功能
OmniAttention在Decode阶段通过对LLM特定的Layer的特定Head进行Attention稀疏计算达到节省KV Cache显存、降低片上内存搬运数据量到缓存、减少Attention计算量的性能增益。
算子上下文
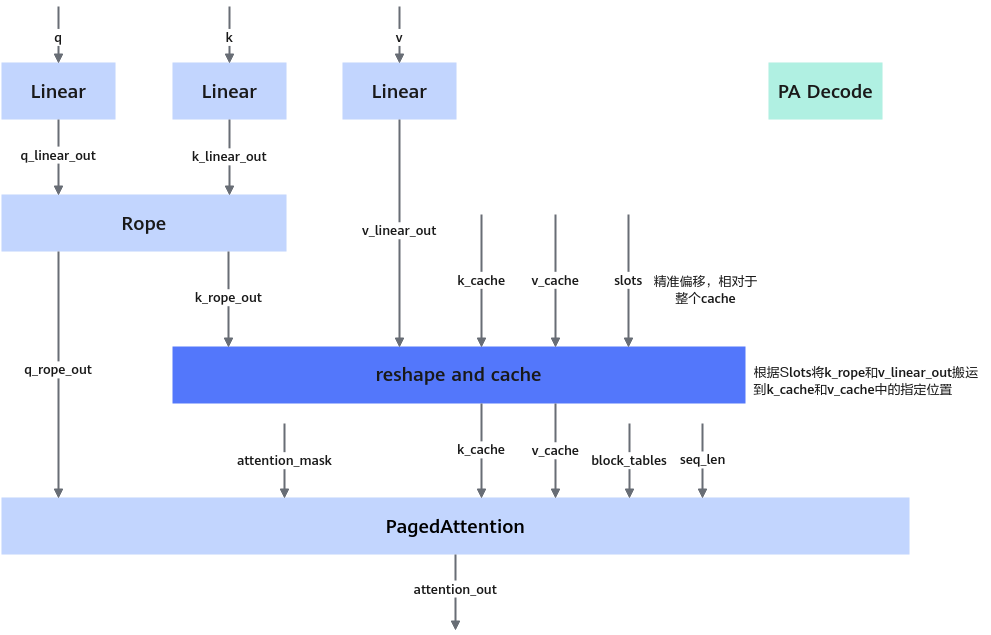
定义
struct ReshapeAndCacheOmniParam{
uint8_t rsv[8] = {0};
}
参数列表
成员名称 |
类型 |
默认值 |
取值范围 |
是否必选 |
描述 |
|---|---|---|---|---|---|
rsv[8] |
uint8_t |
{0} |
[0] |
否 |
预留参数。 |
Omni Head压缩功能
- 功能描述
- Omni Head:进行压缩,KV Cache只需要存储(First Sink Size+Recent Sink Size)个Token,不需要完整Seqlen个Token。
- Full Head:不进行压缩。
在模型中,特定的头采用omni压缩,对应使用本算子;其他头不压缩,使用原版ReshapeAndCache算子。
- 硬件支持情况
硬件型号
支持情况
特殊说明
Atlas 推理系列产品 不支持
-
Atlas 800I A2 推理产品 支持
-
- 输入
参数
维度
数据类型
格式
描述
key
[num_tokens, num_head, head_size]
float16/bf16
ND
待被cache的key。head_size需要为32的倍数。
value
[num_tokens, num_head, head_size]
float16/bf16
ND
待被cache的value。
key_cache
[num_blocks, block_size, 1, head_size
float16/bf16
ND
被压缩后的cache好的历次key。
value_cache
[num_blocks, block_size, 1, head_size]
float16/bf16
ND
被压缩后的cache好的历次value。
slot_mapping
[batch * num_head]
int32
ND
每个batch每个head的token key或value在cache中的存储偏移,即(block_id * block_size + offset_in_block);取值范围为[0, num_blocks * block_size),且不能存在重复值。
wins
[batch * num_head]
int32
ND
压缩量。wins[i] < seqLens[floor(i/num_head)],且wins内的值需要大于等于0,值为0时不压缩。
seqLen
[batch]
int32
ND
每个batch的实际seqLen,内部值都大于0。
offsetIndex
[batch * num_head]
int32
ND
每个batch每个head的压缩起点。取值范围为[-1, seqLens[floor(i/num_head)]-wins[i]];取值为-1时不进行压缩操作,wins的值无要求。
- 输出
参数
维度
数据类型
格式
描述
key_cache
[num_blocks, block_size, 1, head_size]
float16/bf16
ND
刷入key的key_cache。
value_cache
[num_blocks, block_size, 1, head_size]
float16/bf16
ND
刷入value的value_cache。
- 规格约束
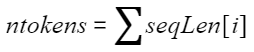
- batch * num_head<500
- head_size需要为32的倍数。
- key、value、keyCache、valueCache、keyCacheOut 、valueCacheOut的数据类型都必须完全一致。