断点续训特性支持通过Volcano调度器感知并处理因业务面故障导致的任务失败。业务面故障是因容器内的训练进程均异常退出后引起容器异常退出,导致Pod的Status变为Failed状态。在使用Ascend Operator的场景下,业务面故障仅支持任务的部分Pod发生故障的场景,若任务所有Pod在几秒内Status都转变为Failed,任务不会发生重调度,认定任务为失败状态Ascend Operator在使用。
业务面故障发现原理如图1所示。
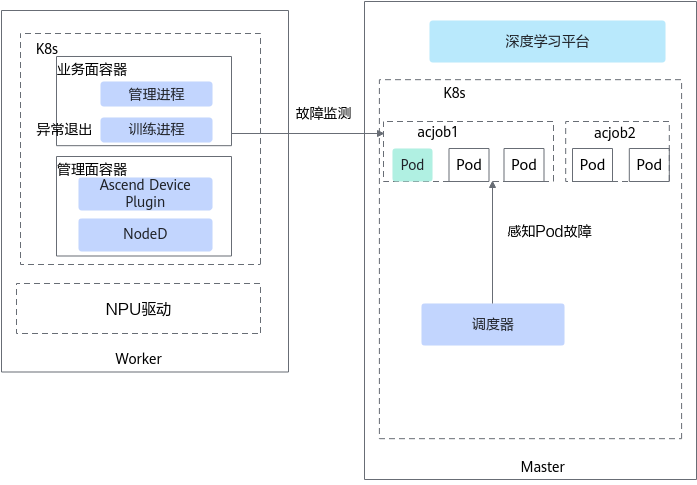
调度器不断轮询地查询每个任务的Pod状态,从而感知到业务面故障并上报该故障。用户可根据具体业务需求对业务面故障做处理。断点续训获取到业务面故障后,Volcano会检测是否开启无条件重试功能,开启后会将任务重新调度到未导致本次训练任务重调度的新节点,并重新执行训练任务,重试次数减1;当重试次数为0或者没有开启无条件重试功能时,不会对业务容器故障进行处理。

- 如需使用无条件重试功能,需在任务YAML中配置以下3个参数:fault-retry-times,restartPolicy及policies,详细参数说明请参见YAML参数说明。
- 在使用Ascend Operator的场景下,若希望任务所有Pod的Status在转变为Failed后仍发生重调度,可参考使用Volcano和Ascend Operator组件场景下,业务面故障的任务所有Pod的Status全部变为Failed,任务无法触发无条件重试重调度。
watchdog故障检测
NPU上Task执行异常(业务面故障)可能导致任务中正常NPU无法与故障NPU通讯,使正常NPU集合通信陷入超时等待状态,并使任务集合通信出现等待超时异常后才退出(默认为30分钟)。开启watchdog功能(需同时开启业务面故障无条件重试能力),可以在该异常发生后,隔离故障NPU,将任务重调度到健康的NPU上,从而实现6分钟内使任务快速退出。
NPU上Task执行异常仅支持Atlas A2 训练系列产品的PyTorch框架使用watchdog功能。
支持的故障处理类型
Job级别重调度、Pod级别重调度、进程级别重调度、优雅容错