功能
Mistral 7B,Attention部分在GQA(Group Query Attention)的基础上,叠加了SWA(Sliding Window Attention)的优化,可以进一步提高推理速度,并降低显存。
当前FA算子在进行推理时采用的是取所有KV进行计算,可以应用SWA提升推理速度,越远距离的信息,对当前位置的重要性越低,对于距离超过窗口大小的两个token不参与注意力分数计算。
通过设计mask实现n>m或m-n>windowLen(n为kvId, m为qId)时,注意力分数跳过计算。如图1,若windowSize = 3, “The”将不会计算与“the”之间的注意力分数。
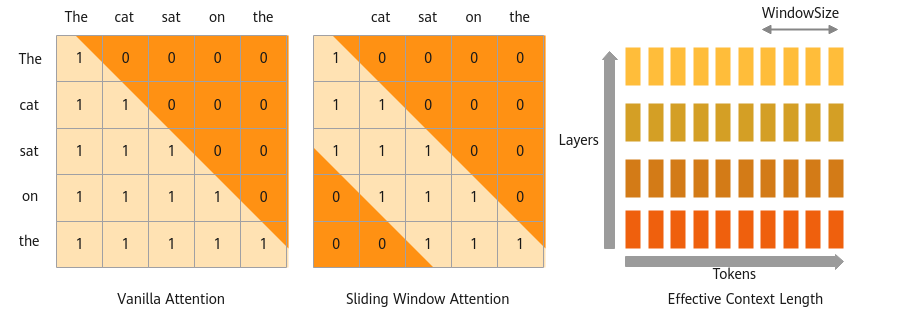
Decoder支持仅长度为windowLen的最新KV历史参与计算。
kvCache优化:比如窗口大小=4,则当第5个token需要缓存,直接替换掉第1个token,这样就可以保持kv缓存有一个最大值(为窗口大小),而不会无限增长。
开启方式
- windowSize > 0
- maskType必须为MASK_TYPE_SLIDING_WINDOW_NORM或MASK_TYPE_SLIDING_WINDOW_COMPRESS
特殊约束
- 开启特性后“cacheType”可以为CACHE_TYPE_NORM 或 CACHE_TYPE_SWA, 不开启特性“cacheType”只能为 CACHE_TYPE_NORM。
- Sliding Window Attention特性不支持动态batch,高精度,clamp缩放,qkv全量化,mla,logN缩放特性,BNSD数据排布。
- Sliding Window Attention特性在calcType=DECODER场景下,“maskType”不能为MASK_TYPE_SLIDING_WINDOW_COMPRESS,且不传入attentionMask。
- 开启特性必须满足以下两个条件。如果只满足一个条件,会校验报错。
- windowSize > 0。
- maskType必须为MASK_TYPE_SLIDING_WINDOW_NORM或MASK_TYPE_SLIDING_WINDOW_COMPRESS。
SWA mask样例生成参考
当windowSize >= seqlen时,mask和不开启SWA时一样,为上三角,否则mask生成可参考如下:
- maskType=MASK_TYPE_SLIDING_WINDOW_NORM, dtype为float16。
以 max(seqLen)为5,windowSize为3为例。
图2 maskType=MASK_TYPE_SLIDING_WINDOW_NORM, dtype为float16时的mask样例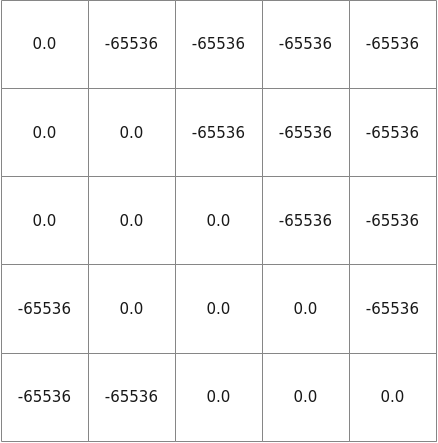
python代码示例:
1 2 3 4
swa_mask = np.ones(shape=[maxseq,maxseq]) * -65536.0 triu_mask = np.triu(swa_mask, 1) tril_mask = np.tril(swa_mask, -window_size) swa_mask = triu_mask + tril_mask
C++代码示例:
1 2 3 4 5 6 7 8 9 10 11 12
static constexpr uint32_t SWA_MASK_SIZE = maxSeq; std::vector<float> create_attention_mask(uint32_t windowSize, uint32_t embeddim) { std::vector<float> attention_mask(SWA_MASK_SIZE * SWA_MASK_SIZE, -65536.0); for (uint32_t i = 0; i < SWA_MASK_SIZE; ++i) { uint32_t offset = i >= windowSize ? (i - windowSize + 1) : 0; for (uint32_t j = offset; j < i + 1; ++j) { attention_mask[i * SWA_COMPRESS_MASK_SIZE + j] = 0.0; } } return attention_mask; }
- maskType=MASK_TYPE_SLIDING_WINDOW_NORM, dtype为bf16。
以 max(seqLen)为5,windowSize为3为例。
图3 maskType=MASK_TYPE_SLIDING_WINDOW_NORM, dtype为bf16时的mask样例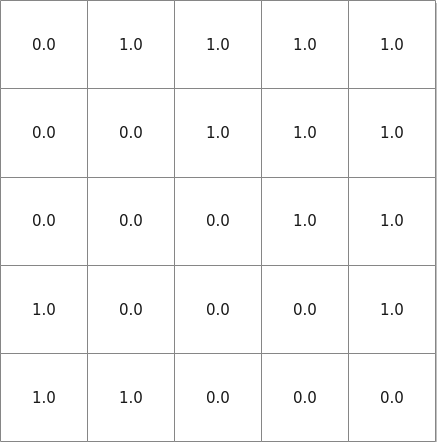
python代码示例:
1 2 3 4
swa_mask = np.ones(shape=[maxseq,maxseq]) * 1.0 triu_mask = np.triu(swa_mask, 1) tril_mask = np.tril(swa_mask, -window_size) swa_mask = triu_mask + tril_mask
C++代码示例:
1 2 3 4 5 6 7 8 9 10 11 12
static constexpr uint32_t SWA_MASK_SIZE = maxSeq; std::vector<float> create_attention_mask(uint32_t windowSize, uint32_t embeddim) { std::vector<float> attention_mask(SWA_MASK_SIZE * SWA_MASK_SIZE, 1.0); for (uint32_t i = 0; i < SWA_MASK_SIZE; ++i) { uint32_t offset = i >= windowSize ? (i - windowSize + 1) : 0; for (uint32_t j = offset; j < i + 1; ++j) { attention_mask[i * SWA_COMPRESS_MASK_SIZE + j] = 0.0; } } return attention_mask; }
- maskType=MASK_TYPE_SLIDING_WINDOW_COMPRESS, dtype为float16。
python代码示例:
1 2 3 4 5 6 7 8 9 10 11 12
swa_mask = np.ones(shape=(1, 512, 512)) * -65536.0 pp_n = 128 if head_size <= 128 else 64 # head_size为每个注意力头的嵌入向量的大小 if window_size <= pp_n * 3: true_size = window_size else: if window_size % pp_n == 0: true_size = pp_n * 3 else: true_size = pp_n * 2 + window_size % pp_n triu_mask = np.triu(swa_mask, 1) tril_mask = np.tril(swa_mask, -true_size) swa_mask = triu_mask + tril_mask
C++代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13
static constexpr uint32_t SWA_COMPRESS_MASK_SIZE = 512; std::vector<float> create_attention_mask(uint32_t windowSize, uint32_t embeddim) { std::vector<float> attention_mask(SWA_COMPRESS_MASK_SIZE * SWA_COMPRESS_MASK_SIZE, -65536.0); uint32_t blockSize = embeddim > 128 ? (16384 / embeddim / 16 * 16) : 128; uint32_t compressWindow = windowSize > 3 * blockSize ? (2 * blockSize + windowSize % blockSize) : windowSize; for (uint32_t i = 0; i < SWA_COMPRESS_MASK_SIZE; ++i) { uint32_t offset = i >= compressWindow ? (i - compressWindow + 1) : 0; for (uint32_t j = offset; j < i + 1; ++j) { attention_mask[i * SWA_COMPRESS_MASK_SIZE + j] = 0.0; } } return attention_mask; }
- maskType=MASK_TYPE_SLIDING_WINDOW_COMPRESS, dtype为bf16。
python代码示例:
1 2 3 4 5 6 7 8 9 10 11 12
swa_mask = np.ones(shape=(1, 512, 512)) * 1 pp_n = 128 if head_size <= 128 else 64 # head_size为每个注意力头的嵌入向量的大小 if window_size <= pp_n * 3: true_size = window_size else: if window_size % pp_n == 0: true_size = pp_n * 3 else: true_size = pp_n * 2 + window_size % pp_n triu_mask = np.triu(swa_mask, 1) tril_mask = np.tril(swa_mask, -true_size) swa_mask = triu_mask + tril_mask
C++代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13
static constexpr uint32_t SWA_COMPRESS_MASK_SIZE = 512; std::vector<float> create_attention_mask(uint32_t windowSize, uint32_t embeddim) { std::vector<float> attention_mask(SWA_COMPRESS_MASK_SIZE * SWA_COMPRESS_MASK_SIZE, 1.0); uint32_t blockSize = embeddim > 128 ? (16384 / embeddim / 16 * 16) : 128; uint32_t compressWindow = windowSize > 3 * blockSize ? (2 * blockSize + windowSize % blockSize) : windowSize; for (uint32_t i = 0; i < SWA_COMPRESS_MASK_SIZE; ++i) { uint32_t offset = i >= compressWindow ? (i - compressWindow + 1) : 0; for (uint32_t j = offset; j < i + 1; ++j) { attention_mask[i * SWA_COMPRESS_MASK_SIZE + j] = 0.0; } } return attention_mask; }