功能
将多个通信卡上的数据进行计算,支持相加、取最大、最小三种计算,然后不等地发送到每张卡上。
使用场景
推理场景中会出现batch size不能被TP数整除的情况,reducescatter后续的计算算子需要按照batch维度处理数据,再将处理数据进行allgather,如图图1所示。
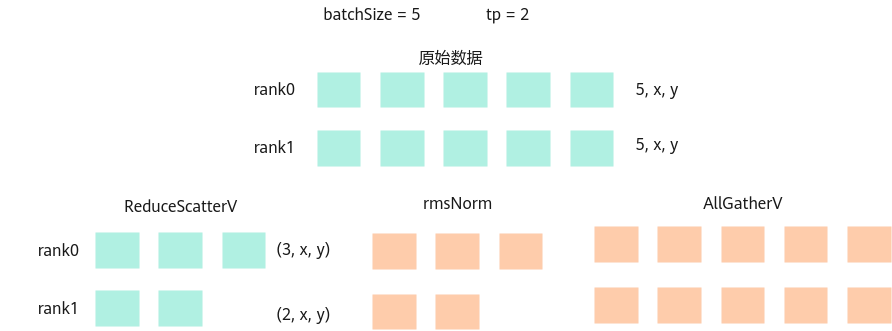
对于原始的ReduceScatter来说,要求在每张卡的数据一样多,对于ReduceScatterV来说,假设有5份数据,可以在一张卡上分三份,一张卡上分两份。
使用示例:
- 输入
[[[0], [1], [2], [3], [4]], [[0], [1], [2], [3], [4]]] [[2, 3], [2, 3]] [[0, 2], [0, 2]] [2, 3]
- 输出
NPU0 的输出:
[[0], [2]]
NPU1 的输出:
[[4], [6], [8]]
定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | struct ReduceScatterVParam { int rank = 0; int rankSize = 0; int rankRoot = 0; std::vector<int64_t> sendCounts; std::vector<int64_t> sdispls; std::int64_t recvCount = 0; std::string reduceType = "sum"; HcclComm hcclComm = nullptr; CommMode commMode = COMM_MULTI_PROCESS; std::string backend = "hccl"; std::string rankTableFile; std::string commDomain; uint8_t rsv[64] = {0}; }; |
参数列表
成员名称 |
类型 |
默认值 |
取值范围 |
是否必选 |
描述 |
|---|---|---|---|---|---|
rank |
int |
0 |
[0, rankSize-1] |
是 |
当前卡所属通信编号。 |
rankSize |
int |
0 |
- |
是 |
通信的卡的数量。 |
rankRoot |
int |
0 |
[0, rankSize-1] |
是 |
主通信编号。 |
reduceType |
string |
"sum" |
sum prod max min |
是 |
通信计算类型。 支持“sum”(相加),“prod”(相乘),“max”(取最大)和“min”(取最小)。 |
backend |
string |
“hccl” |
lccl/hccl |
是 |
通信计算类型,仅支持“hccl”和“lccl”。
|
hcclComm |
HcclComm |
nullptr |
- |
否 |
HCCL通信域指针。当前算子仅支持lccl,此参数为预留参数。默认为空,加速库为用户创建;若用户想要自己管理通信域,则需要传入该通信域指针,加速库使用传入的通信域指针来执行通信算子。 |
commMode |
CommMode |
COMM_MULTI_PROCESS |
COMM_MULTI_PROCESS/COMM_MULTI_THREAD |
否 |
通信模式,CommMode类型枚举值。 |
rankTableFile |
string |
无 |
- |
否 |
集群信息的配置文件路径。 |
commDomain |
string |
无 |
- |
否 |
通信device组用通信域名标识。 |
rsv[64] |
uint8_t |
{0} |
[0] |
否 |
预留参数。 |
输入
参数 |
维度 |
数据类型 |
格式 |
是否必选 |
描述 |
|---|---|---|---|---|---|
x |
[dim_0, dim_1] |
"hccl": float16/int8 |
ND |
是 |
输入tensor,dim_0,dim_1大小没有限制。 |
sendCounts |
[rankSize] |
int64 |
ND |
是 |
一维张量,其长度等于ranksize卡数,张量里的每个索引的值代表着每张卡分配的数据量,例如sendCounts[0]:rank0分配的数据量。张量中值的和等于x的dim_0。 |
sdispls |
[rankSize] |
int64 |
ND |
是 |
一维张量 ,其长度等于ranksize卡数,张量里的每个索引的值代表着从对应索引卡号接收到的数据量的偏移,sdispls [0] = n表示rank0从相对于输入起始位置的偏移量为n的位置开始接收sendCounts[0]的数据量。张量中的值需小于x的dim_0。 |
recvCount |
[1] |
int64 |
ND |
是 |
一维张量,该维度大小就是该固定1,recvCount 代表着该卡接收到的数据量。数值与sendCounts保持一致。 |
y |
[dim_0] |
float16 |
ND |
是 |
一维张量,该张量用来推导output的shape。数值与recvCount相等。 |
输出
参数 |
维度 |
数据类型 |
格式 |
是否必选 |
描述 |
|---|---|---|---|---|---|
output |
[dim_0, dim_1] |
"hccl": float16/int8 |
ND |
是 |
输出tensor,dim_0为y的shape。dim_0等于recvCount.shape[rank],dim_1等于x.shape[1]。 |
规格约束
- rank、rankSize、rankRoot需满足以下条件。
- 0 ≤ rank < rankSize
- 0 ≤ rankRoot < rankSize
- 算子不支持
Atlas A3 推理系列产品 /Atlas A3 训练系列产品 。
接口调用示例(python)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | def main_worker(rank, world_size,inTensorDtypes, sizes, random_seed): # init process group torch_npu.npu.set_device(rank) print(f'Process {rank} started, using device npu:{rank}.') # init reduce_scatterv_operation op_name = "ReduceScatterVOperation" reduce_scatterv_operation = torch.classes.OperationTorch.OperationTorch( "ReduceScatterVOperation") torch.manual_seed(random_seed) low = -100 high = 100 for inTensorDtype in inTensorDtypes: inTensors=[torch.tensor([[0],[1],[2],[3],[4]],dtype=inTensorDtype),torch.tensor([[0],[1],[2],[3],[4]],dtype=inTensorDtype)] # y用来推导outputshape,ranksize为几长度就为几 if rank == 0: y = torch.tensor([0, 1], dtype=inTensorDtype) else: y = torch.tensor([0,1,2], dtype=inTensorDtype) GoldenTensors=[torch.tensor([[0],[2]],dtype=inTensorDtype),torch.tensor([[4],[6],[8]],dtype=inTensorDtype)] acl_param = json.dumps({"rank": rank, "rankSize": world_size, "sendCounts":sendcount[rank], "sdispls":senddisp[rank], "recvCount":recvout[rank], "rankRoot": 0, "backend": "hccl"}) run_param = json.dumps({"sendCounts":sendcount[rank],"sdispls":senddisp[rank],"recvCount":recvout[rank]}) host_list = [sendcount[rank],senddisp[rank],[recvout[rank]]] host_tensors = [np.array(tensor) for tensor in host_list] host_tensors = [torch.from_numpy(tensor).to(torch.int64) for tensor in host_tensors] host_tensors = [tensor.npu() for tensor in host_tensors] reduce_scatterv_operation.set_param(acl_param) reduce_scatterv_operation.set_varaintpack_param(run_param) acl_out_tensor = reduce_scatterv_operation.execute([inTensors[rank].npu(),host_tensors[0],host_tensors[1],host_tensors[2], y.npu()])[0] print(f'acl_outtensor:{acl_out_tensor}') torch.npu.synchronize() # assert result assert golden_compare(acl_out_tensor.cpu(), GoldenTensors[rank]) class reduce_scatterv_operationTest(operation_test.OperationTest): def test_reduce_scatterv_operation(self): world_size = 2 random_seed = 123 inTensorDtypes = [torch.float16] sizes = [[3,4]] |