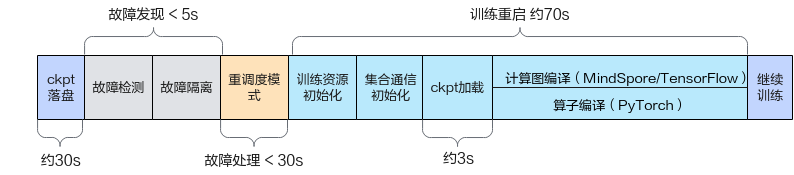
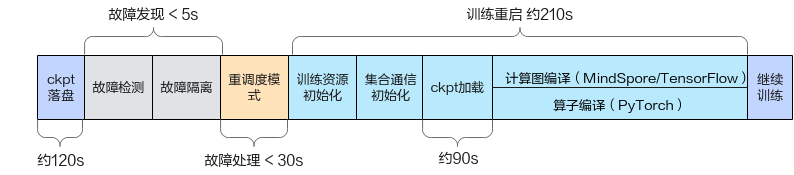
断点续训特性可以在训练发生故障后恢复训练,降低故障导致的训练损失。断点续训的故障整体恢复时间可以分为训练回滚时间和训练拉起时间,如图1所示。

训练回滚时间
训练出现故障后会丢失原有的训练数据,需要从保存的ckpt文件中恢复训练。在大模型训练中,由于每次保存ckpt会降低训练效率,因此通常1小时以上才会保存一次ckpt文件,每次故障后将会丢失上次保存ckpt时间点到当前故障时间点的训练数据。训练回滚时间即使用上次保存的ckpt文件训练到出现故障点的时间。设平均训练回滚时间为T0,ckpt保存周期为Gf,则故障平均训练回滚时间T0=Gf/2。
训练拉起时间
训练出现故障后,需要重新拉起训练任务,恢复训练容器及训练进程,完成资源重调度、集合通信初始化、ckpt加载和编译等流程后继续往后训练。训练故障后需要完整走完一段训练拉起时间后才能继续训练,训练拉起时间过长会导致资源浪费。设资源重调度时间为T1,集合通信时间为T2,ckpt加载时间为T3,编译时间为T4,因此训练拉起时间为T1+T2+T3+T4。
单次故障总训练损失时间T=T0+T1+T2+T3+T4。具体的时间参考请参见训练恢复耗时参考。

其中每部分时间与参数规模和集群规模相关,网络与存储性能也会影响总训练损失时间。