功能
在MOE中,实现topK个专家权重与token激活值的乘法。
使用场景
UP:根据各个专家的权值,将token值分配给topK个专家。
DOWN:根据各个专家的权值,将topK个专家计算的结果重新整合。
计算过程
- UP
UP过程的计算公式如下:
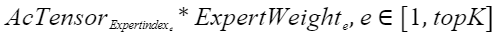
其中,AcTensor为激活token值,Expertindex为专家-token索引,ExpertWeight为专家权重,计算过程如下:
- 根据当前专家的索引
 ,从AcTensor中获取当前专家的激活token值。
,从AcTensor中获取当前专家的激活token值。 - 获取当前专家的权重,并与当前专家的激活token值做BatchMatmul。
- 根据当前专家的索引
- DOWN
DOWN过程的计算公式如下:
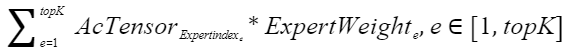
其中,AcTensor为激活token值,Expertindex为专家-token索引,ExpertWeight为专家权重,计算过程如下:
- 根据当前专家的索
 ,从AcTensor中获取当前专家的激活token值。
,从AcTensor中获取当前专家的激活token值。 - 获取当前专家的权重,并与当前专家的激活token值做BatchMatmul。
- 将当前token在所有专家上的结果相加。
- 根据当前专家的索
定义
1 2 3 4 5 6 7 8 9 10 11 |
struct GroupedMatmulWithRoutingParam { enum GroupedMatmulType : int { GROUPED_MATMUL_UP = 0, GROUPED_MATMUL_DOWN }; bool transposeB = true; int32_t topK = 0; GroupedMatmulType groupedMatmulType = GROUPED_MATMUL_UP; aclDataType outDataType = ACL_DT_UNDEFINED; uint8_t rsv[16] = {0}; }; |
参数列表
|
成员名称 |
类型 |
默认值 |
取值范围 |
是否必选 |
描述 |
|---|---|---|---|---|---|
|
groupedMatmulType |
GroupedMatmulType |
GROUP_MATMUL_UP |
|
必选 |
GroupedMatmulType类型参数:
|
|
transposeB |
bool |
true |
false/true |
非必选 |
是否转置 B 矩阵。 |
|
topK |
int32_t |
0 |
大于0 |
必选 |
选取 topK 个专家数量。 |
|
outDataType |
aclDataType |
ACL_DT_UNDEFINED |
|
反量化场景必选 |
|
|
rsv[16] |
uint8_t |
{0} |
[0] |
- |
预留参数。 |
输入输出
- UP
非量化场景
- 输入
参数
维度
数据类型
格式
描述
AcTensor
[num_tokens, hidden_size_in]
float16/bf16
ND
激活值。
ExpertWeight
[num_experts, hidden_size_in, hidden_size_out]
float16/bf16
ND
专家权重。如果设置“transposeB”为true,则hidden_size_in和hidden_size_out位置调换。
ExpertCount
[num_experts]
int32
ND
专家 Token 数量。
Expertindex
[num_tokens*topK]
int32
ND
专家 Token 索引。
- 输出
参数
维度
数据类型
格式
描述
Result
[num_tokens*Topk, hidden_size_out]
float16/bf16
ND
输出。
量化场景
- 输入
参数
维度
数据类型
格式
描述
AcTensor
[num_tokens, hidden_size_in]
int8
ND
激活值。
ExpertWeight
[num_experts, hidden_size_in, hidden_size_out]
int8
ND/NZ
专家权重。如果设置“transposeB”为true,则hidden_size_in和hidden_size_out位置调换。
ExpertCount
[num_experts]
int32
ND
专家 Token 数量。
Expertindex
[num_tokens*topK]
int32
ND
专家 Token 索引。
nscale
[num_experts, hidden_size_out]
float
ND
ExpertWeight方向反量化系数。
mscale
[num_tokens]
float
ND
AcTensor方向反量化系数。
- 输出
参数
维度
数据类型
格式
描述
Result
[num_tokens*Topk, hidden_size_out]
float16/bf16
ND
输出。
- 输入
- DOWN
非量化场景
- 输入
参数
维度
数据类型
格式
描述
AcTensor
[num_tokens*topK, hidden_size_in]
float16/bf16
ND
激活值。
ExpertWeight
[num_experts, hidden_size_in,hidden_size_out]
float16/bf16
ND
专家权重。如果设置“transposeB”为true,则hidden_size_in和hidden_size_out位置调换。
ExpertCount
[num_experts]
int32
ND
专家 Token 数量。
Expertindex
[num_tokens*topK]
int32
ND
专家 Token 索引。
- 输出
参数
维度
数据类型
格式
描述
Result
[num_tokens, hidden_size_out]
float16/bf16
ND
输出。
量化场景
- 输入
参数
维度
数据类型
格式
描述
AcTensor
[num_tokens*topK, hidden_size_in]
int8
ND
激活值。
ExpertWeight
[num_experts, hidden_size_in,hidden_size_out]
int8
ND/NZ
专家权重。如果设置“transposeB”为true,则hidden_size_in和hidden_size_out位置调换。
ExpertCount
[num_experts]
int32
ND
专家 Token 数量。
Expertindex
[num_tokens*topK]
int32
ND
专家 Token 索引。
nscale
[num_experts, hidden_size_out]
float
ND
ExpertWeight方向反量化系数。
mscale
[num_tokens*topK]
float
ND
AcTensor方向反量化系数。
- 输出
参数
维度
数据类型
格式
描述
Result
[num_tokens, hidden_size_out]
float16/bf16
ND
输出。
- 输入
规格约束
- 当选择输出类型量化 ,则输入必须为int8类型;当选择输出类型不量化 ,则输入必须为bf16或float16。
- topK的数量不能超过专家数量。
- 只支持
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 和Atlas A3 推理系列产品 /Atlas A3 训练系列产品 。 - nTokens取值范围[128, 512]。
- nExperts取值范围[128, 256]。
- topK取值范围[2, 10]。
- hiddenSizeIn在UP模式下的取值范围[32, 5120]且为32的整数倍,在DOWN模式下取值范围[32, 256]且为32的整数倍。
- hiddenSizeOut在UP模式下的取值范围[32, 256]且为32的整数倍,在DOWN模式下取值范围[32, 5120]且为32的整数倍。