在K8s(Kubernetes)集群中训练任务出现故障时,断点续训特性使系统能够感知故障,将故障资源进行处理或隔离,并根据训练任务需要重新分配资源,通过周期性保存或临终保存的ckpt重新拉起训练任务,缩短损失时间。
各功能所需组件
每个功能所需组件如表1所示;其中√表示该功能需要集成该组件使用;-表示该功能不需要集成该组件使用。
断点续训整体架构
断点续训架构原理如图1所示。
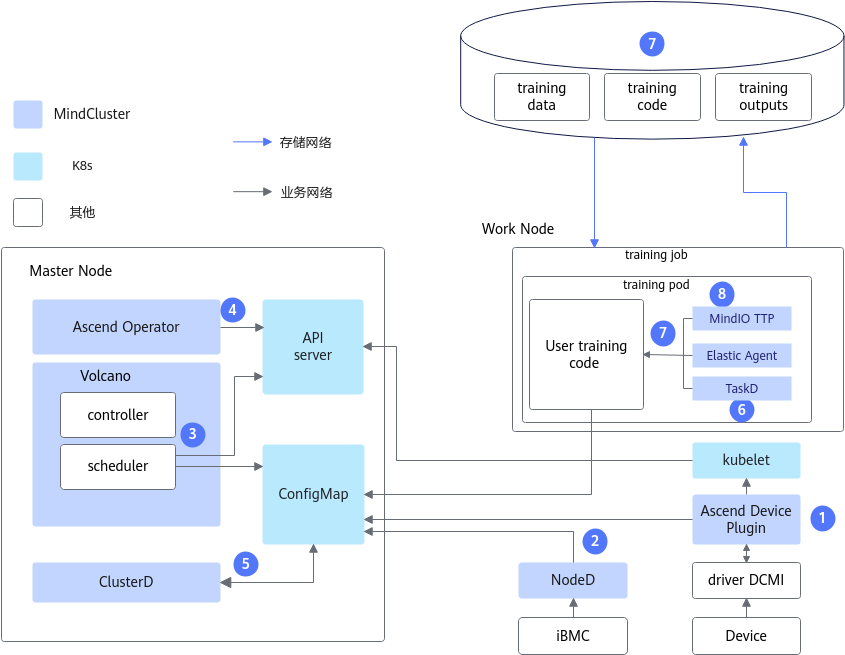
其中各组件的能力如下:
- Ascend Device Plugin:故障发现组件,提供NPU资源管理、NPU芯片故障和NPU网络故障上报等能力。
- NodeD:故障发现组件,提供节点健康状态、节点硬件(包括CPU、内存、芯片等部件)故障、总线设备网络故障上报能力。
- Volcano:故障处理组件,提供故障任务重调度的能力。
- Ascend Operator:为分布式训练任务创建Pod生成环境变量;提供静态组网集合通信所需的RankTable信息。
- ClusterD:获取集群中所有Ascend Device Plugin和NodeD上报的数据,整理后发送给Volcano。
- TaskD:提供昇腾设备上训练及推理任务的训练状态监测和训练状态控制能力。
- Elastic Agent:提供与K8s集群的训练集群控制中心的通信功能,完成故障修复、恢复训练。
- MindIO TTP:在大模型训练过程中发生故障后,校验中间状态数据的完整性和一致性,生成一次临终CheckPoint数据,恢复训练时能够通过该CheckPoint数据恢复,减少故障造成的训练迭代损失。
- 训练模型代码:需要进行断点续训相关能力的适配操作。
端到端流程
断点续训特性基于故障触发,触发成功后经过故障检测、故障恢复和训练恢复三个阶段后可恢复训练。
图2 端到端流程
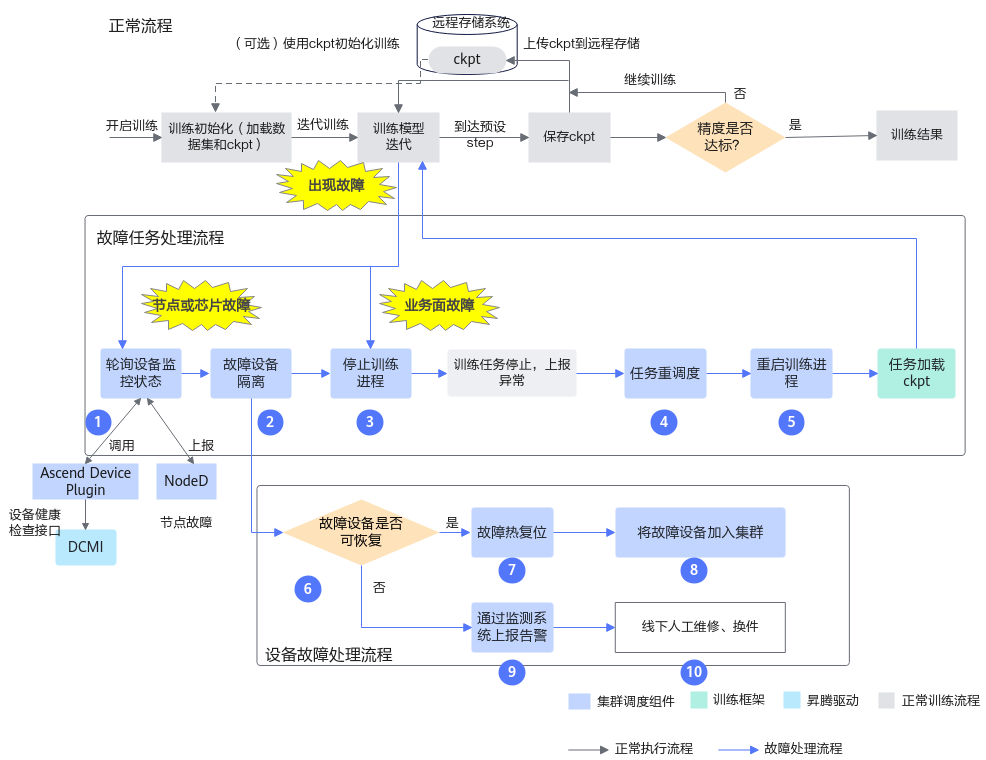
各步骤说明如下:
- 通过轮询的方式查询设备状态,Ascend Device Plugin从DCMI接口获取NPU状态以及NodeD上报的节点健康状态、节点硬件故障信息,ClusterD整理所有的故障信息,确定最终故障状态后,上报给Volcano。
- 查询到节点或芯片故障后,对故障节点或芯片进行隔离,防止再次调度到该设备上。
- 停止训练进程,退出训练容器。
- 节点或芯片故障后,系统会将训练任务重调度到健康的设备上,重启训练容器;该训练任务被重调度选择资源时,优先选用未导致本次训练任务重调度的节点。
- 训练脚本重新拉起训练进程。
- 运维人员可以根据节点或芯片的故障类型判断是否可进行热复位。
- 进行故障热复位,使设备恢复健康状态。
- 恢复后的设备自动重新加入集群中。
- 不可恢复的设备通过运维监测系统上报告警。
- 对不可恢复的设备进行线下人工维修和换件。
业务面故障触发的断点续训功能,将只执行上述步骤3~步骤5。
组件调用流程
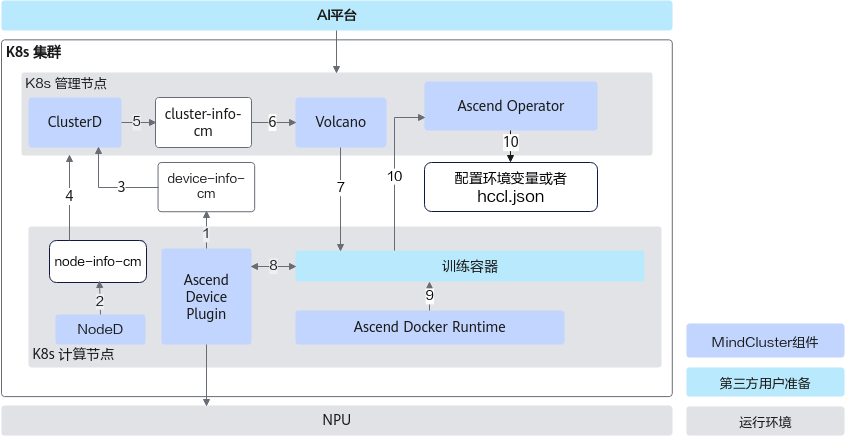
各步骤说明如下:
- Ascend Device Plugin发现和上报故障及健康状态。
- NodeD更新节点状态和节点硬件故障信息,以便Volcano可以准确判断节点故障类型。
- ClusterD根据Ascend Device Plugin提供的芯片信息,判断芯片是否健康。
- ClusterD获取节点的状态及节点硬件故障(如CPU、内存、硬盘故障)。
- ClusterD将收集来的芯片及节点信息汇总后,放入ConfigMap。
- Volcano获取整个集群的设备信息,健康设备用于新任务的调度,故障设备若存在任务,Volcano会将任务调度到其他健康设备上。
- Volcano按照亲和性规则选择节点和芯片,并由Ascend Operator创建新的Pod后,再调度训练任务到符合要求的节点上。
- Ascend Device Plugin根据Pod上Volcano指定的芯片ID来分配芯片,并将芯片IP信息写入容器。
- 容器启动之前,Ascend Docker Runtime为训练容器自动挂载NPU相关设备,驱动so等文件和目录。
- Ascend Operator将训练任务需要的相关环境变量(如集合通信信息和训练配置信息等)写入容器中。并且获取训练任务容器上的芯片信息,自动生成分布式训练任务需要的通信集合信息。
名称 |
类型 |
功能说明 |
|---|---|---|
AI平台 |
用户提供 |
通过用户的AI平台在K8s集群中创建训练任务。 |
NodeD |
MindCluster提供,已开源 |
上报节点状态、节点硬件故障、总线设备网络故障信息。 |
Ascend Device Plugin |
MindCluster提供,已开源 |
芯片的发现与上报,故障检查与上报,执行芯片热复位。 |
Volcano |
MindCluster提供,已开源 |
负责调度基于芯片的训练任务,检查故障并重调度发生故障的训练任务。 |
Ascend Operator |
MindCluster提供,已开源 |
负责为不同AI框架的分布式训练任务提供相应的环境变量、生成分布式通信集合配置文件。 |
Ascend Docker Runtime |
MindCluster提供,已开源 |
负责为训练容器挂载芯片及驱动SO等文件。 |
ClusterD |
MindCluster提供,已开源 |
收集集群所有的节点或芯片故障信息,整理后上报。 |
NPU |
- |
NPU芯片,AI平台中的训练资源。 |
使用条件
- 使用断点续训功能需要安装的组件详见所需组件章节。
- 断点续训特性是基于MindCluster集群调度组件的高阶特性,使用断点续训特性前需要完成的准备工作详见K8s和共享存储准备章节。