功能概述
矩阵乘matmul与add融合,该功能类似功能1中的叠加偏置,性能较优。
计算公式
矩阵乘输入两个张量A(x)和B(weight),偏置矩阵为bias,输出张量为C:
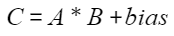
硬件支持情况
|
硬件型号 |
支持情况 |
说明 |
|---|---|---|
|
|
支持 |
不支持输入输出tensor数据类型为bf16的场景。 |
|
|
不支持 |
- |
|
|
支持 |
- |
|
|
支持 |
- |
参数配置
|
成员名称 |
取值范围 |
特殊说明 |
|---|---|---|
|
transposeA |
false/true |
取值为true时,不支持部分场景,详见规格说明。 |
|
transposeB |
false/true |
- |
|
hasBias |
true |
- |
|
outDataType |
ACL_DT_UNDEFINED |
- |
|
enAccum |
false |
- |
|
matmulType |
MATMUL_UNDEFINED |
- |
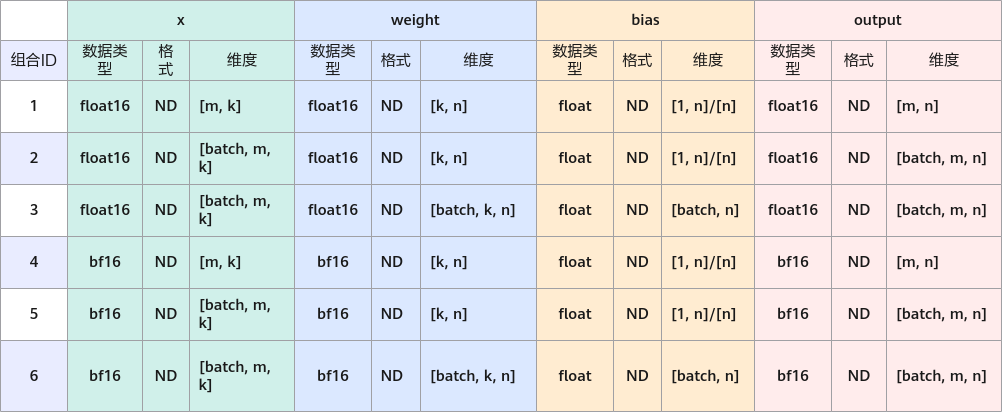
输入
|
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
|
x |
[m, k]/[batch, m, k] |
float16/bf16 |
ND |
矩阵乘的A矩阵。 |
|
weight |
[k, n]/[batch, k, n] |
float16/bf16 |
ND |
矩阵乘的B矩阵,权重。 |
|
bias |
[1, n]/[n]/[batch, n] |
float |
ND |
叠加的偏置矩阵。 |
输出
|
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
|
output |
[m, n]/[batch, m, n] |
float16/bf16 |
ND |
矩阵乘计算结果。 |
OP使用与典型场景
OP使用时,可参考算子使用指导中的使用流程部分,其中,单算子(OpsOperation)构造Operation参数的构造方法参考以下参数构造部分。
// 参数构造 atb::infer::LinearParam param; param.transposeA = false; param.transposeB = false; param.hasBias = true; param.outDataType = ACL_DT_UNDEFINED; param.enAccum = false; param.matmulType = MATMUL_UNDEFINED;
# 计算示例
>>> x
tensor([[1, 2],
[3, 4]])
>>> weight
tensor([[1, 2, 3],
[4, 5, 6]])
>>> bias
tensor([1, 2, 3])
>>> output
tensor([[10, 14, 18],
[20, 28, 36]])
# 10 = 1 * 1 + 2 * 4 + 1
# 14 = 1 * 2 + 2 * 5 + 2
# 18 = 1 * 3 + 2 * 6 + 3
# 20 = 3 * 1 + 4 * 4 + 1
# 28 = 3 * 2 + 4 * 5 + 2
# 36 = 3 * 3 + 4 * 6 + 3
功能约束
- “transposeA”为true时不支持部分场景。
- “hasBias”为true。
- “outDataType”为ACL_DT_UNDEFINED。
- “enAccum”为false。