断点续训基于故障检测能力获取集群和训练业务的故障状态,根据检测结果进行故障处理。当前,断点续训特性主要提供以下几个方面的故障检测能力:昇腾硬件故障、训练业务故障、其他故障发送方的故障。
MindCluster集群调度组件Ascend Device Plugin提供NPU芯片故障检测能力及NPU参数面网络故障检测能力,NodeD提供服务器节点故障、总线设备网络故障检测能力,ClusterD提供公共故障检测能力,Volcano提供业务面容器异常检测能力,故障检测整体架构如下图所示。
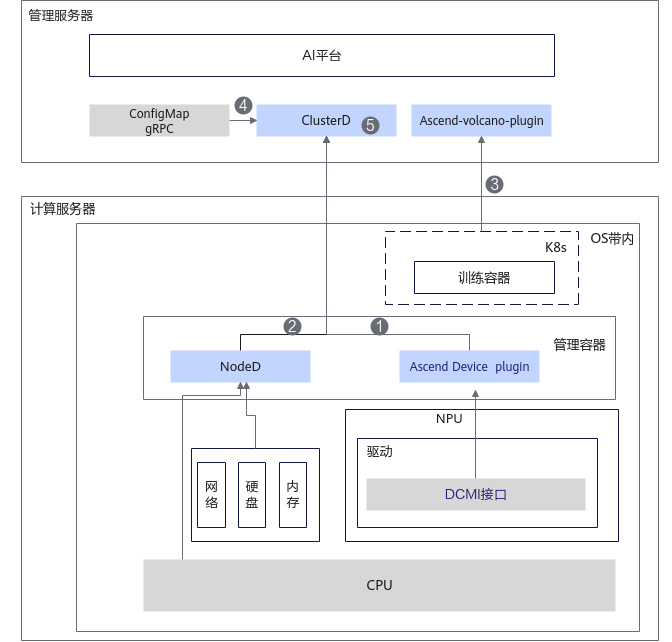
- 计算服务器上的Ascend Device Plugin通过驱动获取NPU芯片故障以及参数面网络故障后,将故障信息上报到管理服务器。
- 计算服务器上的NodeD通过驱动获取服务器节点故障、总线设备网络故障信息后,将故障信息上报到管理服务器。
- 计算服务器上的K8s监测训练容器状态,训练容器异常后上报到K8s中,管理服务器上的Volcano通过K8s获取训练容器的故障信息。
- 管理服务器上的ClusterD通过公共故障接口获取公共故障后,将接收到的信息进行汇总写入cluster-info-device-cm。
- (可选)管理服务器上的ClusterD将汇总收集集群内所有Ascend Device Plugin和NodeD上报的故障信息。
支持的故障模式
当前已支持200+故障的检测。支持的故障类型请参见表1,详细的故障说明请参见典型故障.xlsx。
故障类型 |
故障说明 |
|---|---|
节点故障 |
包括节点健康状态和节点硬件故障。 说明:
若节点的硬件故障导致节点宕机或重启,则NodeD无法检测到具体的故障类型并上报。 |
芯片故障 |
DCMI接口上报的芯片故障和设备网络探测工具hccn_tool检测到的芯片网络故障。故障码说明请参见芯片故障码参考文档。 |
参数面网络故障 |
包括芯片网络相关故障和总线设备故障。
|
业务面故障 |
训练任务异常退出,导致Pod的Status变为Failed状态。 说明:
可执行kubectl describe pod {pod名称} -n {NAMESPACE} |grep Status:命令,查看当前Pod的Status是否为Failed状态。回显示例如下:
Status: Failed |
公共故障 |
公共故障指的是其他故障发现者(非MindCluster组件)提供的故障,公共故障包括以下几种类型:NPU故障、节点故障、网络故障和存储故障。 |
总线设备网络故障 |
总线设备网络故障是针对超节点内部(包括节点内和节点间)的HCCS网络提供的NPU网络故障检测。 |
性能劣化故障 |
MindCluster结合MindStudio提供的profiling能力对集群中的性能劣化故障(慢节点)提供诊断功能。该功能提供动态使能打点和打点数据持久化功能、可动态启停,无需重启任务进行诊断,对训练无损耗。 |
ConfigMap说明
- 每个计算节点的Ascend Device Plugin均会创建记录本节点NPU和总线设备信息的ConfigMap文件。该ConfigMap文件名为mindx-dl-deviceinfo-<nodename>(以下简称device-info-cm),故障信息会通过该ConfigMap进行上报。该ConfigMap文件中各字段的说明,请参见表1。
- 每个计算节点的NodeD均会创建记录本节点设备信息的ConfigMap文件。该ConfigMap文件名为mindx-dl-nodeinfo-<nodename>(以下简称node-info-cm),节点故障信息会通过该ConfigMap进行上报。该ConfigMap文件中各字段的说明,请参见表1。
- ClusterD会创建记录本集群设备信息的ConfigMap文件,该ConfigMap文件名为cluster-info-<device/node/switch>-<[0-5]>(以下简称cluster-info-cm)和pingmesh-fault-<nodename>。节点及芯片故障信息会通过cluster-info-cm进行上报。总线设备网络故障信息通过pingmesh-fault-<nodename>进行上报。
- 创建每个任务时,需要在YAML中配置ConfigMap文件,该ConfigMap文件名称为reset-config-<job-name>(以下简称reset-info-cm)。该ConfigMap挂载到容器的“/user/restore/reset/config”路径下。Ascend Device Plugin会自动将ConfigMap挂载到本节点的“/user/restore/reset/<job-namespace>.<job-name>”路径下。
也可以将节点上/user/restore/reset/<job-namespace>.<job-name>替代ConfigMap,挂载到容器的“/user/restore/reset/config”路径下。该ConfigMap文件字段说明,请参见表3。