问题现象描述
执行kubectl get pod -n vcjob命令获取集群中Pod信息时,显示Pod未正常拉起,并提示:No resources found in vcjob namespace。再执行kubectl get event -n vcjob命令获取集群内的事件信息,报错:0/0 tasks in gang unschedulable: pod group is not ready, 1 minAvailable
原因分析
创建任务后,若任务Pod未处于running状态,可按照以下2种情况进行排查。
- Pod未创建:这种情况下需查看对应的acjob或vcjob描述信息,并查看volcano-controller或Ascend Operator日志,分析任务yaml定义中是否有不合规的字段造成控制器未创建Pod。
- Pod处于pending状态:首先查看podgroup描述信息,确认该状态是由哪种情况导致的。一般来说,存在以下3种情况:nodeSelector、tor-affinity、资源不足。如为nodeSelector、tor-affinity这2种情况,则需分析亲和性。如提示NotEnoughResources,则需按照以下方案进行排查。
解决方案
- 可以通过以下命令查询所有podgroup信息。提示podgroup状态为Inqueue和Pending。
kubectl get pg -n vcjob
回显示例如下:NAME STATUS MINMEMBER RUNNINGS AGE mindx-xxx-16-p-4bf232e4-bd48-438d-9089-02bfef354fce Inqueue 1 37d mindx-dl-deviceinfo-worker-1 Pending 2 88m
- 执行以下命令,查询对应podgroup的详细信息。
kubectl describe pg -n <namespace> <podgroup-name>
<namespace>和<podgroup-name>需要用实际的命名空间和podgroup名称进行替换。
示例命令如下。mindx-dl-deviceinfo-worker-1为步骤1中查询到的podgroup名称。kubectl describe pg -n vcjob mindx-dl-deviceinfo-worker-1
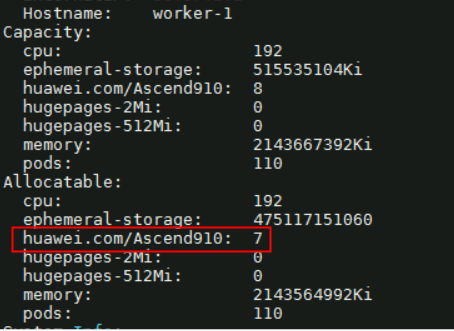
回显示例如下,该回显(加粗部分)示例表示queue资源配额不足。Name: mindx-dl-deviceinfo-worker-1 Namespace: vcjob Labels: fault-scheduling=force ring-controller.atlas=ascend-{xxx}b Annotations: kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"batch.volcano.sh/v1alpha1","kind":"Job","metadata":{"annotations":{},"labels":{"fault-scheduling":"force","ring-controller.... API Version: scheduling.volcano.sh/v1beta1 Kind: PodGroup Metadata: Creation Timestamp: 2023-07-05T09:00:02Z Generation: 7 Owner References: API Version: batch.volcano.sh/v1alpha1 Block Owner Deletion: true Controller: true Kind: Job Name: mindx-xxx-2-p UID: worker-1 Resource Version: 17544644 Self Link: /apis/scheduling.volcano.sh/v1beta1/namespaces/vcjob/mindx-dl-deviceinfo-worker-1 UID: 277cc974-5eec-455f-a860-25d7d19e8335 Spec: Min Member: 1 Min Resources: count/pods: 1 huawei.com/Ascend910: 2 Pods: 1 requests.huawei.com/Ascend910: 2 Min Task Member: Default - Test: 1 Queue: default Status: Conditions: Last Transition Time: 2023-07-05T09:05:46Z Message: 1/0 tasks in gang unschedulable: pod group is not ready, 1 minAvailable Reason: NotEnoughResources Status: True Transition ID: 33585c5e-d3ad-4bc4-be0c-c09bea59520e Type: Unschedulable Phase: Pending Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning Unschedulable 6m22s (x12 over 6m34s) volcano 0/0 tasks in gang unschedulable: pod group is not ready, 1 minAvailable Normal Unschedulable 93s (x280 over 6m34s) volcano queue resource quota insufficient # queue资源配额不足 - 通过如下命令查看K8s中节点的详细情况。如果节点详情中的“Capacity”字段和“Allocatable”字段出现了昇腾AI处理器的相关信息,表示Ascend Device Plugin给K8s上报芯片正常,组件运行正常。
kubectl describe node K8s中的节点名
回显如下所示,提示有个节点Allocatable的huawei.com/Ascend910为7。
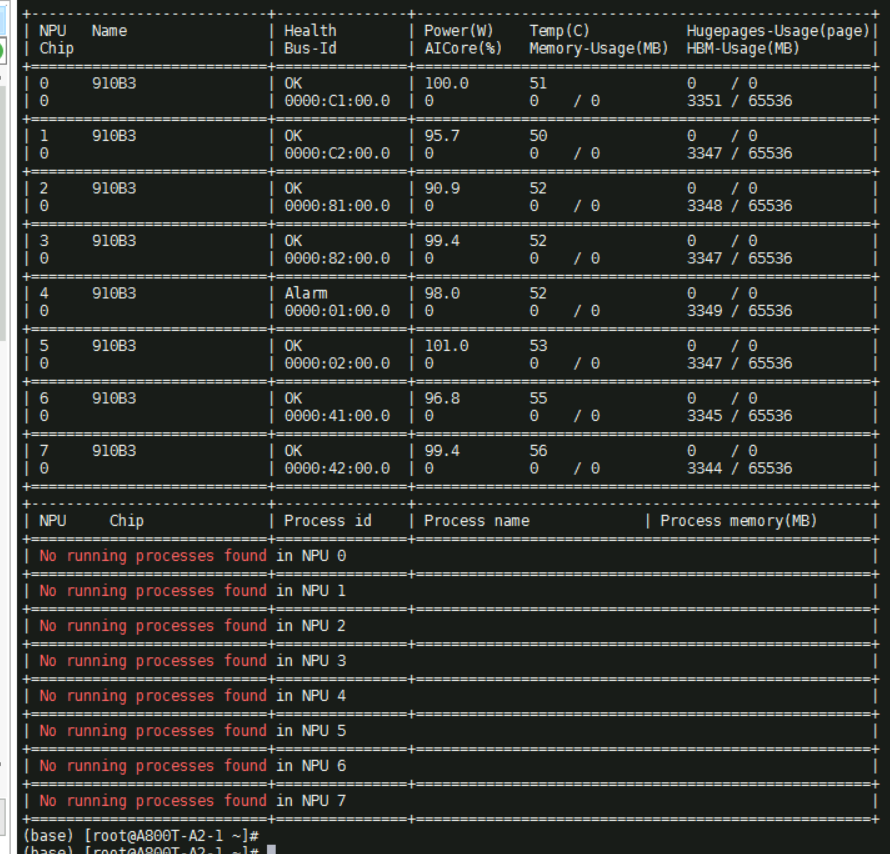
- 执行npu-smi info命令,显示没有正在运行的任务。
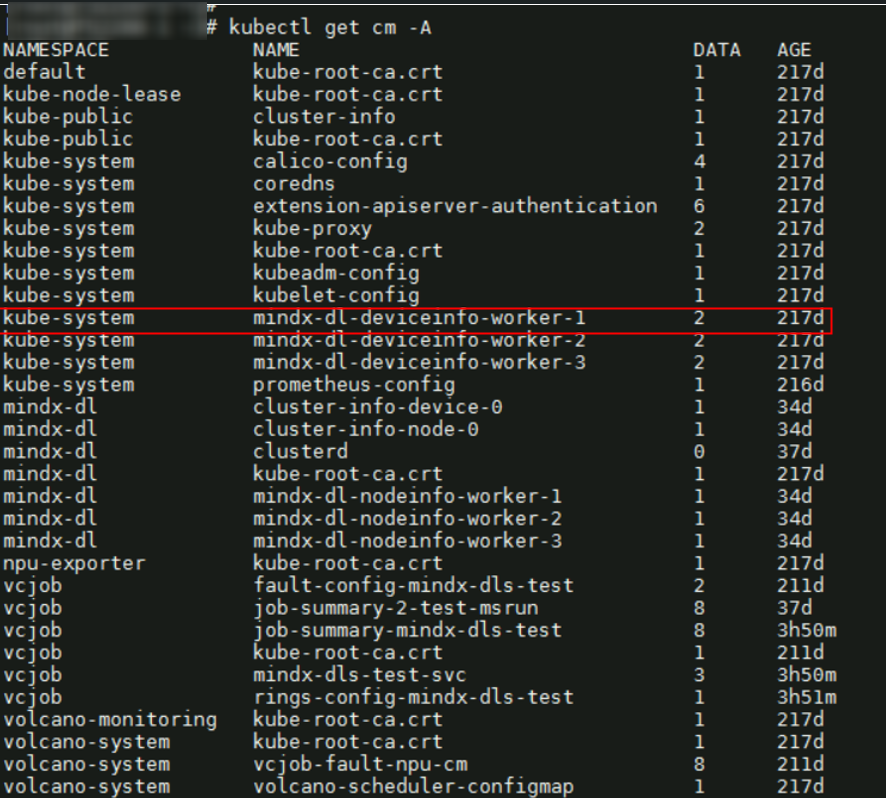
- 执行以下命令,获取集群内所有命名空间。
kubectl get cm -A
回显如下所示。
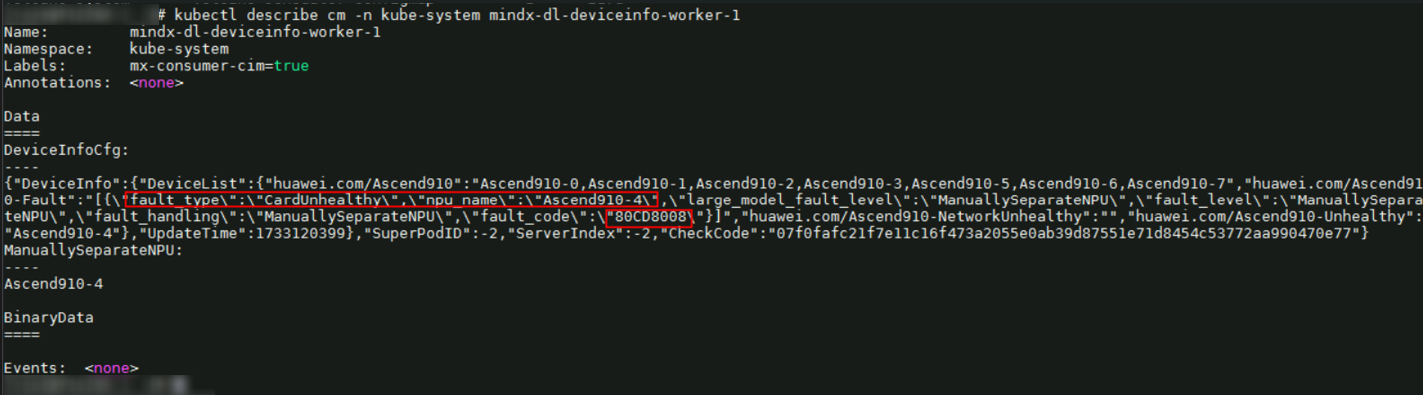
- 执行以下命令,获取Configmap的全部信息。
kubectl describe cm -n kube-system mindx-dl-deviceinfo-worker-1
信息显示NPU device-4 CardUnhealthy,错误码为0x80CD8008。
- 对错误码进行查询,可以查到的故障详细信息如下所示。
表1 故障详细信息 EventID
所属一级模块
所属二级模块
通知类型
故障事件名称
故障解释/可能原因
故障影响
故障自处理模式
0x80CD8008
芯片故障
L2BUFF
故障事件
L2BUFF多bit ECC错误
片内SRAM软失败,导致L2BUFF多bit错误。
系统停止响应,数据错误或可能出现一致性错误。
1.上报故障事件到设备
2.记录错误日志
- 重启服务器。
- 重启后会恢复正常。如不能恢复正常(Configmap状态显示Ascend910-4还是Unhealthy)则需用户确认该卡是否可用。
- 如确认该卡可用,则执行以下命令编辑Configmap,并删除异常信息ManuallySeparateNPU。
kubectl edit cm -n kube-system mindx-dl-deviceinfo-worker-1
删除异常信息后,问题已解决。

- 如确认该卡发生硬件故障,请联系华为工程师处理。
- 如确认该卡可用,则执行以下命令编辑Configmap,并删除异常信息ManuallySeparateNPU。