NPU的参数面网络故障包括芯片网络相关故障和总线设备故障。
参数面网络出现故障时,将导致训练任务中断或者训练任务性能较差。总线设备发生故障后,MindCluster集群调度组件将根据故障级别进行相应的重调度处理。

- 参数面网络故障不会直接触发任务重调度,当参数面故障导致训练任务异常中断时才触发任务重调度。
- 如果需要对参数面网络故障进行故障处理,需要同时开启业务面故障无条件重试能力。开启业务面故障无条件重试需要在任务YAML中同时配置以下3个参数:fault-retry-times,restartPolicy及policies。关于参数的详细说明请参见YAML参数说明。
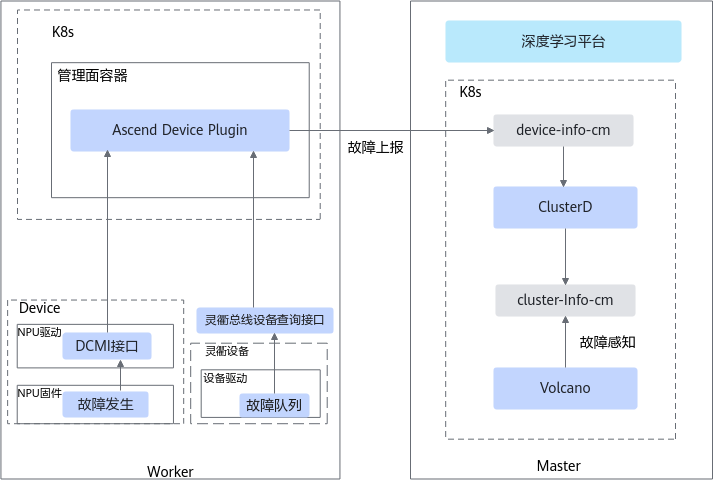
参数面网络故障检测由设备管理组件Ascend Device Plugin负责,详细原理如图1所示。

关键步骤说明
芯片网络故障:
- NPU定时检测和网关地址的通信是否正常,探测周期为2.5秒,通过故障管理框架上报结果。
- RoCE驱动实时监测NPU网口Link状态,通过故障管理框架上报Linkdown或Linkup事件。
- Ascend Device Plugin通过DCMI接口从故障管理框架获取信息,通过轮询的方式查询网关探测结果,并实时订阅网口Linkdown或Linkup事件并进行上报。Ascend Device Plugin统计网关检测异常持续时间、Linkdown持续时间。如果小于或等于RoCE网络超时时间(默认为20秒)则标记为NPU网络故障(默认不处理,可能会引起参数面网络故障);如果大于20秒,则升级成配置的故障等级。
总线设备故障:
- 总线设备将设备发生的故障写入本地队列中。
- 查询接口通过查询上述队列,将故障缓存至查询接口,并进行汇总处理。
- Ascend Device Plugin通过订阅或轮询的方式调用接口获取总线设备相关故障,并写入device-info-cm进行上报。
故障上报机制
- 芯片发生网络故障时,NPU故障管理框架获取故障信息后,将该信息上报给NPU驱动。NPU驱动收到故障信息后,通过DCMI接口上报给Ascend Device Plugin。Ascend Device Plugin通过DCMI接口获取芯片健康状态。当前提供如下两种获取模式:
- 故障订阅模式。Ascend Device Plugin启动时会先调用DCMI故障订阅接口注册监测,故障发生或恢复时,驱动通过该接口将故障发生或恢复事件上报给Ascend Device Plugin。
- 故障轮询模式。每隔固定时间,通过故障查询接口查询芯片故障状态。当设备驱动不支持订阅能力时将切换该模式。
- 总线设备发生故障时,Ascend Device Plugin通过查询接口获取故障信息,当前故障查询提供两种模式:
- 故障订阅模式:在Ascend Device Plugin启动过程中向查询接口注册故障处理回调。故障发生后,该回调被调用后将故障上报给Ascend Device Plugin,故障恢复时通过该接口上报恢复事件。
- 故障轮询模式:Ascend Device Plugin每隔5分钟调用一次全量故障查询接口。
Ascend Device Plugin上报机制
Ascend Device Plugin获取到参数面网络故障后,将故障信息写入到device-info-cm中,并通过ConfigMap的形式上报给K8s。device-info-cm中各字段的说明,请参见表1。
Ascend Device Plugin的故障上报机制如图2所示。
watchdog故障检测
参数面网络链路异常(参数面网络故障)可能导致任务中正常NPU无法与故障NPU通信,使所有NPU集合通信陷入超时等待状态;并使任务集合通信出现等待超时异常后才退出(默认为30分钟)。
开启watchdog功能(且开启了业务面故障无条件重试能力)可以在参数面网络链路异常发生后,隔离故障NPU,将任务重调度到健康的NPU上,从而实现6分钟内使任务快速退出。
仅支持在PyTorch及MindSpore框架下使用watchdog功能。
支持的故障处理类型
Job级别重调度、Pod级别重调度、进程级别重调度
(可选)配置故障检测的级别
断点续训针对参数面故障提供了默认的故障级别以及对应级别的故障处理策略,若用户需要修改故障处理策略可参见参数面网络故障。若无特殊需求,请勿随意修改。