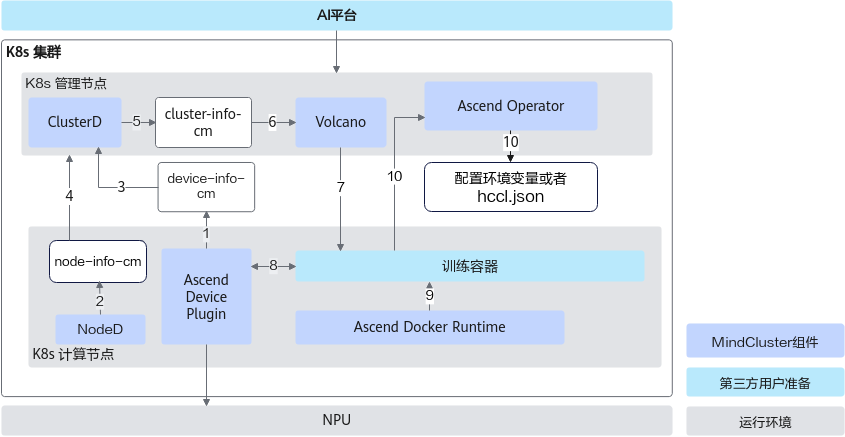
各步骤说明如下:
- Ascend Device Plugin发现和上报故障、健康状态。
- NodeD更新节点状态和节点硬件故障信息,以便Volcano可以准确判断节点故障类型。
- ClusterD根据Ascend Device Plugin提供的芯片信息,确定芯片是否正常。
- ClusterD获取节点的状态及节点硬件故障(如CPU、内存、硬盘故障)。
- ClusterD将收集来的芯片、节点信息汇总后放入ConfigMap。
- Volcano获取整个集群的设备信息,健康设备用于新任务的调度,故障设备若存在任务,Volcano将会将其调度到其他健康设备上。
- Volcano按照亲和性规则选择节点和芯片,并调度训练任务到符合要求的节点上。
- Ascend Device Plugin根据Pod上Volcano指定的芯片ID来分配芯片,并将芯片IP信息写到容器上。
- 容器启动之前,Ascend Docker Runtime为训练容器自动挂载NPU相关设备,驱动so等文件和目录。
- Ascend Operator将训练任务需要的相关环境变量(如集合通信信息和训练配置信息等)写入容器中。并且获取训练任务容器上的芯片信息,自动生成分布式训练任务需要的通信集合信息。
名称 |
类型 |
功能说明 |
|---|---|---|
AI平台 |
用户提供 |
通过用户的AI平台在K8s集群中创建训练任务 |
NodeD |
MindCluster提供,已开源 |
用于上报节点状态以及节点硬件故障 |
Ascend Device Plugin |
MindCluster提供,已开源 |
用于芯片的发现与上报,故障检查与上报,执行芯片的热复位 |
Volcano |
MindCluster提供,已开源 |
负责正常调度基于芯片的训练任务,检查故障并重调度故障的训练任务 |
Ascend Operator |
MindCluster提供,已开源 |
Ascend Operator负责为不同AI框架的分布式训练任务提供相应的环境变量、生成分布式通信集合配置文件。 |
Ascend Docker Runtime |
MindCluster提供,已开源 |
负责为训练容器挂载芯片、驱动SO等文件 |
ClusterD |
MindCluster提供,已开源 |
收集集群所有的节点或芯片故障信息,整理后上报 |
NPU |
- |
NPU芯片,AI平台中的训练资源 |