功能
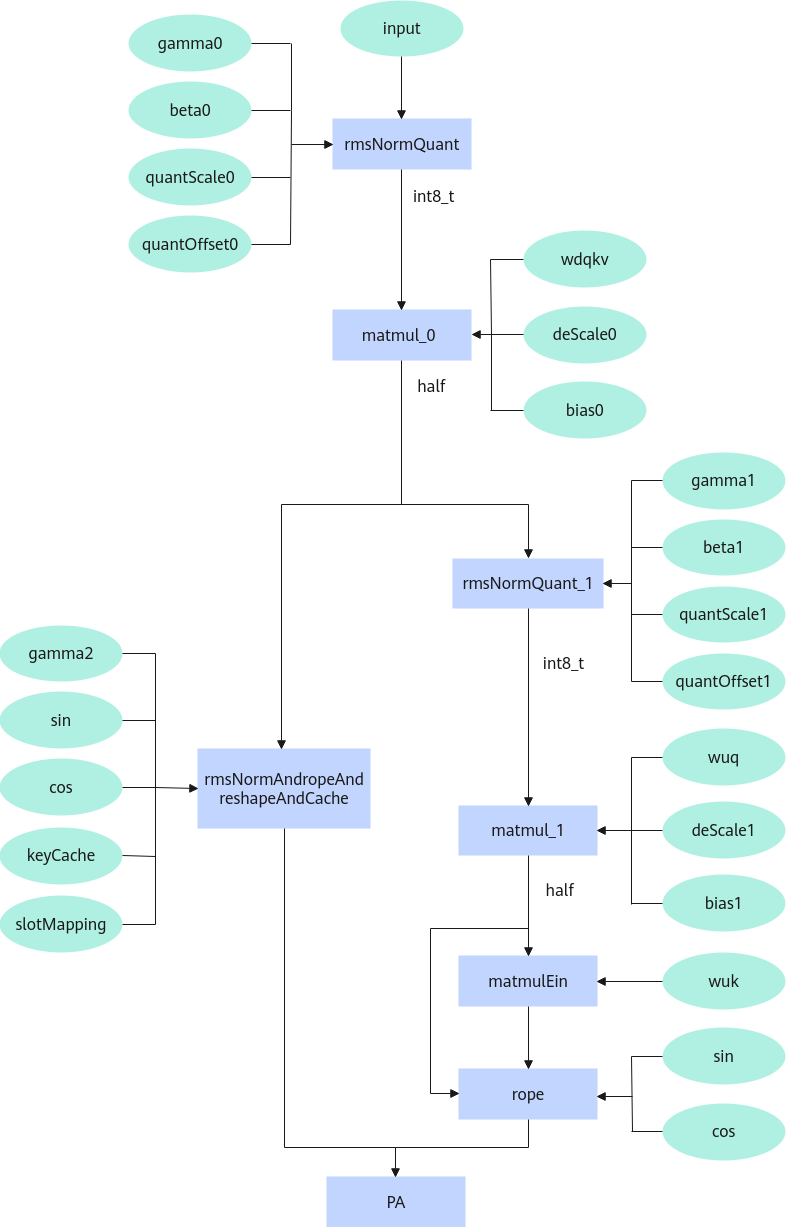
融合了MLA场景下PagedAttention输入数据处理的全过程,包括从隐状态输入开始经过rmsnorm、反量化、matmul、rope、reshapeAndCache的一系列计算。
硬件支持情况
硬件型号 |
支持情况 |
|---|---|
不支持 |
|
支持 |
|
支持 |
定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | struct MlaPreprocessParam{ uint32_t wdqDim = 0; uint32_t qRopeDim = 0; uint32_t kRopeDim = 0; float epsilon = 1e-5; int32_t qRotaryCoeff = 2; int32_t kRotaryCoeff = 2; bool transposeWdq = true; bool transposeWuq = true; bool transposeWuk = true; enum CacheMode : uint8_t { KVCACHE = 0, KROPE_CTKV, INT8_NZCACHE, NZCACHE, }; CacheMode cacheMode = KVCACHE; enum QuantMode : uint16_t { PER_TENSOR_QUANT_ASYMM = 0, PER_TOKEN_QUANT_SYMM, PER_TOKEN_QUANT_ASYMM, UNQUANT, }; QuantMode quantMode = PER_TENSOR_QUANT_ASYMM; uint8_t rsv[34] = {0}; }; |
参数列表
成员名称 |
类型 |
默认值 |
取值范围 |
是否必选 |
描述 |
|---|---|---|---|---|---|
wdqDim |
uint32_t |
0 |
[0] |
否 |
经过matmul后拆分的dim大小。 |
qRopeDim |
uint32_t |
0 |
[0] |
否 |
q传入rope的dim大小。 |
kRopeDim |
uint32_t |
0 |
[0] |
否 |
k传入rope的dim大小。 |
epsilon |
float |
1e-5 |
[1e-5] |
否 |
加在分母上防止除0。 |
qRotaryCoeff |
int32_t |
2 |
2 |
否 |
q旋转系数。 |
kRotaryCoeff |
int32_t |
2 |
2 |
否 |
k旋转系数。 |
transposeWdq |
bool |
true |
(true) |
否 |
wdq是否转置。 |
transposeWuq |
bool |
true |
(true) |
否 |
wuq是否转置。 |
transposeWuk |
bool |
true |
(true) |
否 |
wuk是否转置。 |
cacheMode |
CacheMode |
0 |
[0,3] |
否 |
指定cache的类型。 |
quantMode |
QuantMode |
0 |
[0,3] |
否 |
指定RmsNorm量化的类型。 |
rsv[34] |
uint8_t |
{0} |
[0] |
否 |
预留字段。 |
当前只有cacheMode生效。 |
|||||
上表中类型为自定义类型的,其描述如下:
cacheMode:表示输入query和kcache的类型,其具体取值如下。
- cacheMode为0时,kcache和q均经过拼接后输出。
- cacheMode为1时,输入输出的kvCcache拆分为krope和ctkv,q拆分为qrope和qnope。
- cacheMode为2时,krope和ctkv转为NZ格式输出,ctkv和qnope经过per_head静态对称量化为int8类型。
- cacheMode为3时,krope和ctkv转为NZ格式输出。
quantMode:表示RmsNorm量化类型,其具体取值如下。
- PER_TENSOR_QUANT_ASYMM:per_tensor静态非对称量化,默认量化类型。
- PER_TOKEN_QUANT_SYMM:per_token动态对称量化,未实现。
- PER_TOKEN_QUANT_ASYMM:per_token动态非对称量化,未实现。
- UNQUANT:不量化,浮点输出,未实现。
输入
所属模块功能 |
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|---|
rmsNormQuant_0 |
input |
[tokenNum, 7168] |
float16/bf16 |
ND |
必选。 |
gamma0 |
[7168] |
float16/bf16 |
ND |
必选。数据类型与input一致。 |
|
beta0 |
[7168] |
float16/bf16 |
ND |
必选。数据类型与input一致。 |
|
quantScale0 |
[1] |
float16/bf16 |
ND |
必选,支持传入空tensor。仅在quantMode为0时传入,数据类型与input一致。 |
|
quantOffset0 |
[1] |
int8 |
ND |
必选,支持传入空tensor。仅在quantMode为0时传入。 |
|
matmul_0 |
wdqkv |
[2112,7168] |
int8 |
NZ |
必选。 |
deScale0 |
[2112] |
int64/float |
ND |
必选。input为float16时为int64,input为bf16时为float。 |
|
bias0 |
[2112] |
int32 |
ND |
必选,支持传入空tensor。quantMode为1、3时不传入。 |
|
rmsNormQuant_1 |
gamma1 |
[1536] |
float16/bf16 |
ND |
必选。数据类型与input一致。 |
beta1 |
[1536] |
float16/bf16 |
ND |
必选。数据类型与input一致。 |
|
quantScale1 |
[1] |
float16/bf16 |
ND |
必选,支持传入空tensor。仅在quantMode为0时传入,数据类型与input一致。 |
|
quantOffset1 |
[1] |
int8 |
ND |
必选,支持传入空tensor。仅在quantMode为0时传入。 |
|
matmul_1 |
wuq |
[headNum * 192, 1536] |
int8 |
NZ |
必选。 |
deScale1 |
[headNum * 192] |
int64/float |
ND |
必选,input为float16时为int64,input为bf16时为float。 |
|
bias1 |
[headNum * 192] |
int32 |
ND |
必选,支持传入空tensor。quantMode为1、3时不传入。 |
|
rmsNorm |
gamma2 |
[512] |
float16/bf16 |
ND |
必选。数据类型与input一致。 |
rope |
cos |
[tokenNum,64] |
float16/bf16 |
ND |
必选。数据类型与input一致。 |
sin |
[tokenNum,64] |
float16/bf16 |
ND |
必选。数据类型与input一致。 |
|
matmulEin |
wuk |
ND:[headNum,128,512] NZ:[headNum,32,128,16] |
float16/bf16 |
ND/NZ |
必选。数据类型与input一致。 |
reshapeAndCache |
kvCache |
float16/bf16/int8 |
ND/NZ |
必选。数据类型与input一致。
|
|
kvCacheRope |
float16/bf16 |
ND/NZ |
必选,支持传入空tensor。
|
||
slotmapping |
[tokenNum] |
int32 |
ND |
必选。 |
|
quant |
ctkvScale |
[1] |
float16/bf16 |
ND |
必选,支持传入空tensor。cacheMode为2时传入,数据类型与input一致。 |
qNopeScale |
[headNum] |
float16/bf16 |
ND |
必选,支持传入空tensor。cacheMode为2时传入,数据类型与input一致。 |
输出
可选输出tensor不能使用空tensor占位。
所属模块功能 |
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|---|
输出数据 |
qOut0 |
float16/bf16/int8 |
ND |
输出tensor。数据类型与input一致。 cacheMode为2时数据类型为int8。 |
|
kvCacheOut0 |
float16/bf16/int8 |
ND/NZ |
输出tensor。数据类型与input一致。
|
||
qOut1 |
[tokenNum,headNum,64] |
float16/bf16 |
ND |
cacheMode不为0时输出此tensor。数据类型与input一致。 |
|
kvCacheOut1 |
float16/bf16 |
ND/NZ |
cacheMode不为0时输出此tensor。数据类型与input一致。
|
规格约束
- tokenNum<=1024。
- blockSize <= 128 或 blockSize = 256。
- cacheMode为2或3时,blockSize = 128。