功能
向通信域内所有通信卡发送数据(数据量可以通过参数定制),并从所有通信卡接收数据(数据量可以通过参数定制)。
算子上下文
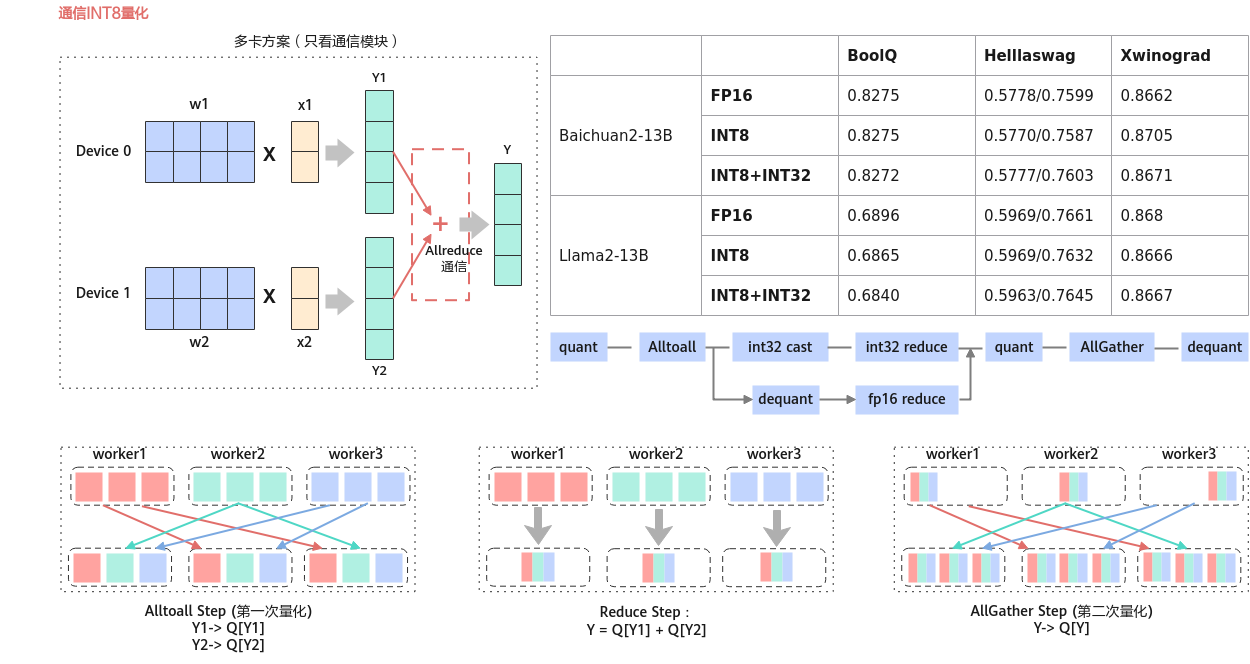
模型传输一个int8的量化输入tensor数据X,首先使用AlltoAll进行通信发送到各个节点上(这里使用int8进行通信,提升了通信速度)
然后使用reduce的sum操作对x进行求和,将int8数据反量化为float16, 最后使用AllGather进行通信将计算结果传输到各个节点上。(需求图中AllGather前后的量化,有可能会有精度损失,当前未实现。)
算子功能实现描述

1 2 3 4 5 |
# 计算goldTensor gold_outtensor = [] for j in range(len(recvout[rank])): gold_outtensor.append(tensorafters[j][senddisp[j][rank]:sendcount[j][rank] + senddisp[j][rank]]) gold_outtensor = [i for arr in gold_outtensor for i in arr] |
使用场景
用于将数据发送到各个节点上,多对多。AllToAll是对Allgather的扩展,相比于Allgather,AllToAll不同的节点从某一节点收集到的数据是不同的。
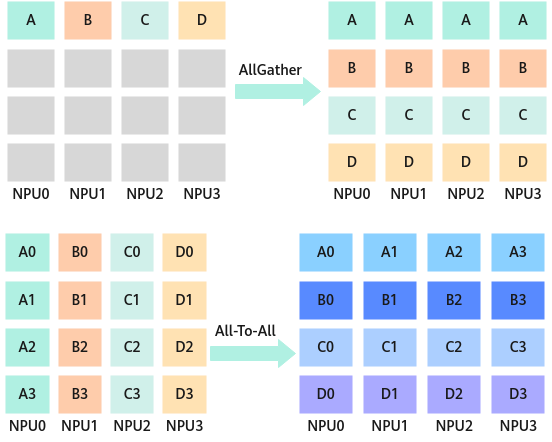
应用于模型并行;模型并行里的矩阵转置;数据并行到模型并行的矩阵转置。
使用示例:
>>> rank0 input
tensor([[0,1,2,3],
[4,5,6,7]], device='npu:0') shape[2,4]
>>> rank0 sendcount
tensor([2, 4], device='npu:0') shape[2]
>>> rank0 sdispls
tensor([0, 2])
>>> rank0 recvCounts
tensor([2, 2])
>>> rank0 rdispls
tensor([0, 2])
>>> rank0 tensorForInferShape
tensor([3, 3, 3, 3])
>>> rank1 input
tensor([[0, 1, 2],
[3, 4, 6]], device='npu:1') shape[2,3]
>>> rank1 sendcount
tensor([2, 1], device='npu:1') shape[2]
>>> rank1 sdispls
tensor([0, 2])
>>> rank1 recvCounts
tensor([4, 1])
>>> rank1 rdispls
tensor([0, 4])
>>> rank1 tensorForInferShape
tensor([3, 3, 3, 3, 3])
>>> rank0 output
tensor([[0, 1, 0, 1]], device='npu:0') shape[1,4]
>>> rank1 output
tensor([[2, 3, 4, 5, 2]], device='npu:1') shape[1,5]
定义
1 2 3 4 5 6 7 8 9 10 11 |
struct AllToAllVV2Param { int rank = -1; int rankSize = 0; int rankRoot = 0; std::string backend = "hccl"; HcclComm hcclComm = nullptr; CommMode commMode = COMM_MULTI_PROCESS; std::string rankTableFile; std::string commDomain; uint8_t rsv[64] = {0}; }; |
参数列表
|
成员名称 |
类型 |
默认值 |
描述 |
|---|---|---|---|
|
rank |
int32 |
-1 |
当前卡所属通信编号。 |
|
rankSize |
int32 |
0 |
通信的卡的数量,不能为0。 |
|
rankRoot |
int32 |
0 |
主通信编号。 |
|
backend |
std::string |
"hccl" |
通信计算类型,仅支持"hccl"。 |
|
hcclComm |
HcclComm |
nullptr |
hccl通信域接口获取的地址指针。默认为空,加速库为用户创建;若用户想要自己管理通信域,则需要传入该通信域指针,加速库使用传入的通信域指针来执行通信算子。 |
|
commMode |
CommMode |
COMM_MULTI_PROCESS |
通信模式,CommMode类型枚举值。hccl多线程只支持外部传入通信域方式。 enum CommMode : int { COMM_UNDEFINED = -1, //!< 未定义 COMM_MULTI_PROCESS, //!< 指定多进程通信 COMM_MULTI_THREAD, //!< 指定多线程通信 }; |
|
rankTableFile |
std::string |
- |
集群信息的配置文件路径,用于多机通信场景,当前仅支持hccl后端场景。 集群信息的配置文件路径,适用单机以及多机通信场景,当前仅支持hccl后端场景,若单机配置了rankTable,则以ranktable来初始化通信域。 配置请参见《TensorFlow 1.15模型迁移指南》的“模型训练>执行分布式训练>准备ranktable资源配置文件”章节。 |
|
commDomain |
std::string |
- |
通信device组用通信域名标识,多通信域时使用,当前仅支持hccl。 |
|
rsv[64] |
uint8_t |
{0} |
预留参数。 |
输入
|
参数 |
维度 |
数据类型 |
格式 |
是否必选 |
描述 |
|---|---|---|---|---|---|
|
x |
[dim_0, dim_1, ..., dim_n] |
"hccl": float16/int8 |
ND |
是 |
输入tensor。 |
|
sendCount |
1[rankSize] |
int64 |
ND |
否 |
表示发送数据量的数组,为host侧tensor。 例如,若发送的数据类型为float16,sendCounts[i] = n 表示本rank发给rank_i n个float16数据。 |
|
sdispls |
1[rankSize] |
int64 |
ND |
否 |
表示发送偏移量的数组,为host侧tensor。sdispls[i] = n表示本rank从相对于输入起始位置的偏移量为n的位置开始发送数据给rank_i。 |
|
recvCounts |
1[rankSize] |
int64 |
ND |
否 |
表示接收数据量的数组,为host侧tensor。例如,若发送的数据类型为float16,recvCounts[i] = n 表示本rank从rank_i收到n个float16数据。 |
|
rdispls |
1[rankSize] |
int64 |
ND |
否 |
表示接收偏移量的数组,为host侧tensor。rdispls[i] = n表示本rank从相对于输入起始位置的偏移量为n的位置开始接收rank_i的数据。 |
|
tensorForInferShape |
[recvCountsSum] |
int8 |
ND |
否 |
shape为recvCounts的所有元素之和,用于infer shape。 |
输出
|
参数 |
维度 |
数据类型 |
格式 |
是否必选 |
描述 |
|---|---|---|---|---|---|
|
output |
[1,recvCountsSum] |
"hccl": float16/int8 |
ND |
否 |
输出tensor,最后一维的shape为参数recvCounts的所有元素之和。数据类型和输入相同。 |
规格约束
- 多卡场景要指定rank。
- sendCounts、recvCounts、sdispls、rdispls均可看作长度为ranksize的一维数组,且数组中元素值都大于等于0。
- 仅支持
Atlas 推理系列产品 和Atlas 800I A2 推理产品 。 - sendCounts、recvCounts数组元素之和不能溢出int64,对于rdispls中的任一元素,recvCounts[i] + rdispls[i] 不能大于recvCountsSum(即output的最后一维),对于sdispls中的任一元素,sendCounts[i] + sdispls[i]不能大于输入tensor的数据量。如输入tensor shape为[3, 4, 5],数据量为3*4*5 = 60,在进行AllToAllV时会被视为shape为[60]的tensor进行计算。
- rank、rankSize、rankRoot需满足以下条件。
- 0 ≤ rank < rankSize
- 0 ≤ rankRoot < rankSize

- 多用户使用时需要使用ATB_SHARE_MEMORY_NAME_SUFFIX环境变量(请参见Transformer加速库环境变量说明)进行共享内存的区分,以进行初始化信息同步。
- 当使用加速库的通信算子异常退出时,需要清空残留数据,避免影响之后的使用,命令参考如下:
rm -rf /dev/shm/sem.lccl* rm -rf /dev/shm/sem.hccl* ipcrm -a
接口调用示例(Python)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
def main_worker(rank, world_size,inTensorDtypes, sizes, random_seed): # init process group torch_npu.npu.set_device(int(rank)) print(f'========== Process {rank} started, using device npu:{rank}.==========') # init all_to_allvv2_operation op_name = "AllToAllVV2Operation" all_to_allvv2_operation = torch.classes.OperationTorch.OperationTorch( "AllToAllVV2Operation") torch.manual_seed(random_seed) low = -100 high = 100 for inTensorDtype in inTensorDtypes: inTensors=[torch.tensor([[0,1,2,3],[4,5,6,7]],dtype=inTensorDtype),torch.tensor([[0,1,2],[3,4,6]],dtype=inTensorDtype)] GoldenTensors=[torch.tensor([[0,1,0,1]],dtype=inTensorDtype),torch.tensor([2,3,4,5,2],dtype=inTensorDtype)] acl_param = json.dumps({"rank": rank, "rankSize": world_size,"rankRoot": 0, "backend": "hccl"}) run_param = json.dumps({"sendCounts": sendcount[rank], "sdispls": senddisp[rank], "recvCounts": recvout[rank], "rdispls": recvdis[rank]}) host_list = [sendcount[rank], senddisp[rank], recvout[rank], recvdis[rank]] host_tensors = [np.array(tensor) for tensor in host_list] host_tensors = [torch.from_numpy(tensor).to(torch.int64) for tensor in host_tensors] host_tensors = [tensor.npu() for tensor in host_tensors] all_to_allvv2_operation.set_param(acl_param) all_to_allvv2_operation.set_varaintpack_param(run_param) print(f"host_tensors={host_tensors}") print(f"inTensors[rank].npu()={inTensors[rank].npu()}") print(f"host_tensors[0]={host_tensors[0]}") print(f"host_tensors[1]={host_tensors[1]}") print(f"host_tensors[2]={host_tensors[2]}") print(f"host_tensors[3]={host_tensors[3]}") atb_input5 = compute_out_tensor_dim1(recvout[rank]) print(f"atb_input5 = {atb_input5}") result1 = all_to_allvv2_operation.execute( [inTensors[rank].npu(), host_tensors[0], host_tensors[1], host_tensors[2], host_tensors[3], atb_input5]) print(f"\n ==========\nresult1={result1}\n ==========\n") acl_out_tensor = result1[0] print(f"\n ==========\nacl_out_tensor={acl_out_tensor}\n ==========\n") torch.npu.synchronize() # assert result assert golden_compare(acl_out_tensor.cpu(), GoldenTensors[rank]) def test_all_to_allvv2_operation(self): world_size = 2 random_seed = 123 sizes = [[3, 4]] set_start_method('spawn', force=True) process_list = [] inTensorDtypes = [torch.int8, torch.int16, torch.int32, torch.int64, torch.float32, torch.float16, torch.bfloat16] for i in range(world_size): p = Process(target=main_worker,args=(i,world_size, inTensorDtypes, sizes, random_seed)) p.start() process_list.append(p) for i in process_list: p.join() |