断点续训针对节点故障中节点硬件故障和芯片故障的不同故障码,提供了默认的故障级别和对应级别的故障处理策略;芯片故障还提供了默认的故障频率和时长,以及对应的故障处理策略。
故障发生后,根据上报的故障信息进行故障处理,分为不同级别的重调度模式和优雅容错功能。
重调度模式
- 重调度模式:将任务调度到健康的芯片上,并隔离故障芯片。
重调度模式默认为Job级别重调度,每次故障会停止所有的Pod,但在大规模任务中,停止所有Pod后再重调度的成本较高,存在故障恢复时间过长的问题。除此以外断点续训还提供Pod级别重调度功能,用户可根据任务规模配置,在故障时刻只停止故障相关的Pod后重调度少量Pod,从而达成故障的快速恢复。为了进一步缩短故障恢复时间、降低故障影响范围,断点续训还提供进程级别重调度及进程级在线恢复功能。
重调度级别的详细说明如表1所示。
表1 重调度级别说明 重调度的级别
功能介绍
使用约束
Job级别重调度
每次故障会停止所有的Pod,重新创建并重调度所有Pod,重启训练任务。
-
Pod级别重调度
每次故障只停止故障相关的Pod,重新创建并重调度故障相关的Pod后,重启训练任务。不能恢复则回退至Job级重调度模式。
相比于作业级快速恢复会减少部分资源调度、Pod创建的时间。
在大集群训练任务中使用Pod级别重调度时,建议设置open files参数(可以打开的最大文件数目)足够大,设置过小可能导致Pod重调度出现异常。例如执行ulimit -n 100000命令,将open files参数设置为100000。
进程级别重调度(进程级恢复)
每次故障只停止故障相关节点的进程,将故障节点的容器迁移到健康节点,恢复训练任务。不能恢复则回退至Job级或Pod级重调度模式。
相比于进程级快速恢复(优雅容错),本功能仅重调度故障进程,减少了大量进程间不同步的等待耗时,同时利用了新的HCCL建链方案大大降低了建链耗时,且通过NPU卡间的参数面高速网络P2P传递CKPT信息,避免了CKPT保存和加载的耗时。
- 只支持单容器迁移,不支持按照亲和性迁移。
- 模型并行策略需要存在优化器副本。
- 不支持MC2开启场景。
- 不支持多模态模型。
- 不支持开启watchdog故障检测功能。
进程级在线恢复
- 针对片上内存上出现的不可纠正错误(如故障码0x80E01801),对训练进程进行Step重试,并隔离故障片上内存空间,实现进程不退出的故障快速恢复。不能恢复则回退至重调度模式。
- 该故障处理模式默认关闭,若要开启请参考(可选)配置组件。
- 支持PyTorch框架。
- 依赖于PyTorch的内存管理机制,仅在PYTORCH_NO_NPU_MEMORY_CACHING未配置时才能使用此功能。
- 针对部分片上内存故障场景无法生效,例如HCCL集合通信使用的内存地址故障,仍需通过进程级重调度或更上层的容错方案恢复。
- 模型并行策略需要存在优化器副本。
- 不支持多模态模型。

- 进程级重调度及进程级在线恢复的版本配套关系如下:MindCluster 6.0.0.SPC1 版本及配套的解决方案版本。
- 当训练任务的annotation中hccl/rankIndex字段为0的Pod发生故障时,不触发Pod级别重调度和进程级别重调度,直接触发Job级别重调度。
- 进程级别重调度及进程级在线恢复通过寻找有效的副本,拼凑出一份完整的优化器状态数据,当训练集群故障较多,通过副本仍然无法拼凑出一个完整副本时,则会无法完成重调度。
- 针对MindSpeed-LLM、MindSpeed等模型或训练脚本中定义的全局变量发生故障的场景,详细处理策略请参见FAQ。
- 优雅容错功能与进程级别重调度、进程级在线恢复功能不能同时开启。若同时开启,断点续训将通过Job级别重调度恢复训练。
- 进程级别重调度和进程级在线恢复功能需在MindIO和ClusterD侧同时打开或关闭,不支持开启一侧开关的同时关闭另一侧开关。若用户配置错误,断点续训将通过Job级别重调度或Pod级别重调度恢复训练。
- 请勿使用configmap挂载RankTable文件,否则可能会导致任务重调度失败。
- 重调度模式存在以下两种重调度策略。
- 直接重调度:训练过程中发生集群调度组件可以探测到的硬件故障,系统将故障节点或芯片进行隔离,直接对任务进行重调度。
- 无条件重试:训练过程中发生集群调度组件不能探测到的故障,导致任务容器异常退出,系统无条件对任务进行重调度。
表2 重调度策略说明 重调度策略
说明
支持的故障类型
直接重调度
系统将故障的节点或芯片进行隔离,然后直接对任务进行重调度。
已知的节点故障或重调度处理级别芯片故障。
无条件重试
系统对配置了无条件重试次数的任务,进行指定次数内的重调度。
成功重调度后,任务可重试次数将减1,当可重试次数为0时无法再次触发重调度。
说明:如需使用无条件重试功能,需在yaml中配置fault-retry-times参数,详细参数说明请参见yaml参数说明。
由于参数面网络故障或者训练相关软件故障等,导致任务异常退出,Pod的Status变为Failed状态的相关故障。
优雅容错功能
随着大模型训练的集群规模扩大,训练资源紧缺,在无空闲设备时,可能导致节点或芯片故障后,任务无法重调度并陷入Pending状态。重调度模式在节点或芯片故障后,需要运维人员手动恢复设备,恢复不及时可能导致训练集群中出现大量散点故障,降低集群算力利用率。
因此,断点续训在重调度模式上增加了优雅容错功能,用于优化NPU芯片的部分故障容错能力。NPU芯片故障中的部分故障可以通过退出芯片上的训练进程以及热复位芯片来恢复,优雅容错功能即针对这部分故障进行恢复处理,不需要重调度任务。
Ascend Device Plugin负责故障的上报以及设备的恢复,管理进程根据Ascend Device Plugin上报的信息进行训练进程的停止与重新拉起,完成故障恢复,不能恢复则回退至重调度模式。集成优雅容错模式需要在业务容器中添加管理进程,管理进程需要具备故障感知、停止训练任务和重启训练任务等能力。
优雅容错功能只支持芯片故障。
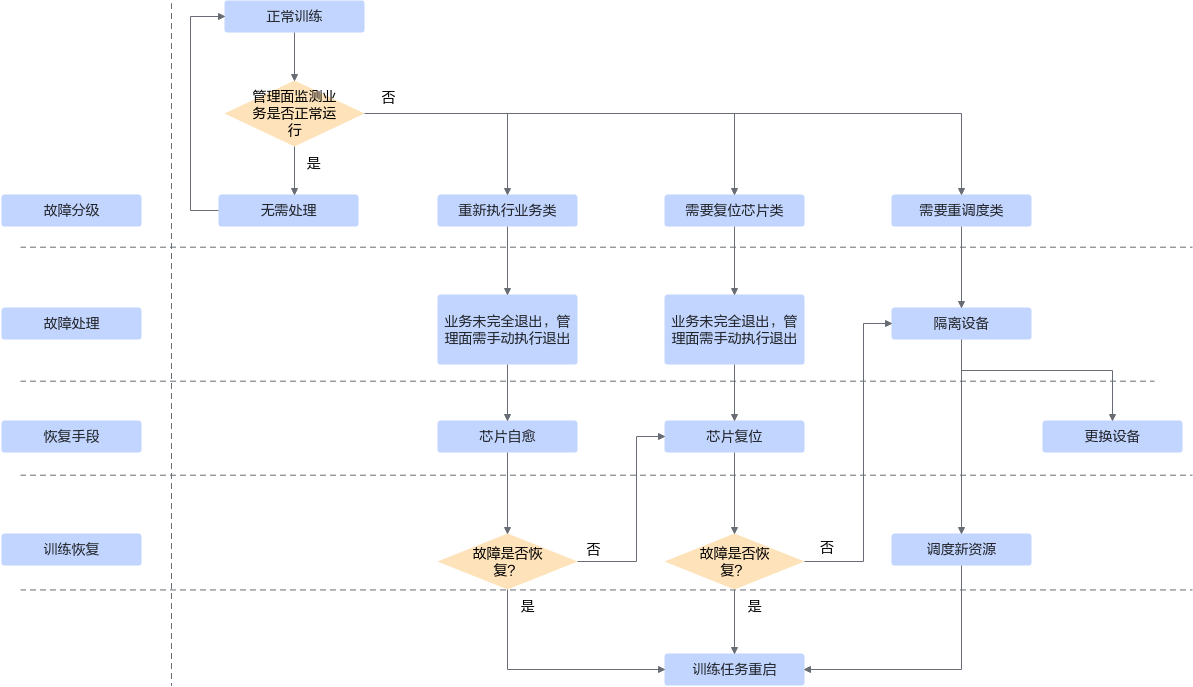
重调度模式将故障区分为两类:无需处理和需要重调度。优雅容错模式将故障区分为以下四类,无需处理、重新执行业务、需要复位芯片和需要重调度,对于每类故障的处理如图1所示。
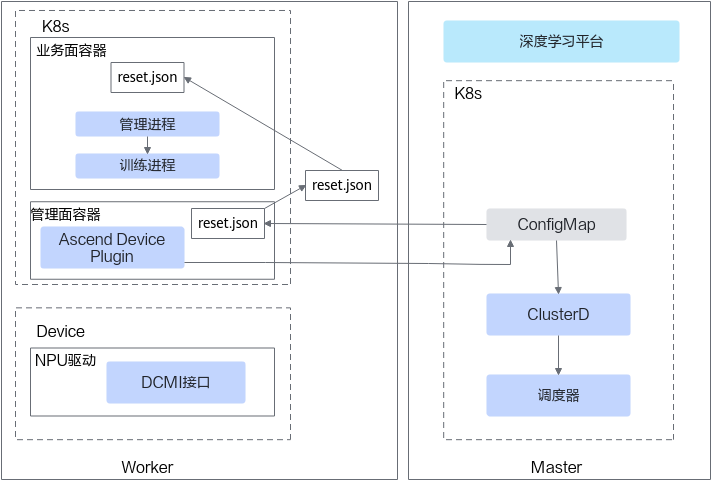
优雅容错模式直接将故障上报到业务容器内的管理进程中(通常通过挂载文件的方式),容器内的管理进程读取故障文件信息获取到故障信息,获取故障信息的流程如图2所示。
watchdog故障检测
- 参数面网络链路异常(参数面网络故障)可能导致任务中正常NPU无法与故障NPU通信,使所有NPU集合通信陷入超时等待状态;并使任务集合通信出现等待超时异常后才退出(默认为30分钟)。开启watchdog功能(且开启了业务面故障无条件重试能力)可以在参数面网络链路异常发生后,6分钟内使任务快速退出,触发重调度模式的无条件重试,将任务重调度到健康的NPU上,并隔离故障NPU。
- NPU上Task执行异常(业务面故障)可能导致任务中正常NPU无法与故障NPU通讯,使正常NPU集合通信陷入超时等待状态,并使任务集合通信出现等待超时异常后才退出(默认为30分钟)。开启watchdog功能(且开启了业务面故障无条件重试能力)可以在该异常发生后,6分钟内使任务快速退出,触发重调度模式的无条件重试,将任务重调度到健康的NPU上,并隔离故障NPU。
- 参数面网络链路异常仅支持PyTorch框架使用watchdog功能。
- NPU上Task执行异常仅支持Atlas A2 训练系列产品的PyTorch框架使用watchdog功能。
- watchdog功能仅支持重调度模式,不支持使用优雅容错模式。