功能
针对Qwen长序列场景,使用LogN缩放注意力。
其公式为:
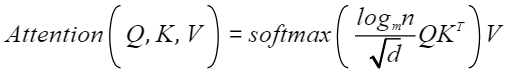
其中:m为训练长度,n为预测长度。
开启方式
将参数“scaleType置”为infer::PagedAttentionParam::SCALE_TYPE_LOGN时即可使用LogN缩放。
使用LogN缩放时,PagedAttentionOperation 新增一个 输入tensor 名为 logN,其具体规格如下:
名字 |
维度 |
数据类型 |
格式 |
cpu or npu |
|---|---|---|---|---|
logN |
增量阶段: [batch size] |
ND |
NPU |
其它输入tensor没有变化。
特殊约束
无