根据训练任务类型的不同,特性的原理图略有差异。静态vNPU调度需要使用npu-smi工具提前创建好需要的vNPU。
acjob任务
acjob任务原理图如图1所示。
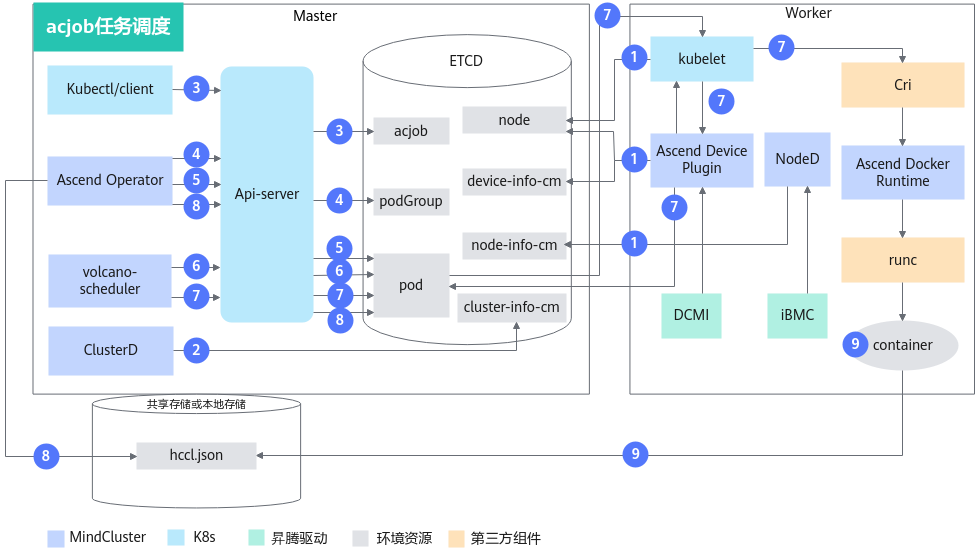
各步骤说明如下:
- 集群调度组件定期上报节点和芯片信息;kubelet上报节点芯片数量到节点对象(node)中。
- Ascend Device Plugin定期上报芯片拓扑信息。
- 上报整卡信息。将芯片的物理ID上报到device-info-cm中;可调度的芯片总数量(allocatable)、已使用的芯片数量(allocated)和芯片的基础信息(device ip和super_device_ip)上报到Node中,用于整卡调度。
- 上报vNPU相关信息到node中,用于静态vNPU调度。
- NodeD定期上报节点健康状态和节点硬件故障信息到node-info-cm中。
- Ascend Device Plugin定期上报芯片拓扑信息。
- ClusterD读取device-info-cm和node-info-cm中信息后,将信息写入cluster-info-cm。
- 用户通过kubectl或者其他深度学习平台下发acjob任务。
- Ascend Operator为任务创建相应的PodGroup。关于PodGroup的详细说明,可以参考开源Volcano官方文档。
- Ascend Operator为任务创建相应的Pod,并在容器中注入集合通信所需环境变量。
- volcano-scheduler根据节点和芯片拓扑信息为任务选择合适节点,并在Pod的annotation上写入选择的芯片信息。
- 整卡调度写入整卡信息。
- 静态vNPU调度写入vNPU相关信息。
- kubelet创建容器时,调用Ascend Device Plugin挂载芯片,Ascend Device Plugin或volcano-scheduler在Pod的annotation上写入芯片信息。Ascend Docker Runtime协助挂载相应资源。
- Ascend Operator读取Pod的annotation信息,将相关信息写入hccl.json。
- 容器读取环境变量或者hccl.json信息,建立通信通道,开始执行训练任务。
vcjob任务
vcjob任务的原理图如图2所示。
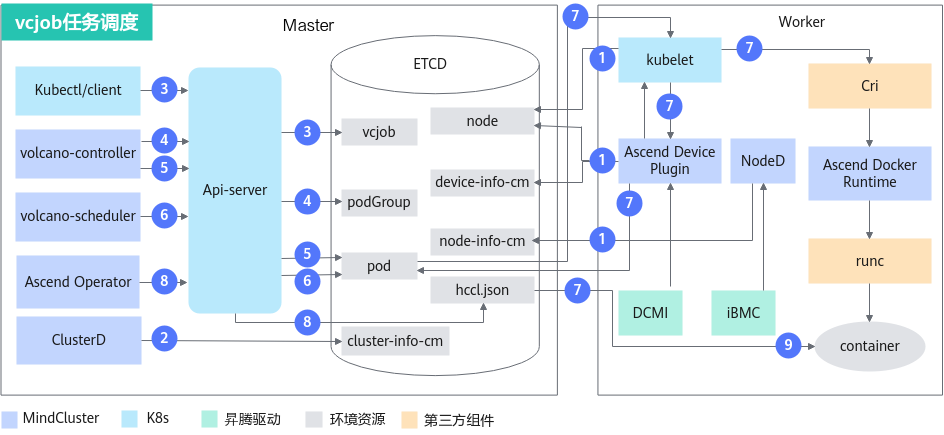
各步骤说明如下:
- 集群调度组件定期上报节点和芯片信息;kubelet上报节点芯片数量到node(节点对象)中。
- Ascend Device Plugin定期上报芯片拓扑信息。
- 上报整卡信息。将芯片的物理ID上报到device-info-cm中;可调度的芯片总数量(allocatable)和已使用的芯片数量(allocated)上报到node中,用于整卡调度。
- 上报vNPU相关信息到node中,用于静态vNPU调度。
- NodeD定期上报节点健康状态和节点硬件故障信息到node-info-cm中。
- Ascend Device Plugin定期上报芯片拓扑信息。
- ClusterD读取device-info-cm和node-info-cm中信息后,将信息写入cluster-info-cm。
- 用户通过kubectl或者其他深度学习平台下发vcjob任务。
- volcano-controller为任务创建相应PodGroup。关于PodGroup的详细说明,可以参考开源Volcano官方文档。
- 当集群资源满足任务要求时,volcano-controller创建任务Pod。
- volcano-scheduler根据节点和芯片拓扑信息为任务选择合适节点,并在Pod的annotation上写入选择的芯片信息。
- 整卡调度写入整卡信息。
- 静态vNPU调度写入vNPU相关信息。
- kubelet创建容器时,调用Ascend Device Plugin挂载芯片,Ascend Device Plugin在Pod的annotation上写入芯片信息。Ascend Docker Runtime协助挂载相应资源,将hccl.json挂载进入容器。
- Ascend Operator获取每个Pod的annotation信息,写入hccl.json。
- 容器读取hccl.json信息,建立通信渠道,开始执行训练任务。
deploy任务
deploy任务原理图如图3所示。
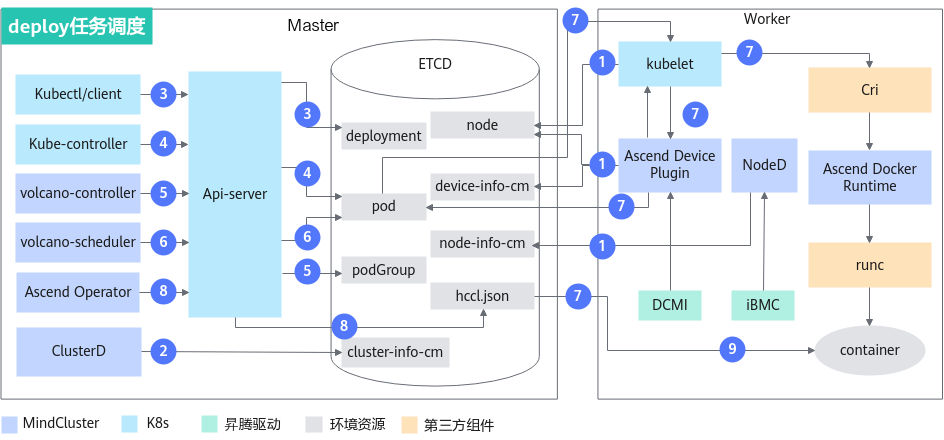
各步骤说明如下:
- 集群调度组件定期上报节点和芯片信息;kubelet上报节点芯片数量到node(节点对象)中。
- Ascend Device Plugin定期上报芯片拓扑信息。
- 上报整卡信息。将芯片的物理ID上报到device-info-cm中;可调度的芯片总数量(allocatable)和已使用的芯片数量(allocated)上报到node中,用于整卡调度。
- 上报vNPU相关信息到node中,用于静态vNPU调度。
- NodeD定期上报节点健康状态和节点硬件故障信息到node-info-cm中。
- Ascend Device Plugin定期上报芯片拓扑信息。
- ClusterD读取device-info-cm和node-info-cm中信息后,将信息写入cluster-info-cm。
- 用户通过kubectl或者其他深度学习平台下发deploy任务。
- kube-controller为任务创建相应Pod。
- volcano-controller创建任务PodGroup。关于PodGroup的详细说明,可以参考开源Volcano官方文档。
- volcano-scheduler根据节点和芯片拓扑信息为任务选择合适节点,并在Pod的annotation上写入选择的芯片信息。
- 整卡调度写入整卡信息。
- 静态vNPU调度写入vNPU相关信息。
- kubelet创建容器时,调用Ascend Device Plugin挂载芯片,Ascend Device Plugin在Pod的annotation上写入芯片信息。Ascend Docker Runtime协助挂载相应资源,将hccl.json挂载进入容器。
- Ascend Operator获取每个Pod的annotation信息,写入hccl.json。
- 容器读取hccl.json信息,建立通信渠道,开始执行训练任务。