功能
Sigmoid,Add,GroupTopk,Gather,ReduceSum,RealDiv,Muls算子的功能融合。
算子支持两种模式:常规模式(物理专家模式)、逻辑专家模式。
首先,每个专家经过sigmoid激活函数、Add偏置后,得出[bs, expert_num]的专家评分。其次每组经过DeepSeekV3的组级TOPK,专家级TOPK选出k个专家。
在常规模式下,这些专家作为物理专家的ID,会直接输出,用于指导后续的通信算子将每个token发往k个专家对应的卡上。
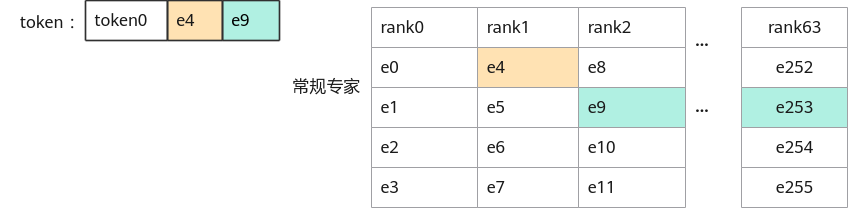
在存在冗余专家场景下,每个物理专家会属于不同的卡,此时衍生出逻辑专家的概念,即每个卡上的不同专家为逻辑专家,一个物理专家映射到多个逻辑专家,逻辑专家ID/每个卡的专家数=对应卡的RankID,逻辑专家ID%每个卡的专家数=在卡上的位置。
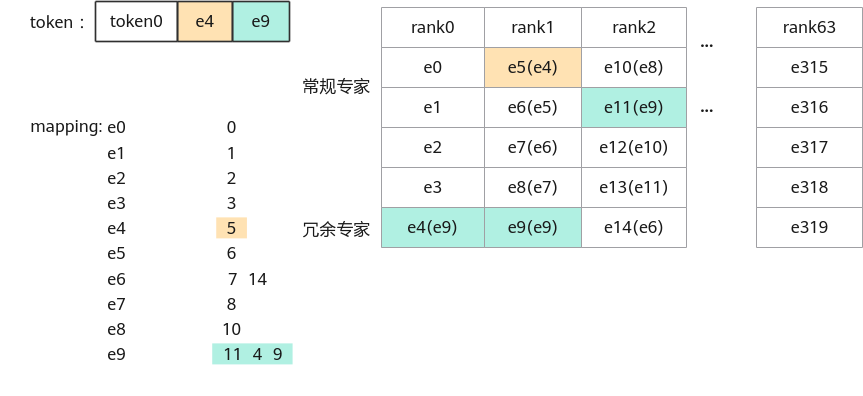
在逻辑专家模式下,新增mappingNum指示每个物理专家被映射到的逻辑专家数,新增mappingTable指示每个物理专家被映射到的逻辑专家ID,算子内使用伪随机逻辑,随机选择其中一个逻辑专家进行映射,并更正输出indices为逻辑专家ID。
硬件支持情况
硬件型号 |
支持情况 |
|---|---|
不支持 |
|
不支持 |
|
不支持 |
|
支持 |
|
支持 |
定义
struct FusedAddTopkDivParam {
uint32_t groupNum = 1;
uint32_t groupTopk = 1;
uint32_t n = 1;
uint32_t k = 0;
ActivationType activationType = ACTIVATION_SIGMOID;
bool isNorm = true;
float scale = 1.0f;
bool enableExpertMapping = false;
uint8_t rsv[27] = {0};
};
参数列表
成员名称 |
类型 |
默认值 |
取值范围 |
是否必选 |
描述 |
|---|---|---|---|---|---|
groupNum |
uint32_t |
1 |
>0 |
是 |
分组数量。 |
groupTopk |
uint32_t |
1 |
>0 |
是 |
选择k个组。 |
n |
uint32_t |
1 |
>0 |
是 |
组内选取n个最大值求和。 |
k |
uint32_t |
1 |
>0 |
是 |
topk选取前k个值。 |
activationType |
ActivationType |
ACTIVATION_SIGMOID |
ACTIVATION_SIGMOID |
是 |
激活类型。 |
isNorm |
bool |
true |
true/false |
是 |
是否归一化。 |
scale |
float |
1.0 |
- |
是 |
归一化后的乘系数。 |
enableExpertMapping |
bool |
false |
true/false |
是 |
是否使能物理专家向逻辑专家的映射。false时输入2个tensor,true时输入4个tensor。 |
rsv[27] |
uint8_t |
{0} |
所有值均为0 |
否 |
预留字段,用于保证版本间接口兼容性。 |
输入
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
x |
[a, b] |
float16/float32/bf16 |
ND |
输入tensor。 |
addNum |
[b] |
float16/float32/bf16 |
ND |
输入tensor,用于与x相加。数据类型和格式与x一致。 |
mappingNum |
[b] |
int32 |
ND |
enableExpertMapping为false时不启用,true时输入tensor,每个物理专家被实际映射到的逻辑专家数量。 |
mappingTable |
[b, c] c<=128 |
int32 |
ND |
enableExpertMapping为false时不启用,true时输入tensor,物理专家/逻辑专家映射表。 |
输出
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
y |
[a, k] |
float32 |
ND |
输出tensor。 |
indices |
[a, k] |
int32 |
ND |
输出tensor。 |
规格约束
- b为groupNum的整数倍。
- groupTopk <= groupNum。
- k <= b。
- b >= groupNum * n。
- b <= groupNum * 32。
- 若b >= 32,则groupNum = 8。
- max_redundant_expert_num代表最大可能出现的额冗余专家数,目前最大支持128。
- mapping_num里面的元素值: 0<=元素值<c。
- 含义:a=bs,b=expert_num,c= max_redundant_expert_num。