避免父子进程嵌套
对父子进程事先进行职责区分,父进程负责创建子进程,子进程负责调度推理,避免父子进程同时调度推理,造成资源抢占问题。在实际使用中,请在fork()执行后再在返回的父子进程中执行模型推理。程序逻辑示意图如图1所示。
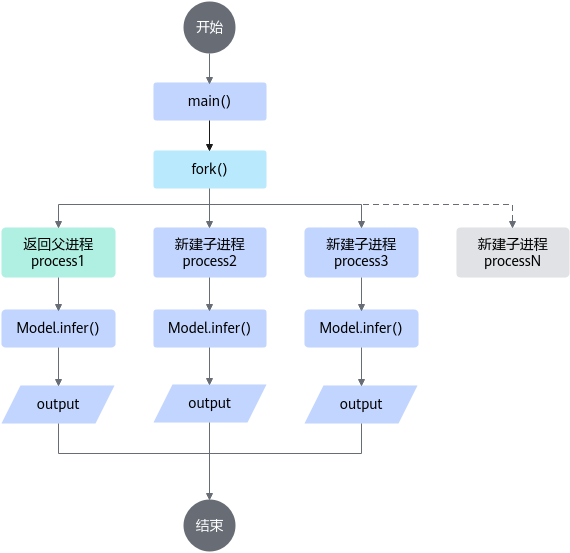
采用不同Device执行推理任务
若业务上需要父子进程嵌套,则规范对于Device的指定,避免父子进程同时在同一Device上执行推理,而是将二者的推理指定到不同Device上。程序逻辑如图2和图3所示。
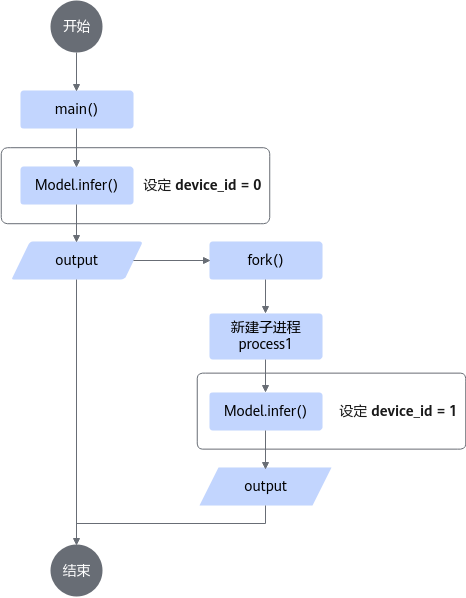
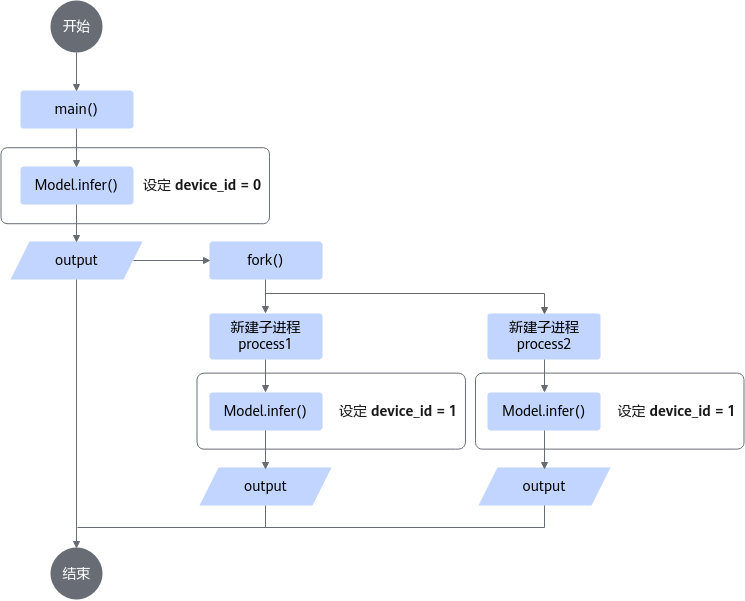
子进程推理在前,父进程推理在后
若业务需要父子进程嵌套,建议先让子进程进行推理, 再调用父进程推理,但此解决方案在调用逻辑上来讲比较难以理解,因此不推荐使用、程序调用逻辑如图4所示。
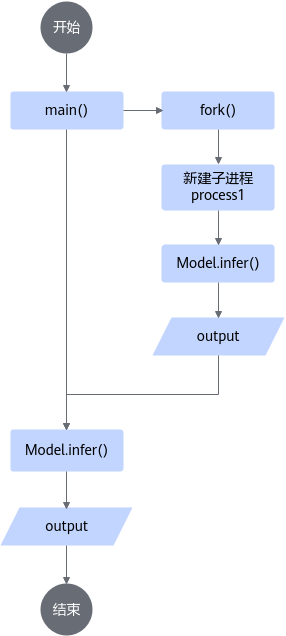
示例代码
int main(){
// 下文的func()函数代表一个完整的推理任务
// 以下为推荐的多进程调用方式,请在fork()后于返回的父子进程中调用推理
pid_t pid;
int i;
for (i = 0; i < 5; ++i)
{
pid = fork(); //创建子进程
if (pid == -1)
{
perror("fork失败!");
exit(1);
}
if (pid==0)
{
break;
}
}
//返回大于0的进程就是父进程
if(pid>0) //父进程
{
printf("父进程: pid= %d , ppid=%d,子进程: %d \n", getpid(),getppid(),pid);
func(); //在fork()后进行调用推理
sleep(1); //这里延迟父进程程序,等子进程先执行完。
}
else if(pid == 0) //子进程
{
func(); //在fork()后进行调用推理
printf("i的变量是: %d 子进程: pid= %d , ppid=%d \n", i,getpid(),getppid());
}
return 0;
}