精度指标
大语言模型通常采用在标准的benchmark数据集上的测试结果来作为精度指标,以下为常用数据集:
- C-Eval:C-Eval数据集是一个中文大模型的知识评估基准,由上海交通大学、清华大学和爱丁堡大学共同设计完成,旨在评估基于中文语境的基础模型的高级知识和推理能力。该数据集覆盖了人文、社科、理工、其他专业四个大方向,52个学科和四个难度的级别,从中学到大学研究生以及职业考试,一共13948道题目。
- HumanEval:HumanEval数据集是由OpenAI、Anthropic等开发的一个代码生成评测基准测试,包含了164个人工编写的Python编程问题,这些问题覆盖了从基础的字符串操作到复杂的算法设计等多种编程任务。该旨在评估大型语言模型在代码生成方面的能力,尤其是在解决实际编程任务方面的表现。
- BoolQ:BoolQ数据集是是一个用于处理是/否问题的问答数据集,其中包含了15942个例子。这些问题是自然而然产生的,它们是在未经提示和无约束的环境中生成的。每个例子都是一个三元组(问题、段落、答案),并且页面标题可以作为可选的额外上下文。文本对分类的设置类似于现有的自然语言推理任务。
吞吐率指标
吞吐率(Throughput)和时延(Latency)是当前较为通用的衡量大模型推理性能的指标。网络模型的吞吐率定义为网络模型在单位时间内(如1s内)可以推理的最大样本数目。
对于大模型推理,需要额外考虑两点,即大模型首次推理的耗时更长,且推理时延和输入/输出的文字长度相关。多Batch推理和并行推理场景下,大模型推理的吞吐率有差异。因此,测试方案需要根据以下维度进行考虑。
- 输入/输出文字长度:取决于模型本身能力和实际需求,一般覆盖25 ~ 210,对于一些支持长文本的模型,需要支持到8k甚至更高。
- Batch Size:在固定芯片或卡规模情况下,Batch Size测试上限取决于模型参数量或计算量以及本身卡的显存,默认Batch Size覆盖到1 ~ 32。
最终模型吞吐率计算公式如下:
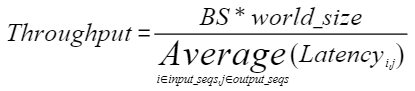
- “BS”为测试数据的Batch Size数目。
- “world_size”为并行推理的进程数。
- “Latency”为不同输入/输出文字长度组合的推理时延。