功能
将多个通信卡上的数据进行计算,支持相加、取最大、最小、相乘四种计算,然后发送到每张卡上。
该算子涉及多卡相关操作,可根据实际需求配置HCCL相关环境变量,具体请参见《CANN 环境变量参考》中的“集合通信”章节。
使用场景
多对多。在所有节点上都执行相同的Reduce操作(相加、取最大、最小、相乘),将所有节点的数据规约运算得到的结果发送到所有的节点上(broadcast)。

应用场景:
- AllReduce里的 broadcast + reduce组合里的reduce操作。
- ReduceScatter组合里的 reduce操作。
- 分布式训练parameter server 参数服务器结构里的 master节点 broadcast 数据到worker节点,再从worker节点reduce数据回master节点里的reduce操作。
使用示例:
- 非量化场景 (rankSize=2):
- 场景1:allReduce sum
x=[-4,-50] output=[-8,-100]
npu1:
x=[-4,-50] output=[-8,-100]
- 场景2:allReduce max
x=[4,20] output=[10,50]
npu1:
x=[10,50] output=[10,50]
- 场景3:allReduce min
x=[3,100] output=[3,20]
npu1:
x=[3,20] output=[3,20]
- 场景4:allReduce prod
x=[-93,-48] output=[8649,2304]
npu1:
x=[-93,-48] output=[8649,2304]
- 场景1:allReduce sum
- 量化场景:allReduce sum时进行量化传输(rankSize=2):
- 量化计算公式:
- 场景1:QUANT_TYPE_PER_TENSOR 对整个张量进行量化。
x=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16] scale=[1] offset=[0] output=[2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32]
- 场景2:QUANT_TYPE_PER_CHANNEL 对张量中的每个channel分别进行量化。
x=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16] scale=[1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1] offset=[0] output=[2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32]
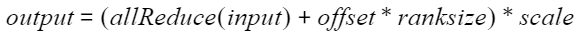
定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
struct AllReduceParam { enum QuantType : int { QUANT_TYPE_UNQUANT = 0, QUANT_TYPE_UNDEFINED = 0, QUANT_TYPE_PER_TENSOR = 1, QUANT_TYPE_PER_CHANNEL = 2, QUANT_TYPE_MAX = 3, }; int rank = 0; int rankSize = 0; int rankRoot = 0; std::string allReduceType = "sum"; std::string backend = "hccl"; HcclComm hcclComm = nullptr; CommMode commMode = COMM_MULTI_PROCESS; std::string rankTableFile; std::string commDomain; QuantType quantType = QUANT_TYPE_UNDEFINED; aclDataType outDataType = ACL_DT_UNDEFINED; uint8_t rsv[64] = {0}; }; |
参数列表
|
成员名称 |
类型 |
默认值 |
取值范围 |
是否必选 |
描述 |
|---|---|---|---|---|---|
|
rank |
int |
0 |
[0, rankSize-1] |
是 |
当前卡所属通信编号。 |
|
rankSize |
int |
0 |
- |
是 |
通信的卡的数量。 |
|
rankRoot |
int |
0 |
[0, rankSize-1] |
是 |
主通信编号。 |
|
allReduceType |
string |
"sum" |
sum prod max min |
是 |
通信计算类型。 支持“sum”(相加),“prod”(相乘),“max”(取最大)和“min”(取最小)。 |
|
backend |
string |
"hccl" |
lccl/hccl |
是 |
通信计算类型,仅支持“hccl”和“lccl”。
|
|
hcclComm |
HcclComm |
nullptr |
- |
否 |
HCCL通信域指针。 默认为空,加速库为用户创建;若用户想要自己管理通信域,则需要传入该通信域指针,加速库使用传入的通信域指针来执行通信算子。 |
|
commMode |
CommMode |
COMM_MULTI_PROCESS |
|
否 |
通信模式,CommMode类型枚举值。hccl多线程仅支持外部传入通信域方式。 |
|
rankTableFile |
string |
- |
- |
否 |
集群信息的配置文件路径,用于单机以及多机通信场景,当前仅支持HCCL后端场景。 若单机配置了ranktable,则以ranktable来初始化通信域。 配置请参见《TensorFlow 1.15模型迁移指南》的“模型训练>执行分布式训练>准备ranktable资源配置文件”章节。 |
|
commDomain |
string |
- |
- |
否 |
通信Device组用通信域名标识,多通信域时使用。当backend为"lccl"时,commMode为多进程时,commDomain需要设置为0-63的数字。commMode为多线程时,不支持确定性计算,"LCCL_DETERMINISTIC"需要为0或者false。 LCCL在多进程/多线程多通信域并发场景下,"LCCL_PARALLEL"需要设置为1或者true。多通信域并行功能使用结束后,"LCCL_PARALLEL"需要设置为0或者false,否则会导致基础场景性能下降。 |
|
quantType |
QuantType |
QUANT_TYPE_UNQUANT |
|
否 |
量化类型。 QUANT_TYPE_UNQUANT:默认值。 QUANT_TYPE_UNDEFINED:默认值。 QUANT_TYPE_PER_TENSOR:对整个张量进行量化。 QUANT_TYPE_PER_CHANNEL:对张量中每个channel分别进行量化。 QUANT_TYPE_MAX:枚举类型最大值。 |
|
outDataType |
aclDataType |
ACL_DT_UNDEFINED |
ACL_FLOAT16 |
否 |
|
|
rsv[64] |
uint8_t |
{0} |
[0] |
否 |
预留参数。 |
注:LCCL多通信域并行时,最大通信数据量不超过100MB,1MB以上性能下降。并发通信时,带宽共享,性能下降。LCCL多通信域并行功能和确定性计算功能不兼容,开启确定性计算后该功能失效。
函数输入输出描述
|
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
|
x |
[dim_0, dim_1, ..., dim_n] |
|
ND |
输入tensor。 |
|
output |
[dim_0, dim_1, ..., dim_n] |
|
ND |
输出tensor。 |
quantType为QUANT_PER_Tensor的输入输出描述
|
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
|
x |
[dim_0, dim_1, ..., dim_n] |
int8 |
ND |
输入tensor,最后一维n的大小是16的整数倍。 |
|
scale |
[1] |
float16 |
ND |
输入。scale中元素要求为标量。 |
|
offset |
[1] |
float16 |
ND |
输入。offset中元素要求为标量。 |
|
y |
[dim_0, dim_1, ..., dim_n] |
float16 |
ND |
量化输出结果;x和y的shape一致。 |
quantType为QUANT_PER_Channel的输入输出描述
|
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
|
x |
[dim_0, dim_1, ..., dim_n] |
int8 |
ND |
输入tensor,最后一维n的大小是16的整数倍。 |
|
scale |
[1, n] 或 [n] |
float16 |
ND |
输入。scale中元素要求不为0。最后一维n的大小是16的整数倍。 |
|
offset |
[1] |
float16 |
ND |
输入。offset中元素要求为标量。 |
|
y |
[dim_0, dim_1, ..., dim_n] |
float16 |
ND |
量化输出结果;x和y的shape一致。 |
规格约束
rank、rankSize、rankRoot需满足以下条件。
- 0 ≤ rank < rankSize
- 0 ≤ rankRoot < rankSize

- 多用户使用时需要使用ATB_SHARE_MEMORY_NAME_SUFFIX环境变量(请参见Transformer加速库环境变量说明)进行共享内存的区分,以进行初始化信息同步。
- 当使用加速库的通信算子异常退出时,需要清空残留数据,避免影响之后的使用,命令参考如下:
rm -rf /dev/shm/sem.lccl* rm -rf /dev/shm/sem.hccl* ipcrm -a
- 当前不支持单device上跑多个HCCP进程实例,不能单卡同时跑多个通信算子。比如运行通信算子场景下,不支持同一张卡上跑多个模型。
算子调用示例(C++)
前置条件和编译命令请参见算子调用示例。当前仅支持
场景:基础场景。
因为用例使用多线程,编译时要增加编译选项:
1
|
-l pthread
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 |
#include <iostream> #include <vector> #include <numeric> #include <string> #include <future> #include "acl/acl.h" #include "atb/operation.h" #include "atb/types.h" #include "atb/atb_infer.h" #include "demo_util.h" struct Args { int rankId; aclrtStream stream; atb::Context *context; atb::infer::AllReduceParam param; }; /** * @brief 准备atb::VariantPack中的所有tensor * @param args 线程参数结构体 * @return atb::VariantPack */ atb::VariantPack PrepareVariantPack(Args &args) { atb::VariantPack variantPack; std::vector<int64_t> shape = {2, 1024}; // 创建Host侧数据 std::vector<float> xHostData(shape[0] * shape[1], 2.0); std::vector<float> outputHostData(shape[0] * shape[1], 0); // 生成ATB tensor atb::Tensor tensorX = CreateTensorFromVector(args.context, args.stream, xHostData, ACL_FLOAT16, aclFormat::ACL_FORMAT_ND, shape); atb::Tensor tensorOutput = CreateTensorFromVector(args.context, args.stream, outputHostData, ACL_FLOAT16, aclFormat::ACL_FORMAT_ND, shape); // 根据顺序将所有输入tensor放入SVector variantPack.inTensors = {tensorX}; variantPack.outTensors = {tensorOutput}; return variantPack; } /** * @brief 创建一个AllReduce的Operation,并设置参数 * @return atb::Operation * 返回一个Operation指针 */ int RunAllReduceOp(Args &args) { int rankId = args.rankId; auto aclRet = aclrtSetDevice(rankId); CHECK_STATUS_EXPR(aclRet, std::cout << "aclrtSetDevice failed" << std::endl; return aclRet); atb::VariantPack variantPack = PrepareVariantPack(args); atb::Operation *allReduceOp = nullptr; atb::Status st = atb::CreateOperation(args.param, &allReduceOp); CHECK_STATUS_EXPR( (st != atb::ErrorType::NO_ERROR || !allReduceOp), std::cout << "atb create operation failed" << std::endl; return st); uint64_t workspaceSize = 0; // ATB Operation 第一阶段接口调用:对输入输出进行检查,并根据需要计算workspace大小 st = allReduceOp->Setup(variantPack, workspaceSize, args.context); CHECK_STATUS_EXPR(st, std::cout << "operation setup failed" << std::endl; return st); // 根据第一阶段接口计算出的workspaceSize申请device内存 uint8_t *workspacePtr = nullptr; if (workspaceSize > 0) { aclRet = aclrtMalloc((void **)(&workspacePtr), workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST); CHECK_STATUS_EXPR(aclRet, std::cout << "aclrtMalloc failed" << std::endl; return aclRet); } // ATB Operation 第二阶段接口调用:执行算子 st = allReduceOp->Execute(variantPack, workspacePtr, workspaceSize, args.context); CHECK_STATUS_EXPR(st, std::cout << "operation execute failed" << std::endl; return aclRet); // 同步等待 aclRet = aclrtSynchronizeStream(args.stream); CHECK_STATUS_EXPR(aclRet, std::cout << "aclrtSynchronizeStreame failed" << std::endl; return aclRet); // 资源释放 for (atb::Tensor &tensor : variantPack.inTensors) { if (tensor.deviceData) { aclrtFree(tensor.deviceData); } } for (atb::Tensor &tensor : variantPack.outTensors) { if (tensor.deviceData) { aclrtFree(tensor.deviceData); } } if (workspaceSize > 0 && workspacePtr != nullptr) { aclrtFree(workspacePtr); } st = atb::DestroyOperation(allReduceOp); CHECK_STATUS_EXPR(st, std::cout << "destroy operation failed" << std::endl; return st); aclRet = aclrtDestroyStream(args.stream); CHECK_STATUS_EXPR(aclRet, std::cout << "aclrtDestroyStream failed" << std::endl; return aclRet); st = atb::DestroyContext(args.context); CHECK_STATUS_EXPR(st, std::cout << "destroy context failed" << std::endl; return st); aclRet = aclrtResetDevice(args.rankId); CHECK_STATUS_EXPR(aclRet, std::cout << "aclrtResetDevice failed" << std::endl; return aclRet); return 0; } int main(int argc, char **argv) { // 设置通信设备数量 static const int DEV_NUM = 8; // 设置通信计算类型 static const std::string ALL_REDUCE_TYPE = "sum"; // 设置通信计算后端 static const std::string BACKEND = "lccl"; CHECK_STATUS(aclInit(nullptr)); Args args[DEV_NUM]; for (int rankId = 0; rankId < DEV_NUM; rankId++) { args[rankId].rankId = rankId; // 设置当前设备 CHECK_STATUS(aclrtSetDevice(rankId)); // 创建ATB Context CHECK_STATUS(atb::CreateContext(&(args[rankId].context))); // 创建流 CHECK_STATUS(aclrtCreateStream(&(args[rankId].stream))); args[rankId].context->SetExecuteStream(args[rankId].stream); // 配置AllReduce Param atb::infer::AllReduceParam ¶m = args[rankId].param; param.rank = rankId; param.rankSize = DEV_NUM; param.allReduceType = ALL_REDUCE_TYPE; param.backend = BACKEND; param.commMode = atb::infer::CommMode::COMM_MULTI_THREAD; param.commDomain = "domain0"; // 单通信域demo } // 启动多线程任务 std::vector<std::future<int>> threads(DEV_NUM); for (int rankId = 0; rankId < DEV_NUM; rankId++) { threads[rankId] = std::async(&RunAllReduceOp, std::ref(args[rankId])); } for (int rankId = 0; rankId < DEV_NUM; rankId++) { int aclRet = threads[rankId].get(); CHECK_STATUS_EXPR(aclRet, std::cout << "multithread task " << rankId << " failed" << std::endl); } CHECK_STATUS(aclFinalize()); std::cout << "AllReduce demo finished!" << std::endl; return 0; } |