重调度场景
芯片故障的重调度场景故障处理流程如图1所示,以acjob任务(使用Ascend Operator)为例。
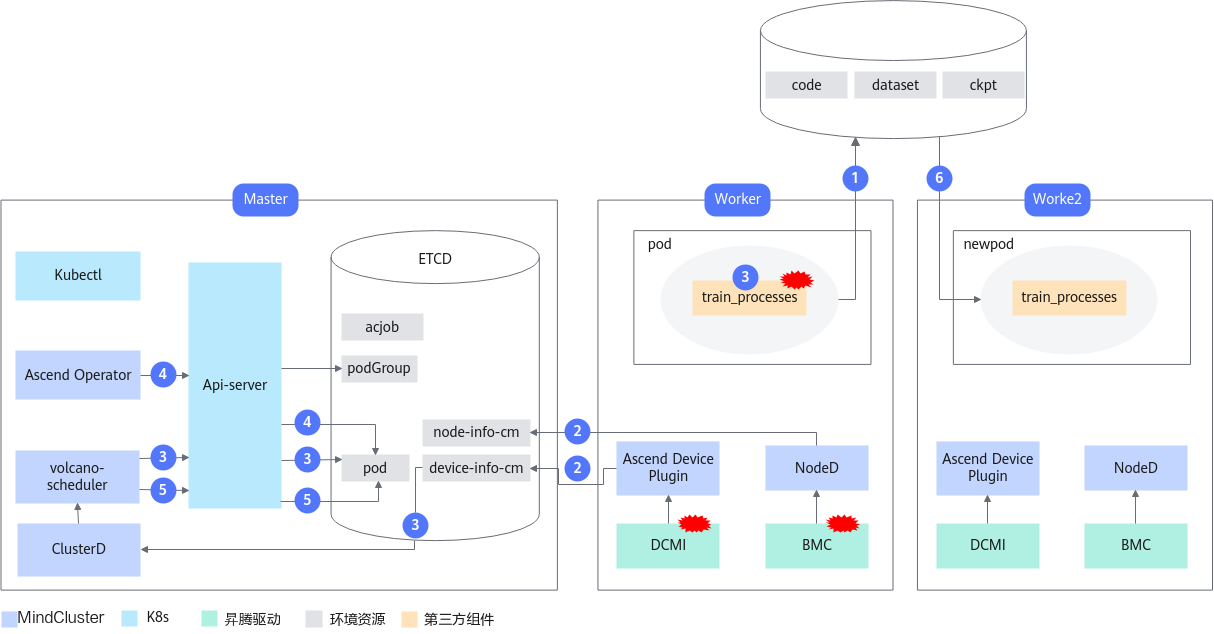
各步骤说明如下:
- 任务运行过程中,Ascend Operator持续监测Pod数量及状态、ClusterD持续监测device-info-cm和node-Info-cm。
- NodeD、Ascend Device Plugin分别上报故障信息到node-Info-cm和device-info-cm中。
- ClusterD读取device-info-cm中信息并上报给Volcano,Volcano根据ClusterD上报信息删除使用了故障芯片的任务的所有Pod。
- Ascend Operator重新创建所有Pod,并写入新的环境变量。
- volcano-scheduler为新Pod选择合适的节点。
- Pod在新节点重新拉起,从远端存储拉取之前保存的ckpt,继续训练。
默认删除使用了故障芯片的任务的所有Pod,若用户使用Pod级别重调度功能,则只删除故障芯片所在Pod,重新创建并拉起该Pod。
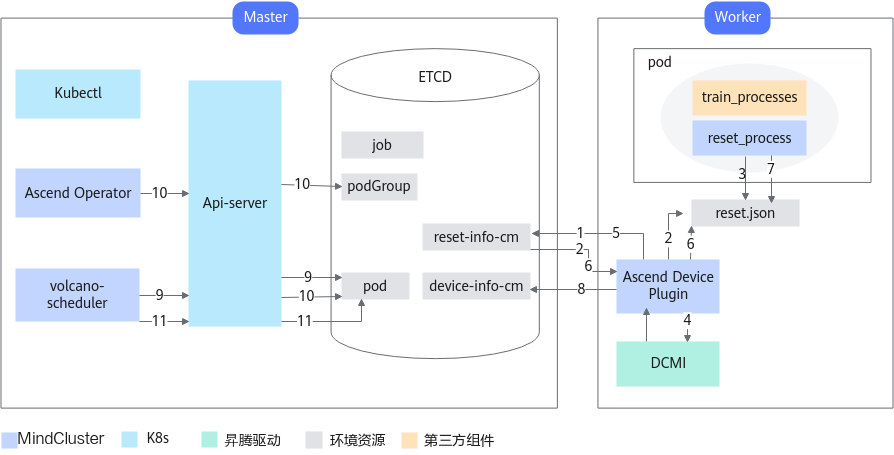
各步骤说明如下:
- Ascend Device Plugin上报故障信息到K8s的reset-info-cm中。
- 所有节点Ascend Device Plugin读取reset-info-cm,写入本地reset.json文件中。
- reset_process读取reset.json,删除所有训练进程。
- Ascend Device Plugin在所有训练进程退出后,调用DCMI接口对故障芯片执行复位操作。
- 若复位操作成功,Ascend Device Plugin重写reset-info-cm。
- 所有节点Ascend Device Plugin读取reset-info-cm,写入本地reset.json件中。
- reset_process读取reset.json,将所有训练进程重新拉起。
- 若热复位失败,Ascend Device Plugin将故障信息上报到device-info-cm。
- volcano-scheduler删除所有Pod。
- Ascend Operator重新创建podGroup和Pod。
- volcano-scheduler重新调度Pod。
- 步骤8~11表示优雅容错失败。优雅容错调用DCMI接口对故障芯片执行复位操作失败时,将重试4次,每次重试分别等待5、10和15秒,若4次(超过30秒)均未成功复位,则回退至重调度模式。
- 重调度模式默认删除使用了故障芯片的任务的所有Pod,若用户使用Pod级别重调度功能,则只删除故障芯片所在Pod,重新创建并拉起该Pod。