亲和性调度是指通过减少资源碎片和减少网络拥塞,最大化利用昇腾AI处理器算力。
- 减少资源碎片
任务部署后,尽量将剩余昇腾AI处理器集中在网络更通畅的单元(如节点、超节点或同一交换机下的节点)内;避免因资源分散造成昇腾AI处理器总数足够,但是任务却无法调度的场景。
- 减少网络拥塞
昇腾AI处理器之间存在多种网络连接方式。不同产品内昇腾AI处理器的互联方式不同;产品之间根据组网的不同,昇腾AI处理器的互联方式也不同;不同的连接方式之间,网络带宽差异较大。根据不同的昇腾AI处理器互联方式,选用不同的调用策略,可以减少网络拥塞。
基于昇腾AI处理器的亲和性调度
在硬件产品内部,有三种芯片链接方式。他们的调度优先级为:优先将任务调度到同一张推理卡或者训练卡内的昇腾AI处理器中;其次调度到使用HCCS互联的昇腾AI处理器中;最后调度到使用PCIe互联的昇腾AI处理器中。

HCCS(Huawei Cache Coherence System)是HCCL(Huawei Collective Communication Library)的硬件形态,HCCL提供了深度学习训练场景中服务器间高性能集合通信的功能。
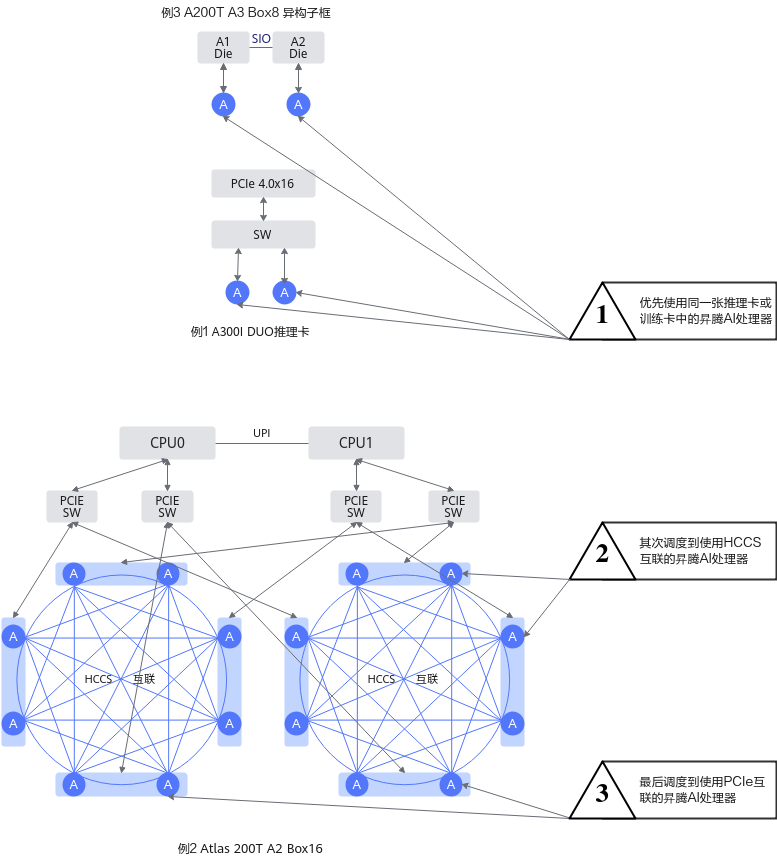
不同的硬件产品内部,可能包含这三种链接方式的一种或多种,具体的调度策略如下所示:
硬件形态 |
昇腾AI处理器互联方式 |
减少网络拥塞 |
减少资源碎片 |
|---|---|---|---|
Atlas 训练系列产品 |
4个昇腾AI处理器通过HCCS互联;HCCS环间昇腾AI处理器通过PCIe互联。 |
申请4个及以下昇腾AI处理器的任务调度到一个HCCS环上。 |
若两个资源的网络情况一致,则选择调度后产生的资源碎片少的资源。 |
Atlas 200T A2 Box16 异构子框 |
8个昇腾AI处理器通过HCCS互联;HCCS环间昇腾AI处理器通过PCIe互联。 |
|
若两个资源的网络情况一致,则选择调度后产生的资源碎片少的资源。 |
Atlas 900 A3 SuperPoD 超节点 A200T A3 Box8 超节点 Atlas 800I A3 超节点 |
2个昇腾AI处理器通过SIO互联,形成8个HiAM模组;每个HiAM模组通过HCCS互联。 |
申请的昇腾AI处理器个数为偶数时,必须调度到同一个HiAM模组上。 |
- |
Atlas 800 推理服务器(型号 3000)(插Atlas 300I 推理卡) |
每张推理卡内4个昇腾AI处理器互联,推理卡间不互联。 |
申请的昇腾AI处理器的个数为小于4,且配置了按推理卡调度时,该任务一定调度到一张推理卡上。 |
若两个资源的网络情况一致,则选择调度后产生的资源碎片少的资源。 |
Atlas 800 推理服务器(型号 3000)(插Atlas 300I Duo 推理卡) |
每张推理卡内2个昇腾AI处理器通过HCCS互联,推理卡间通过PCIe互联。 |
分布式推理调度,必须将任务调度到整张Atlas 300I Duo 推理卡。 若任务需要的昇腾AI处理器数量为单数时,使用单个昇腾AI处理器的部分,将优先调度到剩余昇腾AI处理器数量为1的Atlas 300I Duo 推理卡。 |
若两个资源的网络情况一致,则选择调度后产生的资源碎片少的资源。 |
基于节点的亲和性调度
节点间通过RoCE网络或者总线设备+RoCE网络连接。调度任务时,优先使用总线设备网络。RoCE网络采用
- 采用RoCE连接的产品:Atlas 800T A2 训练服务器,Atlas 800I A2 推理服务器,A200I A2 Box 异构组件、Atlas 200T A2 Box16 异构子框,Atlas 800 训练服务器(型号 9000)和Atlas 800 训练服务器(型号 9010)
- 采用RoCE连接单层连接的产品:Atlas 800I A2 推理服务器、A200I A2 Box 异构组件
- 采用总线网络+RoCE连接的产品:Atlas 900 A3 SuperPoD 超节点
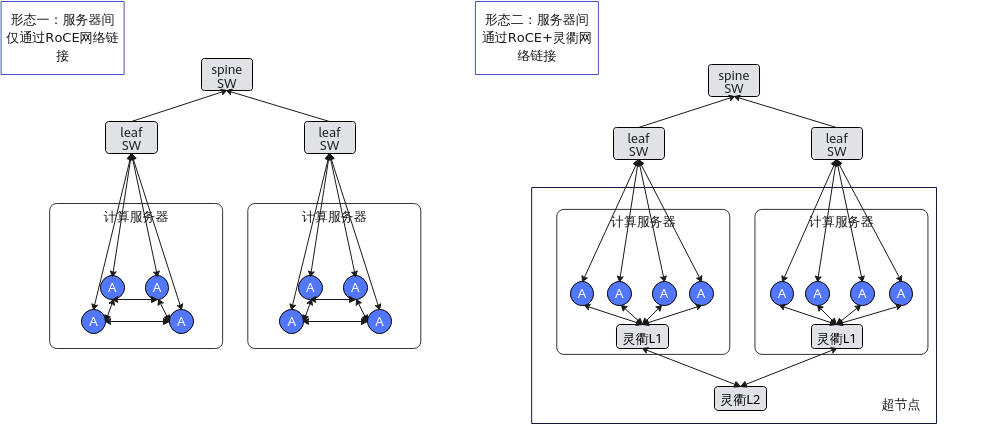
互联方式 |
昇腾AI处理器互联方式 |
调度方式 |
减少网络拥塞 |
减少组网成本 |
减少资源碎片 |
|---|---|---|---|---|---|
RoCE连接双层互联 |
通过Spine+Leaf全局双层互联 |
交换机亲和性调度1.0 |
|
- |
若两个资源的网络情况一致,则选择调度后产生的资源碎片少的资源。 |
通过Spine+Leaf全局双层互联 |
交换机亲和性调度2.0 |
|
- |
||
RoCE连接单层连接 |
通过Leaf单层连接 |
单层交换机亲和性调度 |
- |
使用单层组网即可满足参数面互联要求,大大降低组网成本。 |
|
总线设备+RoCE |
通过Spine+Leaf全局互联,通过总线设备网络形成多个超节点 |
逻辑超节点亲和性调度 |
根据任务的切分策略,获取网络通信需求高的网络亲和单元。保证每一个网络亲和单元都是分布在一个总线设备网络下。 |
- |