功能
RelayAttention算法的核心创新点是通过将与系统提示对应的矩阵-向量乘法分组为矩阵-矩阵乘法,允许对于一批输入令牌从DRAM中仅读取一次系统提示的隐藏状态(键值对),从而消除现有因果注意力计算算法中处理系统提示时存在的大量冗余内存访问,在提高效率的同时保持生成质量且无需模型重新训练。
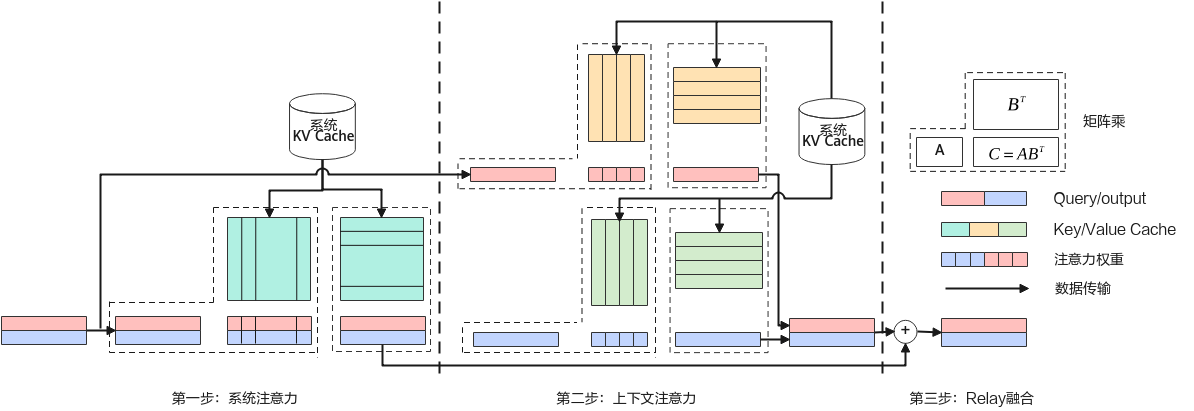
算子上下文
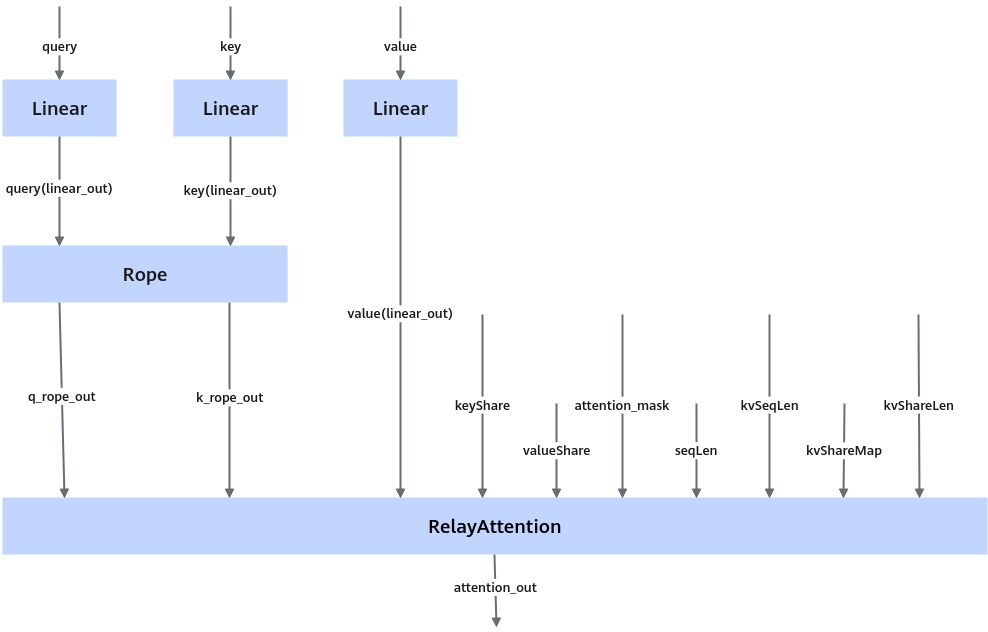
定义
1 2 3 4 5 6 7 8 9 10 11 | struct RelayAttentionParam { int32_t headNum = 0; float qkScale = 1; int32_t kvHeadNum = 0; enum MaskType : int { MASK_TYPE_UNDEFINED = 0, MASK_TYPE_NORM, }; MaskType maskType = MASK_TYPE_UNDEFINED; uint8_t rsv[32] = {0}; }; |
参数列表
成员名称 |
类型 |
默认值 |
描述 |
|---|---|---|---|
headNum |
int32_t |
0 |
head数量。headNum需要大于0。 |
qkscale |
float |
1.0 |
算子tor值。 |
kvHeadNum |
int32_t |
0 |
kvhead数量。取值范围为[0, 8 ]。 kvHeadNum取值分为两种情况:
|
maskType |
MaskType |
MASK_TYPE_UNDEFINED |
mask类型。 |
rsv[32] |
uint8_t |
{0} |
预留参数。 |
输入
参数 |
维度 |
数据类型 |
格式 |
CPU or NPU |
描述 |
|---|---|---|---|---|---|
query |
[B, qHiddenSize] |
float16/bf16 |
ND |
NPU |
query矩阵。 |
key |
[B, [S1, N, D]] [B, [S1, N*D]] |
float16/bf16 |
ND |
CPU |
不共享key矩阵,为TensorList,可选择是否合轴。 |
value |
[B, [S1, N, D]] [B, [S1, N*D]] |
float16/bf16 |
ND |
CPU |
不共享value矩阵,为TensorList,可选择是否合轴。 |
keyShare |
[BS, [S2, N, D]] [BS, [S2, N*D]] |
float16/bf16 |
ND |
CPU |
共享key矩阵,为TensorList,可选择是否合轴。 |
valueShare |
[BS, [S2, N, D]] [BS, [S2, N*D]] |
float16/bf16 |
ND |
CPU |
共享value矩阵,为TensorList,可选择是否合轴。 |
attentionMask |
- |
float16/bf16 |
ND |
NPU |
预留输入tensor。 |
seqLen |
[B] |
int32 |
ND |
CPU |
qseqlen list。 |
kvSeqLen |
[B] |
int32 |
ND |
CPU |
kvseqlen list。 |
kvShareMap |
[B] |
int32 |
ND |
CPU |
batch和共享组映射关系数组,无共享组时取值为-1。 |
kvShareLen |
[BS] |
int32 |
ND |
CPU |
共享组实际长度数组。 |
输出
参数 |
维度 |
数据类型 |
格式 |
CPU or NPU |
|---|---|---|---|---|
out |
[B, qHiddenSize] |
float16/bf16 |
ND |
NPU |
规格说明
- 仅支持
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 和Atlas A3 推理系列产品 /Atlas A3 训练系列产品 。 - 输入key、value、keyShare、valueShare为TensorList,这些输入tensor中B、BS为二级指针维度。以key为例,其为大小为[B]的list,里面存储B个指针,每个指针指向一个[S1, N ,D](或[S1, N *D])大小的tensor。
- B为batch,取值范围为(0, 60],BS为共享组个数,S1为不共享的长度,S2为共享长度,N为kvhead,D为head_size。
- CPU是指该输入tensor为HostTensor,传入算子时需要bind tensor,而NPU则为device tensor。
- key和value应同时选择合轴或者不合轴,keyShare和valueShare应同时选择合轴或者不合轴。即key和value维度相等,keyShare和valueShare维度相等。
- 数据类型同时支持float16/bf16的输入tensor,必须同时为float16或同时为bf16。
- maskType当前只支持MASK_TYPE_UNDEFINED,故attentionMask为预留接口,必须传入且仅限制其数据类型。