录下 source /usr/local/Ascend/ascend-toolkit/set_env.sh # 配置加速库环境 source ${working_dir}/mindie/latest/mindie-rt/mindie-atb/set_env.sh source ${working_dir}/atb_models/set_env.sh - 准备LLaMA模型权重:可从Hugging Face官网(meta-llama/Llama-2-7b-hf · Hugging Face)直接下载,将下载的权重保存在“/data/Llama-2-7b-hf”。
- 直接使用模型库中提供的脚本执行静态推理,推理脚本可参考“${working_dir}/atb_models/examples/run_pa.py”。进入“${working_dir}/atb_models/”,执行以下命令。
torchrun --nproc_per_node 2 --master_port 20038 -m examples.run_pa --model_path /data/Llama-2-7b-hf --input_text ["What's Deep Learning?"] --max_output_length 2048
- 在“${working_dir}/atb_models/”下创建自定义推理脚本“infer_llama.py”。
- 引入加速库必要的模块,设置环境。
import os import torch from examples.run_pa import PARunner rank = int(os.getenv("RANK", "0")) local_rank = int(os.getenv("LOCAL_RANK", "0")) world_size = int(os.getenv("WORLD_SIZE", "1")) - 准备模型输入,具体参数信息可参考4.5.3 框架接口调用。
input_dict= { 'rank': rank, 'local_rank': local_rank, 'world_size': world_size, 'max_prefill_tokens': -1, 'block_size': 128, 'model_path': "/data/Llama-2-7b-hf", 'is_bf16': False, 'max_position_embeddings': 2048, # max_input_length + max_ouput_length 'max_batch_size': 1, 'use_refactor': True, 'max_input_length': 1024, 'max_output_length': 1024 } pa_runner = PARunner(**input_dict) - 执行加速库推理。
# 模型warm up,用于给kv cache预申请内存 pa_runner.warm_up() # 执行推理 input_texts = ["What's deep learning?"] generate_texts, token_nums, ete_time = pa_runner.infer( input_texts=input_texts, batch_size=1, max_output_length=512, ignore_eos=True, input_ids=None ) # 打印推理执行结果 print(generate_texts)
- 引入加速库必要的模块,设置环境。
- 运行自定义推理脚本。
- 配置加速库环境变量。
export ATB_LAYER_INTERNAL_TENSOR_REUSE=1 export INF_NAN_MODE_ENABLE=0 export ATB_OPERATION_EXECUTE_ASYNC=1 export TASK_QUEUE_ENABLE=1 export ATB_CONVERT_NCHW_TO_ND=1 export LCCL_ENABLE_FALLBACK=1 export ATB_WORKSPACE_MEM_ALLOC_GLOBAL=1 export ATB_CONTEXT_WORKSPACE_SIZE=0 export ATB_LAUNCH_KERNEL_WITH_TILING=1
- 根据实际环境参考以下命令运行。
- 使用0卡单卡运行。
export ASCEND_RT_VISIBLE_DEVICES=0 python infer_llama.py
- 使用0、1卡多卡运行。
export ASCEND_RT_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 --master_port 20038 infer_llama.py
- 使用0卡单卡运行。
- 配置加速库环境变量。
精度测试
bash run.sh pa_fp16 full_BoolQ 1 llama True /data/Llama-2-7b-hf 2
性能测试
bash run.sh pa_fp16 performance [[256, 256],[512,512],[1024,1024],[2048,2048]] 1 llama True /data/llama2-7b 2