图1 ReshapeAndCacheOperation算子上下文
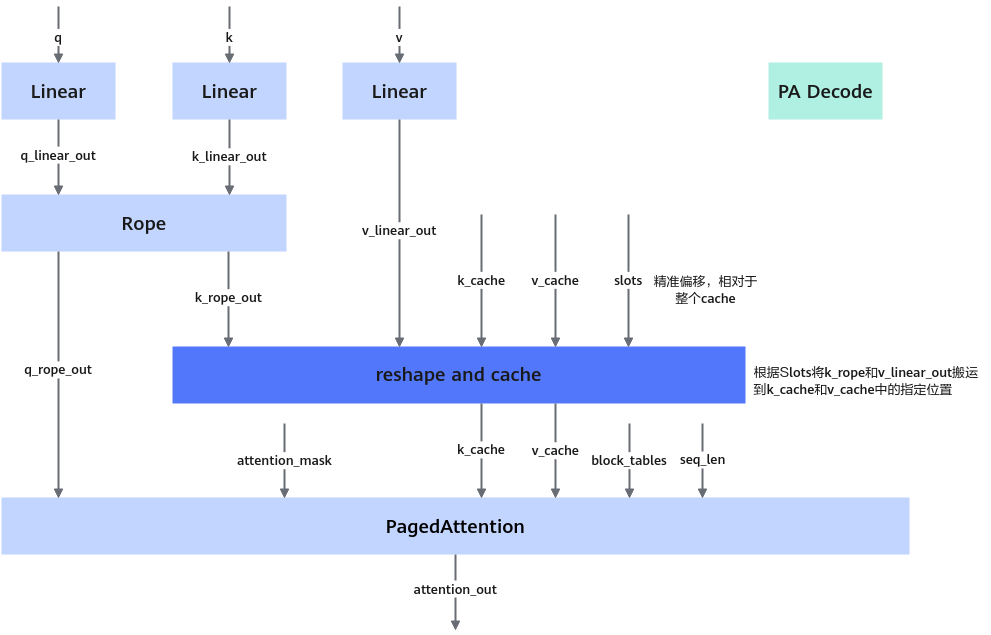
如上图所示,为典型rope场景下pa decoder layer的部分结构。ReshapeAndCache与paged attention配合使用,用于存储某layer上各个token的历史key和value。与加速库的KVCache算子不同,ReshapeAndCache算子只维护某一层的kvcache而非一个服务的全部kvcache。因此,若模型中有n个layer,使用ReshapeAndCache的情况下需要n个k_cache tensor与n个v_cache tensor管理历史kv。